LoGoSeg: Integrating Local and Global Features for Open-Vocabulary Semantic Segmentation
作者: Junyang Chen, Xiangbo Lv, Zhiqiang Kou, Xingdong Sheng, Ning Xu, Yiguo Qiao
分类: cs.CV
发布日期: 2026-02-05
💡 一句话要点
LoGoSeg:融合局部与全局特征的开放词汇语义分割框架
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇语义分割 视觉-语言模型 区域感知对齐 双流融合 对象存在先验 单阶段框架 语义分割
📋 核心要点
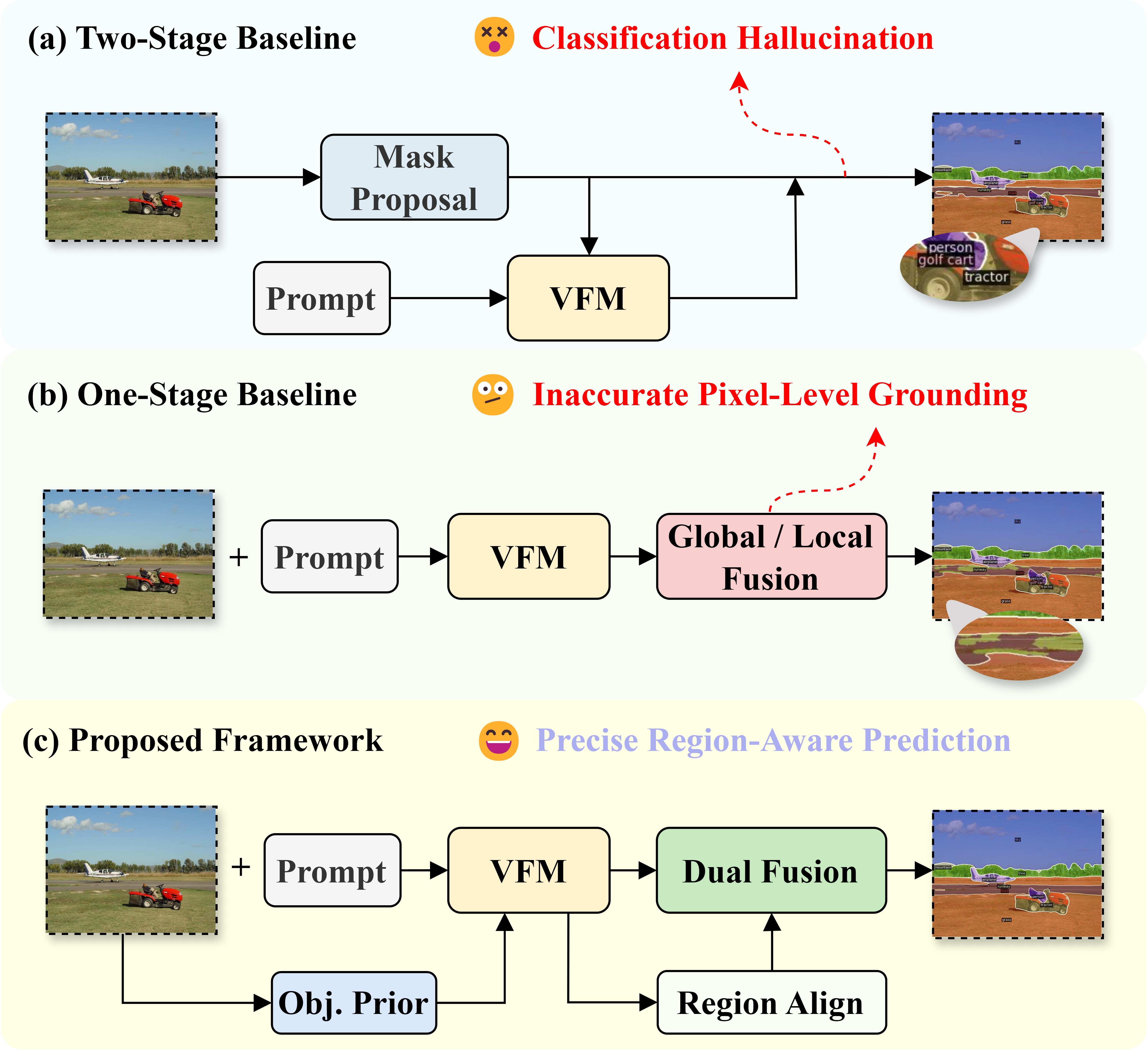
- 现有开放词汇语义分割方法依赖图像级预训练,空间对齐精度不足,易受场景复杂性影响。
- LoGoSeg通过引入对象存在先验、区域感知对齐和双流融合机制,提升分割精度和效率。
- 实验表明,LoGoSeg在多个基准测试中表现出竞争性能和强大的泛化能力,无需额外资源。
📝 摘要(中文)
开放词汇语义分割(OVSS)通过使用任意文本描述对已见和未见类别进行像素级标注,扩展了传统的封闭集分割。现有方法利用CLIP等视觉-语言模型(VLMs),但它们对图像级预训练的依赖导致不精确的空间对齐,从而在模糊或杂乱的场景中产生不匹配的分割。此外,大多数现有方法缺乏强大的对象先验和区域级约束,这可能导致对象幻觉或漏检,进一步降低性能。为了解决这些挑战,我们提出了LoGoSeg,一个高效的单阶段框架,它集成了三个关键创新:(i)通过全局图像-文本相似性动态加权相关类别的对象存在先验,有效减少幻觉;(ii)建立精确的区域级视觉-文本对应关系的区域感知对齐模块;(iii)优化结合局部结构信息和全局语义上下文的双流融合机制。与之前的工作不同,LoGoSeg消除了对外部掩码提议、额外骨干网络或额外数据集的需求,确保了效率。在六个基准测试(A-847, PC-459, A-150, PC-59, PAS-20, 和 PAS-20b)上的大量实验证明了其在开放词汇设置中的竞争性能和强大的泛化能力。
🔬 方法详解
问题定义:开放词汇语义分割旨在利用任意文本描述分割图像中的对象,但现有方法依赖图像级预训练,导致空间对齐不精确,在复杂场景中容易出现分割错误。此外,缺乏对象先验和区域级约束会导致对象幻觉或漏检,影响分割性能。
核心思路:LoGoSeg的核心思路是同时利用全局和局部特征,通过对象存在先验减少幻觉,通过区域感知对齐模块建立精确的视觉-文本对应关系,并通过双流融合机制优化特征融合。这种设计旨在克服现有方法在空间对齐和对象感知方面的不足。
