UniSurg: A Video-Native Foundation Model for Universal Understanding of Surgical Videos
作者: Jinlin Wu, Felix Holm, Chuxi Chen, An Wang, Yaxin Hu, Xiaofan Ye, Zelin Zang, Miao Xu, Lihua Zhou, Huai Liao, Danny T. M. Chan, Ming Feng, Wai S. Poon, Hongliang Ren, Dong Yi, Nassir Navab, Gaofeng Meng, Jiebo Luo, Hongbin Liu, Zhen Lei
分类: cs.CV
发布日期: 2026-02-05
💡 一句话要点
UniSurg:面向手术视频通用理解的视频原生基础模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 手术视频理解 视频基础模型 运动预测 自蒸馏 深度学习 计算机视觉 医疗影像分析
📋 核心要点
- 现有手术视频分析方法过度依赖像素级重建,忽略了对语义信息的学习。
- UniSurg通过潜在运动预测,并结合运动引导、自蒸馏和多样性正则化,提升模型对手术视频的理解能力。
- UniSurg在多个手术视频分析任务上超越了现有技术,证明了其有效性。
📝 摘要(中文)
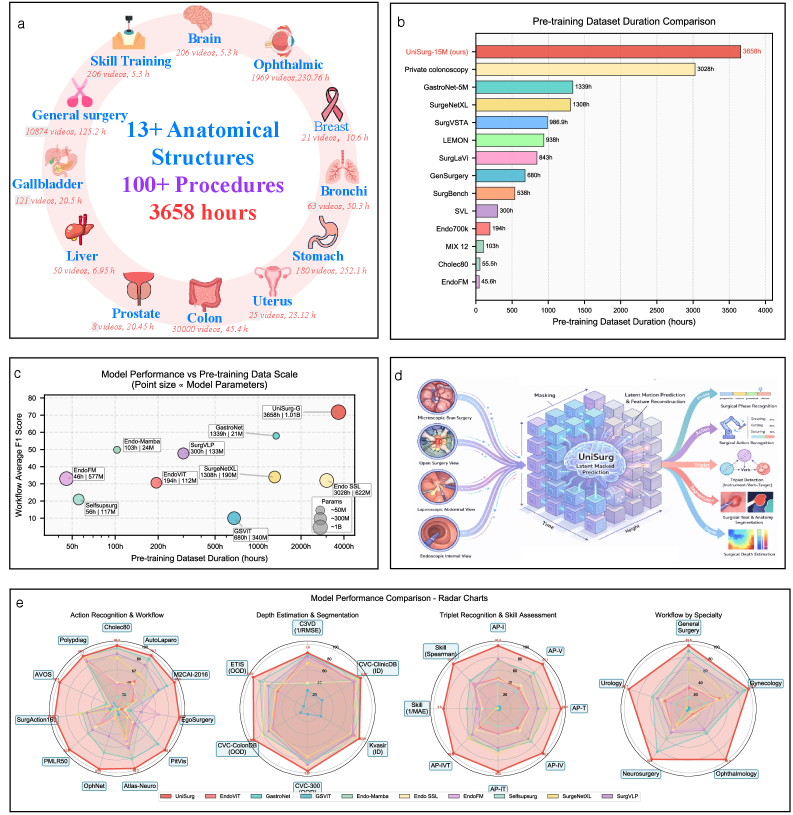
本文提出UniSurg,一种视频原生基础模型,旨在提升手术视频分析能力。与现有方法侧重于像素级重建不同,UniSurg采用潜在运动预测范式,避免模型将算力浪费在烟雾、镜面反射和流体运动等低级视觉细节上,从而更好地关注手术理解所需的语义结构。UniSurg基于视频联合嵌入预测架构(V-JEPA),引入了三项关键技术创新:运动引导的潜在预测、时空亲和自蒸馏以及特征多样性正则化。为了支持大规模预训练,作者构建了包含3658小时视频的UniSurg-15M数据集。在17个基准测试上的实验表明,UniSurg显著优于现有方法,在手术工作流程识别、动作三元组识别、技能评估、息肉分割和深度估计等方面均取得了显著提升。
🔬 方法详解
问题定义:现有手术视频分析方法主要依赖于像素级别的重建目标,这导致模型将大量的计算资源浪费在与手术理解无关的低级视觉细节上,例如烟雾、镜面反射和流体运动。这种方式忽略了手术视频中重要的语义结构,限制了模型在高级任务中的表现。
核心思路:UniSurg的核心思路是将学习范式从像素级重建转变为潜在运动预测。通过预测视频帧之间的潜在运动,模型可以更加关注视频中具有语义意义的区域,从而更好地捕捉手术过程中的关键信息。这种方法能够有效地利用模型容量,提升模型对手术视频的理解能力。
