ShapeUP: Scalable Image-Conditioned 3D Editing
作者: Inbar Gat, Dana Cohen-Bar, Guy Levy, Elad Richardson, Daniel Cohen-Or
分类: cs.CV, cs.GR
发布日期: 2026-02-05
💡 一句话要点
ShapeUP:可扩展的图像条件3D编辑框架,实现精细可控的3D内容创作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D编辑 图像条件生成 扩散模型 3D扩散Transformer 潜在空间转换
📋 核心要点
- 现有3D编辑方法在视觉控制、几何一致性和可扩展性之间难以平衡,优化方法慢,多视图方法易漂移,无训练方法受限于预训练先验。
- ShapeUP将3D编辑视为在3D原生表示中的监督潜在空间转换问题,利用预训练3D基础模型的先验知识,并通过监督学习进行编辑适配。
- ShapeUP使用3D扩散Transformer学习图像到3D形状的直接映射,实现细粒度视觉控制和无掩码定位,实验表明其在身份保持和编辑保真度上优于现有方法。
📝 摘要(中文)
3D基础模型的最新进展使得生成高保真资产成为可能,但精确的3D操作仍然是一个重大挑战。现有的3D编辑框架通常面临视觉可控性、几何一致性和可扩展性之间的艰难权衡。具体而言,基于优化的方法速度慢,多视图2D传播技术存在视觉漂移,无训练的潜在空间操作方法本质上受限于冻结的先验,无法直接受益于扩展。本文提出了ShapeUP,一个可扩展的、图像条件的3D编辑框架,它将编辑公式化为原生3D表示中的监督潜在到潜在的转换。这种公式允许ShapeUP建立在预训练的3D基础模型之上,利用其强大的生成先验,同时通过监督训练使其适应编辑。在实践中,ShapeUP在由源3D形状、编辑后的2D图像和相应的编辑后的3D形状组成的三元组上进行训练,并使用3D扩散Transformer(DiT)学习直接映射。这种图像即提示的方法能够对局部和全局编辑进行细粒度的视觉控制,并实现隐式的、无掩码的定位,同时保持与原始资产的严格结构一致性。大量的评估表明,ShapeUP在身份保持和编辑保真度方面始终优于当前已训练和未训练的基线,为原生3D内容创建提供了一个强大且可扩展的范例。
🔬 方法详解
问题定义:论文旨在解决3D编辑中视觉可控性、几何一致性和可扩展性难以兼顾的问题。现有方法,如基于优化的方法计算成本高昂,多视图传播方法容易产生视觉漂移,而无训练的潜在空间操作方法则受限于预训练模型的先验知识,无法充分利用大规模数据带来的优势。
核心思路:ShapeUP的核心思路是将3D编辑问题转化为一个监督学习问题,即学习一个从源3D形状和编辑后的2D图像到目标3D形状的映射。通过利用预训练的3D基础模型作为先验,并使用监督学习进行微调,ShapeUP能够在保持几何一致性的同时,实现对3D形状的精确视觉控制。这种方法避免了优化过程,提高了编辑速度,并且能够受益于大规模数据的训练。
