Dataset Distillation via Relative Distribution Matching and Cognitive Heritage
作者: Qianxin Xia, Jiawei Du, Yuhan Zhang, Jielei Wang, Guoming Lu
分类: cs.CV
发布日期: 2026-02-05
💡 一句话要点
提出基于统计流匹配和认知继承的数据集蒸馏方法,降低计算和内存开销。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 数据集蒸馏 统计流匹配 认知继承 线性分类器 预训练模型
📋 核心要点
- 现有数据集蒸馏方法计算和内存开销大,尤其是在使用预训练模型作为骨干网络时,需要大量真实图像和多次数据增强。
- 论文提出统计流匹配方法,通过对齐目标类中心到非目标类中心的统计流来优化合成图像,降低计算复杂度。
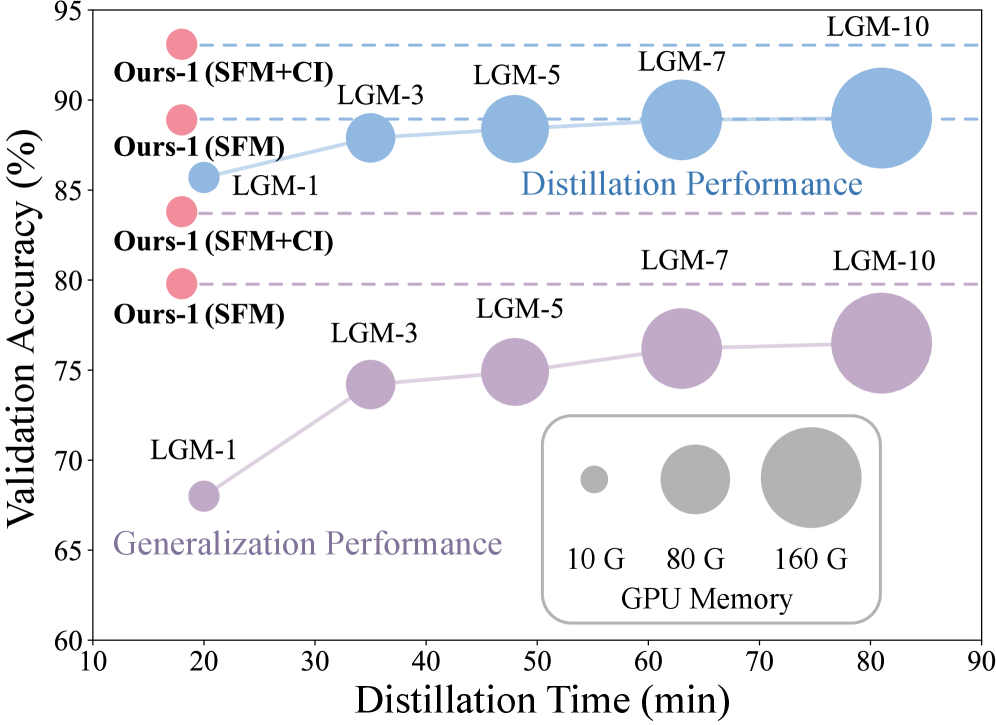
- 实验表明,该方法在降低GPU内存使用和运行时间的同时,性能与现有最佳方法相当甚至更好,并提出了分类器继承策略进一步提升性能。
📝 摘要(中文)
数据集蒸馏旨在合成一个高度紧凑的数据集,使其在下游任务上达到与原始数据集相当的性能。对于使用预训练自监督模型作为骨干的分类任务,先前的线性梯度匹配方法通过鼓励合成图像模仿真实图像在线性分类器上引起的梯度更新来优化合成图像。然而,这种批处理级别的公式需要在每个蒸馏步骤中加载数千个真实图像,并对合成图像应用多轮可微增强,导致大量的计算和内存开销。本文提出了一种统计流匹配方法,这是一种稳定高效的监督学习框架,通过对齐原始数据中从目标类中心到非目标类中心的恒定统计流来优化合成图像。我们的方法仅加载一次原始统计信息,并对合成数据执行单次增强,以10倍更低的GPU内存使用量和4倍更短的运行时间实现了与最先进方法相当或更好的性能。此外,我们提出了一种分类器继承策略,该策略重用在原始数据集上训练的分类器进行推理,只需要一个非常轻量级的线性投影器和极少的存储空间,同时实现了显著的性能提升。
🔬 方法详解
问题定义:数据集蒸馏旨在用远小于原始数据集的合成数据集,训练出性能接近甚至超过原始数据集训练的模型。现有方法,如线性梯度匹配,在蒸馏过程中需要加载大量真实图像,并对合成图像进行多次可微增强,导致计算和内存开销巨大,限制了其在大规模数据集和复杂模型上的应用。
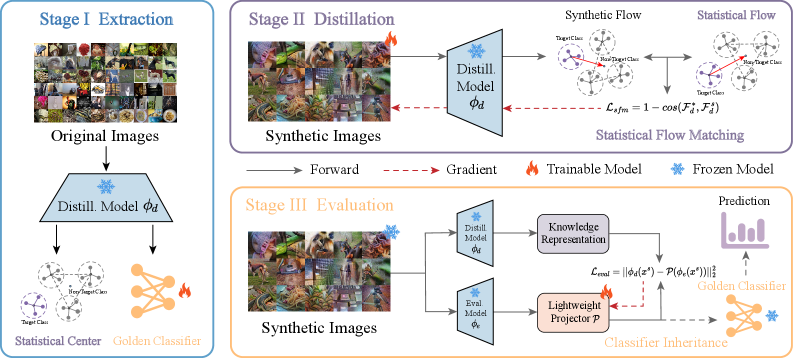
核心思路:论文的核心思路是通过对齐原始数据集中目标类中心到非目标类中心的统计流来优化合成图像。这种方法避免了对真实图像的重复加载和多次增强,从而显著降低了计算复杂度。同时,论文还提出了分类器继承策略,直接利用原始数据集训练的分类器,进一步提升性能。
技术框架:该方法主要包含两个阶段:统计流匹配和分类器继承。在统计流匹配阶段,首先计算原始数据集中目标类中心到非目标类中心的统计流。然后,通过优化合成图像,使其生成的统计流与原始数据集的统计流对齐。在分类器继承阶段,直接使用在原始数据集上训练的分类器,并添加一个轻量级的线性投影层,以适应合成数据集的特征分布。
关键创新:该方法最重要的创新点在于提出了统计流匹配的概念,将数据集蒸馏问题转化为统计流的对齐问题。与传统的梯度匹配方法相比,统计流匹配只需要加载一次原始数据集的统计信息,并对合成数据进行单次增强,大大降低了计算和内存开销。此外,分类器继承策略也避免了从头开始训练分类器,进一步提升了性能。
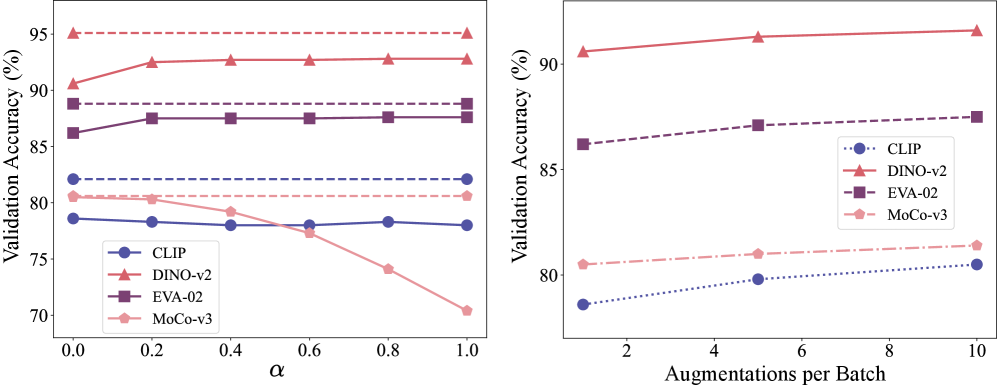
关键设计:在统计流匹配阶段,使用了基于最优传输的统计流计算方法。损失函数设计为合成数据集和原始数据集统计流之间的距离度量。分类器继承策略中,线性投影层的维度根据具体任务进行调整。数据增强策略采用了常见的随机裁剪和颜色抖动等方法。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在多个数据集上取得了与现有最佳方法相当甚至更好的性能,同时显著降低了计算和内存开销。例如,在CIFAR-10数据集上,该方法使用10倍更低的GPU内存和4倍更短的运行时间,达到了与现有最佳方法相当的精度。分类器继承策略也带来了显著的性能提升,在某些数据集上提升了超过2个百分点。