技术框架:UniSurg基于视频联合嵌入预测架构(V-JEPA)。整体框架包含预训练和微调两个阶段。在预训练阶段,模型学习预测视频帧之间的潜在运动。在微调阶段,模型被应用于各种下游任务,例如手术工作流程识别、动作三元组识别、技能评估、息肉分割和深度估计。
关键创新:UniSurg的关键创新在于以下三点:1) 运动引导的潜在预测,优先关注语义相关的区域;2) 时空亲和自蒸馏,强制关系一致性;3) 特征多样性正则化,防止纹理稀疏场景下的表示崩溃。这些创新共同提升了模型对手术视频的理解能力。
关键设计:运动引导的潜在预测通过注意力机制实现,模型根据运动幅度对不同区域赋予不同的权重。时空亲和自蒸馏通过计算不同时空位置特征之间的相似度,并利用教师模型指导学生模型的学习。特征多样性正则化通过添加额外的损失函数,鼓励模型学习到更多样化的特征表示。此外,UniSurg还使用了大规模的手术视频数据集UniSurg-15M进行预训练。
🖼️ 关键图片
📊 实验亮点
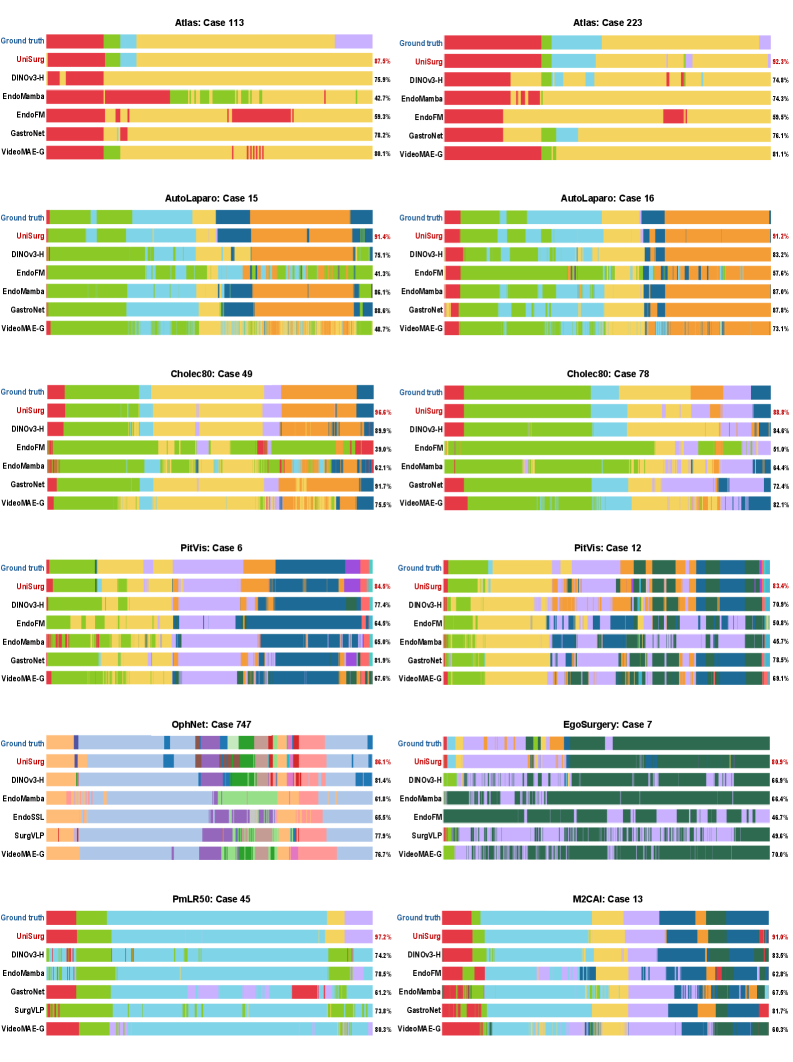
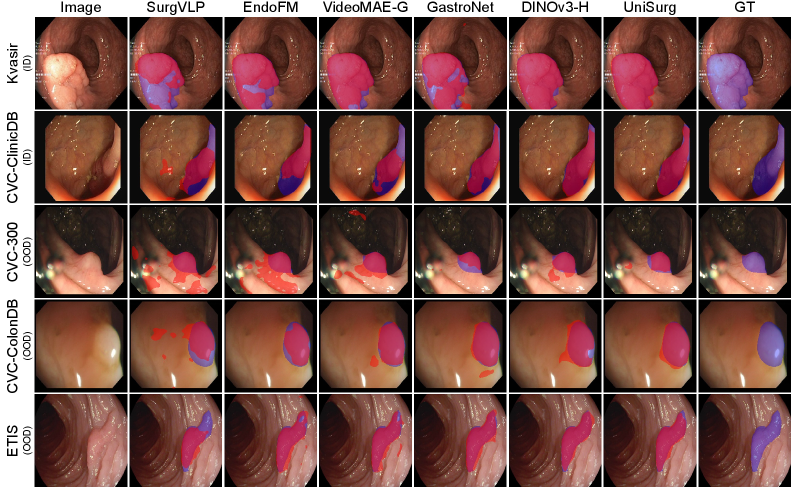
UniSurg在17个基准测试上取得了显著的性能提升。例如,在EgoSurgery数据集上的手术工作流程识别任务中,F1值提升了14.6%;在PitVis数据集上提升了10.3%。在CholecT50数据集上的动作三元组识别任务中,mAP-IVT提升至39.54%。这些结果表明,UniSurg在多个手术视频分析任务上超越了现有技术。
🎯 应用场景
UniSurg具有广泛的应用前景,可用于手术机器人导航、术中决策支持、手术技能评估、手术视频分析和教学等领域。通过提供更准确和全面的手术视频理解,UniSurg可以帮助医生提高手术效率和安全性,改善患者的治疗效果,并为手术培训提供更有效的工具。
📄 摘要(原文)
While foundation models have advanced surgical video analysis, current approaches rely predominantly on pixel-level reconstruction objectives that waste model capacity on low-level visual details - such as smoke, specular reflections, and fluid motion - rather than semantic structures essential for surgical understanding. We present UniSurg, a video-native foundation model that shifts the learning paradigm from pixel-level reconstruction to latent motion prediction. Built on the Video Joint Embedding Predictive Architecture (V-JEPA), UniSurg introduces three key technical innovations tailored to surgical videos: 1) motion-guided latent prediction to prioritize semantically meaningful regions, 2) spatiotemporal affinity self-distillation to enforce relational consistency, and 3) feature diversity regularization to prevent representation collapse in texture-sparse surgical scenes. To enable large-scale pretraining, we curate UniSurg-15M, the largest surgical video dataset to date, comprising 3,658 hours of video from 50 sources across 13 anatomical regions. Extensive experiments across 17 benchmarks demonstrate that UniSurg significantly outperforms state-of-the-art methods on surgical workflow recognition (+14.6% F1 on EgoSurgery, +10.3% on PitVis), action triplet recognition (39.54% mAP-IVT on CholecT50), skill assessment, polyp segmentation, and depth estimation. These results establish UniSurg as a new standard for universal, motion-oriented surgical video understanding.