FMPose3D: monocular 3D pose estimation via flow matching
作者: Ti Wang, Xiaohang Yu, Mackenzie Weygandt Mathis
分类: cs.CV
发布日期: 2026-02-05
🔗 代码/项目: GITHUB
💡 一句话要点
提出FMPose3D,利用Flow Matching高效解决单目3D姿态估计中的深度模糊性问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 单目3D姿态估计 Flow Matching 常微分方程 条件分布传输 后验期望聚合 人体姿态估计 动物姿态估计
📋 核心要点
- 单目3D姿态估计面临深度模糊和遮挡问题,现有方法计算成本高,难以高效生成多个合理的3D姿态假设。
- FMPose3D利用Flow Matching学习速度场,通过常微分方程高效生成3D姿态样本,并使用重投影后验期望聚合模块优化预测。
- 实验表明,FMPose3D在Human3.6M、MPI-INF-3DHP、Animal3D和CtrlAni3D等数据集上超越现有方法,达到SOTA性能。
📝 摘要(中文)
单目3D姿态估计由于深度模糊和遮挡而具有根本上的不适定性,因此需要生成多个合理的3D姿态假设的概率方法。扩散模型最近表现出强大的性能,但其迭代去噪过程通常需要许多时间步长才能进行每次预测,从而导致计算成本高昂。本文利用Flow Matching (FM)学习由常微分方程 (ODE) 定义的速度场,从而只需几个积分步骤即可高效生成3D姿态样本。提出了一种新的生成姿态估计框架FMPose3D,该框架将3D姿态估计公式化为条件分布传输问题,仅根据2D输入将样本从标准高斯先验连续传输到合理的3D姿态分布。虽然ODE轨迹是确定性的,但FMPose3D通过采样不同的噪声种子自然地生成各种姿态假设。为了从这些假设中获得单个准确的预测,进一步引入了基于重投影的后验期望聚合 (RPEA) 模块,该模块近似于3D假设上的贝叶斯后验期望。FMPose3D在广泛使用的人体姿态估计基准Human3.6M和MPI-INF-3DHP上超越了现有方法,并在3D动物姿态数据集Animal3D和CtrlAni3D上实现了最先进的性能,展示了在3D姿态领域中的强大性能。
🔬 方法详解
问题定义:单目3D姿态估计旨在从单张2D图像中恢复3D人体或动物姿态。由于深度信息的缺失和遮挡的存在,这是一个病态问题。现有的基于扩散模型的方法虽然性能优异,但需要大量的迭代去噪步骤,导致推理速度慢,计算成本高昂。
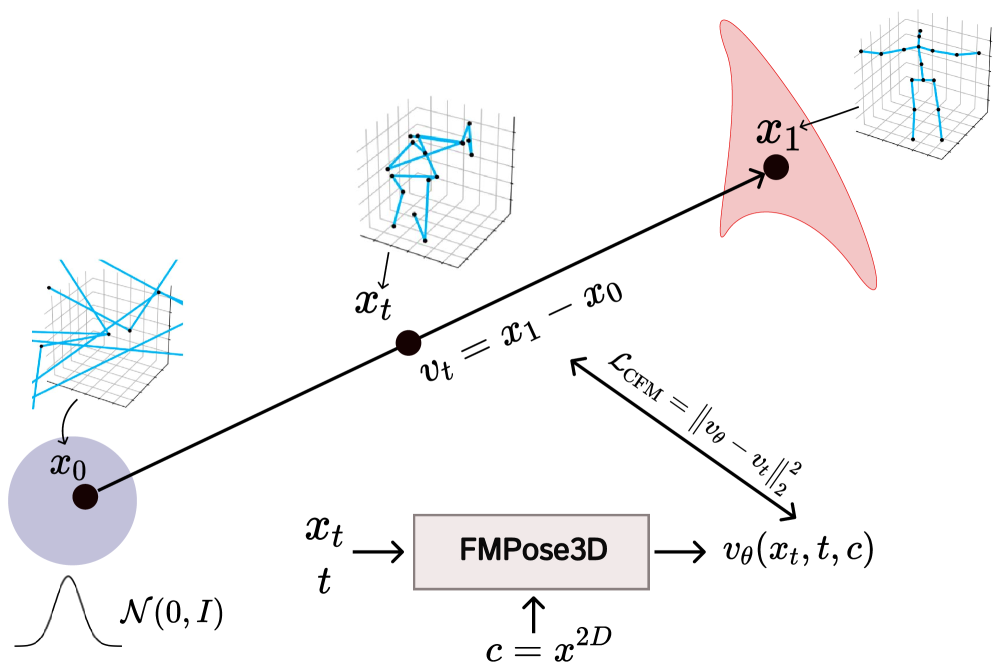
核心思路:FMPose3D的核心思路是将3D姿态估计问题转化为一个条件分布传输问题。通过学习一个由常微分方程(ODE)定义的速度场,将一个简单的先验分布(如高斯分布)映射到条件3D姿态分布。Flow Matching保证了学习到的速度场能够有效地将先验分布传输到目标分布,从而实现高效的3D姿态生成。
