Multimodal Latent Reasoning via Hierarchical Visual Cues Injection
作者: Yiming Zhang, Qiangyu Yan, Borui Jiang, Kai Han
分类: cs.CV
发布日期: 2026-02-05
💡 一句话要点
提出HIVE框架,通过层级视觉线索注入实现多模态潜在空间推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 潜在空间推理 层级视觉线索 视觉问答 Transformer 迭代推理 视觉信息注入
📋 核心要点
- 现有MLLM推理依赖于快速思考模式,易产生幻觉,缺乏在潜在空间中整合多模态信息的能力。
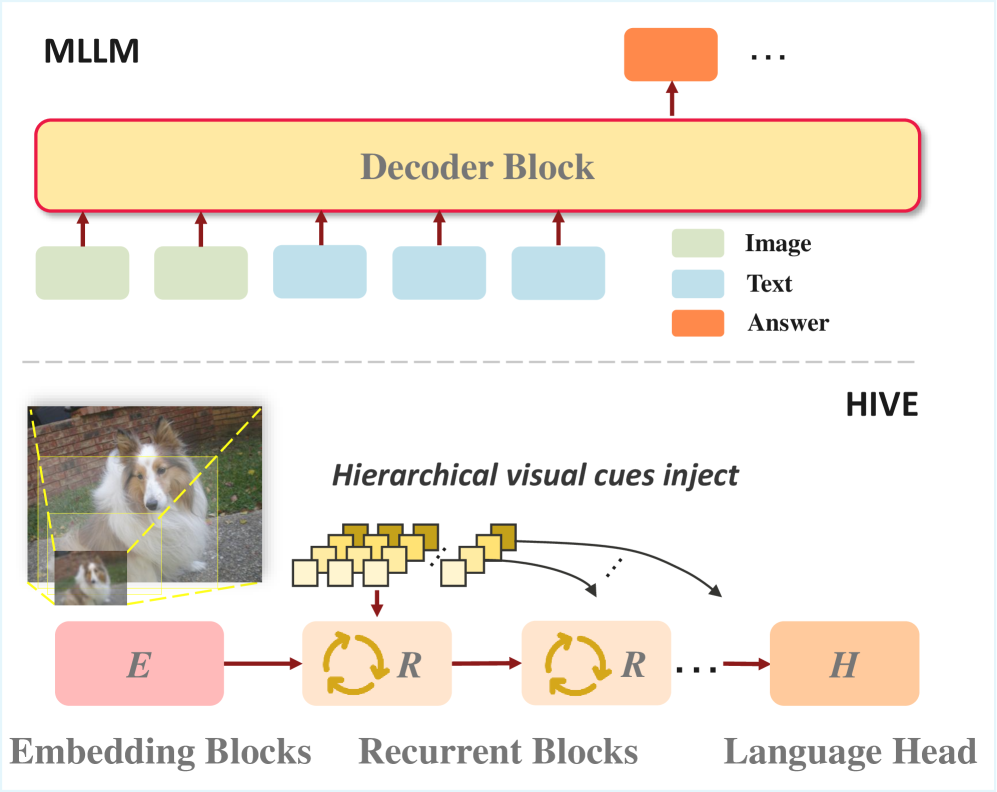
- HIVE框架通过递归扩展Transformer块,构建迭代推理循环,实现深思熟虑的“慢思考”推理。
- HIVE将层级视觉线索注入潜在表示,使模型在对齐的潜在空间中执行基于视觉信息的推理,提升复杂场景理解。
📝 摘要(中文)
多模态大型语言模型(MLLM)的进步带来了令人印象深刻的感知能力。然而,它们的推理过程通常仍然是一种“快速思考”模式,依赖于端到端生成或显式的、以语言为中心的思维链(CoT),这可能是低效、冗长且容易产生幻觉的。这项工作认为,稳健的推理应该在潜在空间内发展,无缝地整合多模态信号。我们提出了通过层级视觉线索注入的多模态潜在推理(HIVE),这是一种新颖的框架,它在不依赖于表面文本理由的情况下,灌输深思熟虑的“慢思考”。我们的方法递归地扩展了transformer块,创建了一个用于迭代推理细化的内部循环。至关重要的是,它通过将从全局场景上下文到细粒度区域细节的层级视觉线索直接注入到模型的潜在表示中,从而注入式地将这一过程与视觉信息对齐。这使得模型能够在完全对齐的潜在空间中执行基于视觉信息的、多步骤的推理。广泛的评估表明,在结合视觉知识时,测试时缩放是有效的,并且整合层级信息显著增强了模型对复杂场景的理解。
🔬 方法详解
问题定义:现有的多模态大型语言模型(MLLM)在推理过程中,过度依赖于端到端的生成或者显式的、以语言为中心的思维链(CoT)。这些方法效率低下,冗长,并且容易产生幻觉。它们缺乏在潜在空间中有效整合多模态信息的能力,难以进行深层次的、基于视觉信息的推理。