🎯 应用场景
该研究成果可应用于资源受限的场景,例如移动设备或嵌入式系统,在这些场景下,存储和计算资源有限,无法存储和处理大型数据集。通过数据集蒸馏,可以将原始数据集压缩成一个更小的合成数据集,从而可以在这些设备上部署高性能的机器学习模型。此外,该方法还可以用于数据隐私保护,通过合成数据集来代替原始数据集,避免泄露敏感信息。
📄 摘要(原文)
Dataset distillation seeks to synthesize a highly compact dataset that achieves performance comparable to the original dataset on downstream tasks. For the classification task that use pre-trained self-supervised models as backbones, previous linear gradient matching optimizes synthetic images by encouraging them to mimic the gradient updates induced by real images on the linear classifier. However, this batch-level formulation requires loading thousands of real images and applying multiple rounds of differentiable augmentations to synthetic images at each distillation step, leading to substantial computational and memory overhead. In this paper, we introduce statistical flow matching , a stable and efficient supervised learning framework that optimizes synthetic images by aligning constant statistical flows from target class centers to non-target class centers in the original data. Our approach loads raw statistics only once and performs a single augmentation pass on the synthetic data, achieving performance comparable to or better than the state-of-the-art methods with 10x lower GPU memory usage and 4x shorter runtime. Furthermore, we propose a classifier inheritance strategy that reuses the classifier trained on the original dataset for inference, requiring only an extremely lightweight linear projector and marginal storage while achieving substantial performance gains.