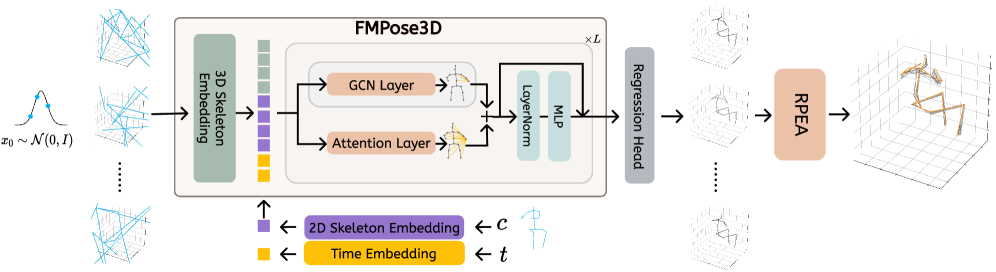
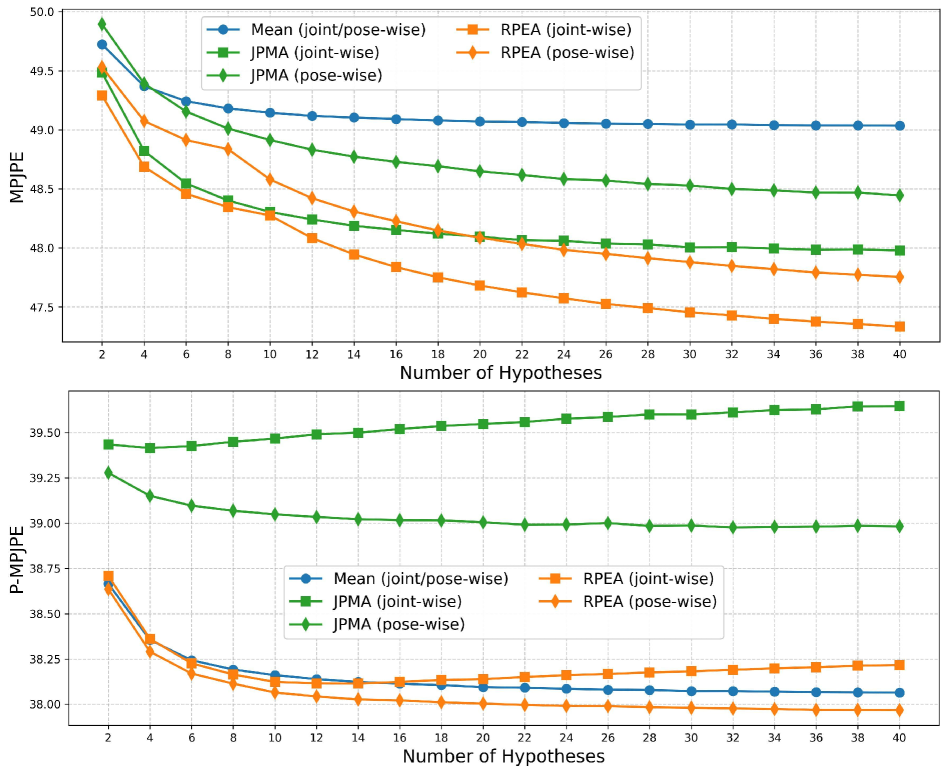
技术框架:FMPose3D框架主要包含两个阶段:1) 基于Flow Matching的3D姿态生成阶段:该阶段学习一个条件速度场,用于将高斯噪声转换为3D姿态样本。通过采样不同的噪声种子,可以生成多个可能的3D姿态假设。2) 基于重投影的后验期望聚合(RPEA)阶段:该阶段利用2D姿态信息,对生成的多个3D姿态假设进行加权平均,得到最终的3D姿态估计结果。RPEA模块通过最小化重投影误差来选择最佳的3D姿态。
关键创新:FMPose3D的关键创新在于将Flow Matching引入到单目3D姿态估计中,利用其高效的生成能力,克服了传统扩散模型推理速度慢的缺点。此外,RPEA模块通过结合2D信息,有效地提高了3D姿态估计的准确性。与现有方法相比,FMPose3D能够在保证精度的同时,显著提高推理速度。
关键设计:速度场的学习采用条件神经网络,输入为2D姿态信息和3D姿态样本。损失函数采用Flow Matching损失,用于约束速度场的学习。RPEA模块通过最小化重投影误差来计算每个3D姿态假设的权重。具体而言,重投影误差定义为3D姿态投影到2D图像上的关键点与真实2D关键点之间的距离。
🖼️ 关键图片
📊 实验亮点
FMPose3D在Human3.6M和MPI-INF-3DHP人体姿态估计数据集以及Animal3D和CtrlAni3D动物姿态估计数据集上均取得了state-of-the-art的结果。例如,在Human3.6M数据集上,FMPose3D的MPJPE指标优于现有方法,表明其在3D姿态估计精度方面具有显著优势。此外,FMPose3D的推理速度也明显快于基于扩散模型的方法。
🎯 应用场景
FMPose3D在人体和动物姿态估计方面具有广泛的应用前景,例如运动捕捉、人机交互、虚拟现实、动画制作、生物力学分析、动物行为研究等。该方法能够高效准确地估计3D姿态,为相关应用提供可靠的数据支持,并有望推动这些领域的发展。
📄 摘要(原文)
Monocular 3D pose estimation is fundamentally ill-posed due to depth ambiguity and occlusions, thereby motivating probabilistic methods that generate multiple plausible 3D pose hypotheses. In particular, diffusion-based models have recently demonstrated strong performance, but their iterative denoising process typically requires many timesteps for each prediction, making inference computationally expensive. In contrast, we leverage Flow Matching (FM) to learn a velocity field defined by an Ordinary Differential Equation (ODE), enabling efficient generation of 3D pose samples with only a few integration steps. We propose a novel generative pose estimation framework, FMPose3D, that formulates 3D pose estimation as a conditional distribution transport problem. It continuously transports samples from a standard Gaussian prior to the distribution of plausible 3D poses conditioned only on 2D inputs. Although ODE trajectories are deterministic, FMPose3D naturally generates various pose hypotheses by sampling different noise seeds. To obtain a single accurate prediction from those hypotheses, we further introduce a Reprojection-based Posterior Expectation Aggregation (RPEA) module, which approximates the Bayesian posterior expectation over 3D hypotheses. FMPose3D surpasses existing methods on the widely used human pose estimation benchmarks Human3.6M and MPI-INF-3DHP, and further achieves state-of-the-art performance on the 3D animal pose datasets Animal3D and CtrlAni3D, demonstrating strong performance across both 3D pose domains. The code is available at https://github.com/AdaptiveMotorControlLab/FMPose3D.