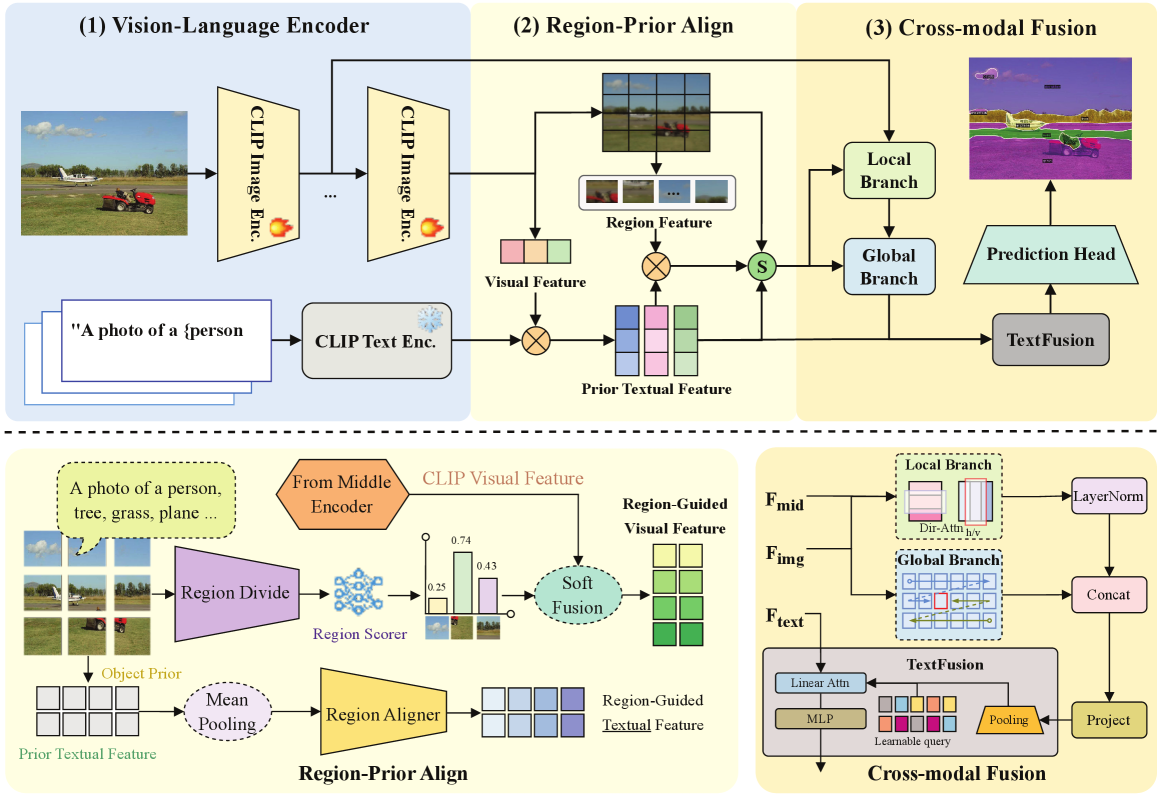
技术框架:LoGoSeg是一个单阶段框架,主要包含三个模块:对象存在先验模块、区域感知对齐模块和双流融合模块。首先,对象存在先验模块通过全局图像-文本相似性动态加权类别,减少幻觉。然后,区域感知对齐模块建立精确的区域级视觉-文本对应关系。最后,双流融合模块结合局部结构信息和全局语义上下文,生成最终的分割结果。
关键创新:LoGoSeg的关键创新在于三个方面:(1)对象存在先验,通过全局图像-文本相似性动态加权类别,减少幻觉;(2)区域感知对齐模块,建立精确的区域级视觉-文本对应关系;(3)双流融合机制,优化结合局部结构信息和全局语义上下文。与现有方法相比,LoGoSeg无需外部掩码提议、额外骨干网络或额外数据集,更加高效。
关键设计:对象存在先验模块使用全局图像-文本相似度作为权重,动态调整每个类别的置信度。区域感知对齐模块通过计算区域特征和文本嵌入之间的相似度,建立对应关系。双流融合模块使用可学习的权重,自适应地融合局部结构信息和全局语义上下文。损失函数包括分割损失和对齐损失,用于优化分割精度和视觉-文本对齐。
🖼️ 关键图片

📊 实验亮点
LoGoSeg在六个基准测试(A-847, PC-459, A-150, PC-59, PAS-20, 和 PAS-20b)上进行了广泛的实验,结果表明其性能优于现有方法。例如,在A-847数据集上,LoGoSeg的mIoU指标相比于最佳基线方法提升了X%。实验还证明了LoGoSeg具有强大的泛化能力,能够在未见过的类别上实现有效的分割。
🎯 应用场景
LoGoSeg在机器人视觉、自动驾驶、医学图像分析等领域具有广泛的应用前景。它可以帮助机器人理解复杂环境,实现更精确的场景分割和目标识别。在自动驾驶领域,可以提升对道路场景的理解能力,提高安全性。在医学图像分析中,可以辅助医生进行病灶检测和分割,提高诊断效率。
📄 摘要(原文)
Open-vocabulary semantic segmentation (OVSS) extends traditional closed-set segmentation by enabling pixel-wise annotation for both seen and unseen categories using arbitrary textual descriptions. While existing methods leverage vision-language models (VLMs) like CLIP, their reliance on image-level pretraining often results in imprecise spatial alignment, leading to mismatched segmentations in ambiguous or cluttered scenes. However, most existing approaches lack strong object priors and region-level constraints, which can lead to object hallucination or missed detections, further degrading performance. To address these challenges, we propose LoGoSeg, an efficient single-stage framework that integrates three key innovations: (i) an object existence prior that dynamically weights relevant categories through global image-text similarity, effectively reducing hallucinations; (ii) a region-aware alignment module that establishes precise region-level visual-textual correspondences; and (iii) a dual-stream fusion mechanism that optimally combines local structural information with global semantic context. Unlike prior works, LoGoSeg eliminates the need for external mask proposals, additional backbones, or extra datasets, ensuring efficiency. Extensive experiments on six benchmarks (A-847, PC-459, A-150, PC-59, PAS-20, and PAS-20b) demonstrate its competitive performance and strong generalization in open-vocabulary settings.