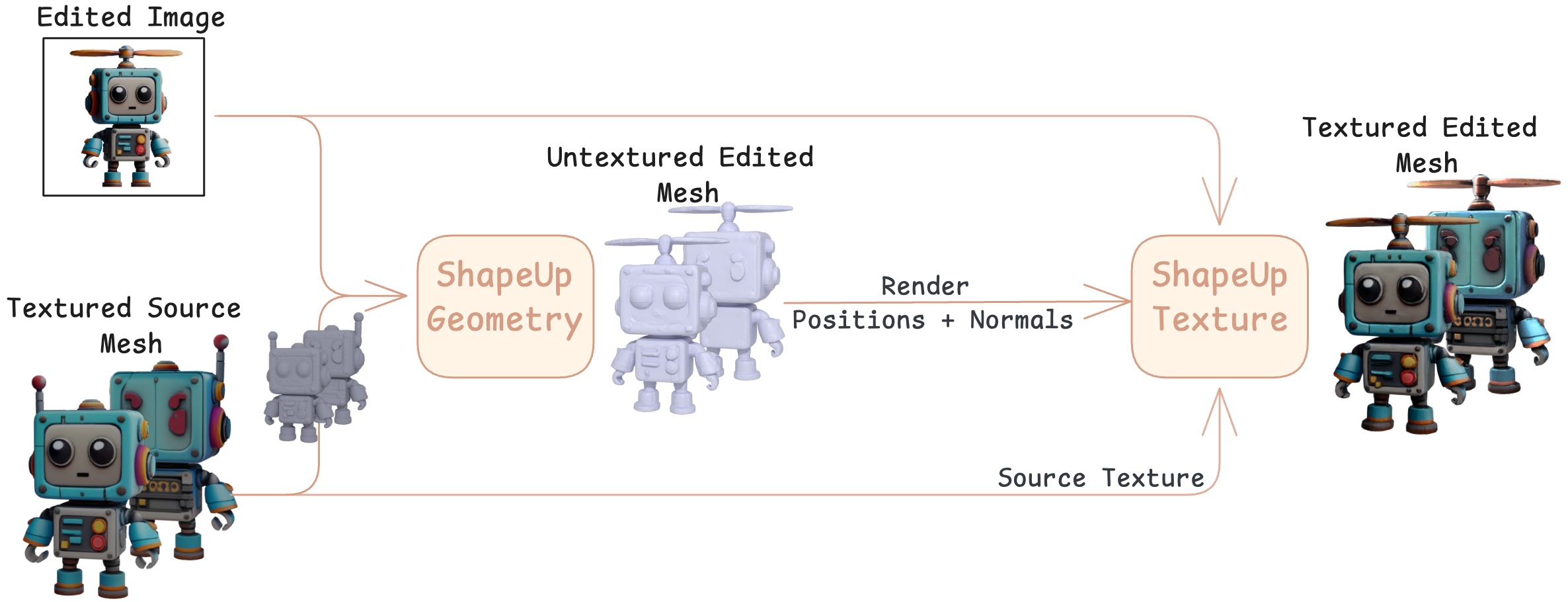
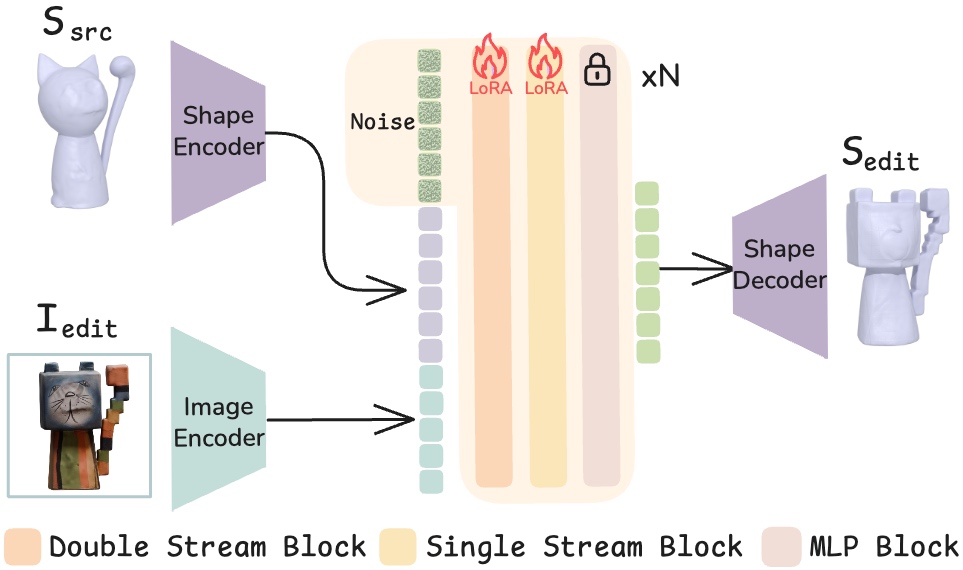
技术框架:ShapeUP的整体框架包含以下几个关键部分:1) 一个预训练的3D基础模型,用于提供3D形状的先验知识;2) 一个3D扩散Transformer (DiT),用于学习从源3D形状和编辑后的2D图像到目标3D形状的映射;3) 一个监督学习的训练流程,使用包含源3D形状、编辑后的2D图像和目标3D形状的三元组数据进行训练。在编辑时,给定一个源3D形状和一个编辑后的2D图像,ShapeUP使用训练好的DiT模型生成编辑后的3D形状。
关键创新:ShapeUP的关键创新在于将3D编辑问题转化为一个监督的潜在空间转换问题,并利用3D扩散Transformer学习图像条件下的3D形状编辑。与现有方法相比,ShapeUP能够直接学习从图像到3D形状的映射,避免了复杂的优化过程和多视图重建,从而提高了编辑速度和可扩展性。此外,ShapeUP还能够利用预训练的3D基础模型作为先验,从而提高编辑的质量和一致性。
关键设计:ShapeUP的关键设计包括:1) 使用3D扩散Transformer (DiT) 作为主要的网络结构,DiT能够有效地学习3D形状的分布,并生成高质量的3D形状;2) 使用图像作为提示,引导3D形状的编辑,从而实现对3D形状的精确视觉控制;3) 使用包含源3D形状、编辑后的2D图像和目标3D形状的三元组数据进行监督学习,从而学习从图像到3D形状的映射;4) 损失函数的设计,需要考虑编辑保真度、几何一致性和身份保持等因素。
🖼️ 关键图片

📊 实验亮点
ShapeUP在身份保持和编辑保真度方面均优于现有方法。论文通过实验证明,ShapeUP能够生成高质量的编辑后的3D形状,同时保持与原始形状的几何一致性。与基于优化的方法相比,ShapeUP的编辑速度更快,并且能够处理更大规模的3D场景。与无训练的方法相比,ShapeUP能够实现更精确的视觉控制,并生成更符合用户意图的3D形状。
🎯 应用场景
ShapeUP具有广泛的应用前景,包括游戏资产生成、虚拟现实内容创作、产品设计和定制等领域。它可以帮助用户快速、高效地创建和编辑3D内容,降低3D内容创作的门槛。未来,ShapeUP可以进一步扩展到支持更复杂的编辑操作,例如材质编辑、动画编辑等,并与其他3D工具集成,为用户提供更全面的3D内容创作解决方案。
📄 摘要(原文)
Recent advancements in 3D foundation models have enabled the generation of high-fidelity assets, yet precise 3D manipulation remains a significant challenge. Existing 3D editing frameworks often face a difficult trade-off between visual controllability, geometric consistency, and scalability. Specifically, optimization-based methods are prohibitively slow, multi-view 2D propagation techniques suffer from visual drift, and training-free latent manipulation methods are inherently bound by frozen priors and cannot directly benefit from scaling. In this work, we present ShapeUP, a scalable, image-conditioned 3D editing framework that formulates editing as a supervised latent-to-latent translation within a native 3D representation. This formulation allows ShapeUP to build on a pretrained 3D foundation model, leveraging its strong generative prior while adapting it to editing through supervised training. In practice, ShapeUP is trained on triplets consisting of a source 3D shape, an edited 2D image, and the corresponding edited 3D shape, and learns a direct mapping using a 3D Diffusion Transformer (DiT). This image-as-prompt approach enables fine-grained visual control over both local and global edits and achieves implicit, mask-free localization, while maintaining strict structural consistency with the original asset. Our extensive evaluations demonstrate that ShapeUP consistently outperforms current trained and training-free baselines in both identity preservation and edit fidelity, offering a robust and scalable paradigm for native 3D content creation.