核心思路:论文的核心思路是在模型的潜在空间中进行推理,而不是依赖于显式的文本理由。通过将视觉信息直接注入到模型的潜在表示中,使模型能够在潜在空间中进行多步骤的推理,从而避免了传统方法的缺点。这种方法模拟了人类的“慢思考”过程,允许模型逐步细化其推理结果。
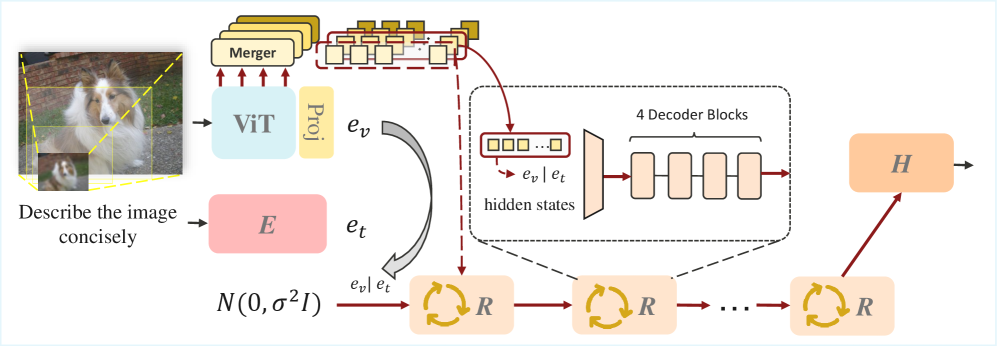
技术框架:HIVE框架通过递归扩展Transformer块来构建迭代推理循环。该框架包含以下主要模块:1) 视觉编码器,用于提取层级视觉特征;2) 潜在推理模块,通过递归Transformer块进行迭代推理;3) 视觉线索注入模块,将层级视觉特征注入到潜在表示中。整体流程是:首先,视觉编码器提取全局场景上下文到细粒度区域细节的层级视觉特征。然后,这些特征被注入到潜在推理模块中,该模块通过递归Transformer块进行迭代推理,逐步细化推理结果。
关键创新:HIVE框架的关键创新在于其在潜在空间中进行多模态推理的能力。与现有方法不同,HIVE不依赖于显式的文本理由,而是直接将视觉信息注入到模型的潜在表示中,使模型能够在潜在空间中进行多步骤的推理。此外,HIVE还采用了层级视觉线索注入的方式,使模型能够更好地理解复杂场景。
关键设计:HIVE框架的关键设计包括:1) 递归Transformer块的结构,用于实现迭代推理;2) 层级视觉线索注入的方式,用于将视觉信息注入到潜在表示中;3) 损失函数的设计,用于优化模型的推理能力。具体的参数设置和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片
📊 实验亮点
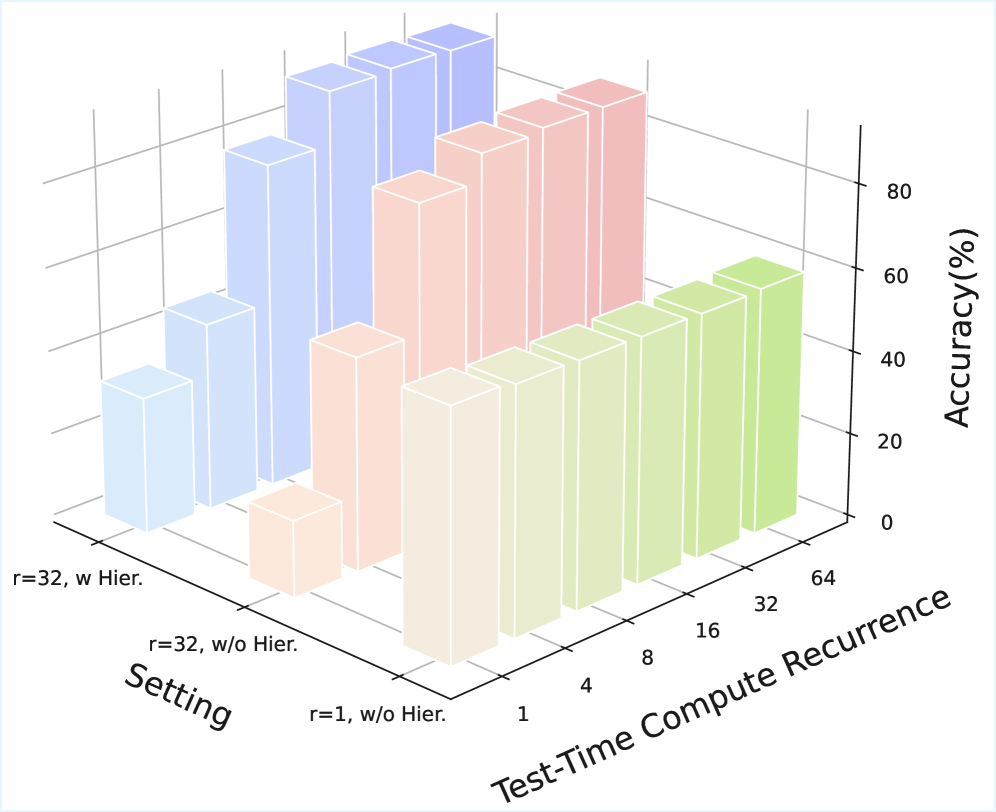
实验结果表明,HIVE框架在多个视觉推理任务上取得了显著的性能提升。通过整合层级信息,模型对复杂场景的理解能力得到了显著增强。此外,实验还证明了测试时缩放(test-time scaling)在结合视觉知识时是有效的。
🎯 应用场景
该研究成果可应用于智能视觉问答、图像理解、机器人导航等领域。通过提升模型对复杂场景的理解和推理能力,可以提高智能系统的智能化水平和应用范围。未来,该方法有望在自动驾驶、智能家居、医疗诊断等领域发挥重要作用。
📄 摘要(原文)
The advancement of multimodal large language models (MLLMs) has enabled impressive perception capabilities. However, their reasoning process often remains a "fast thinking" paradigm, reliant on end-to-end generation or explicit, language-centric chains of thought (CoT), which can be inefficient, verbose, and prone to hallucination. This work posits that robust reasoning should evolve within a latent space, integrating multimodal signals seamlessly. We propose multimodal latent reasoning via HIerarchical Visual cuEs injection (\emph{HIVE}), a novel framework that instills deliberate, "slow thinking" without depending on superficial textual rationales. Our method recursively extends transformer blocks, creating an internal loop for iterative reasoning refinement. Crucially, it injectively grounds this process with hierarchical visual cues from global scene context to fine-grained regional details directly into the model's latent representations. This enables the model to perform grounded, multi-step inference entirely in the aligned latent space. Extensive evaluations demonstrate that test-time scaling is effective when incorporating vision knowledge, and that integrating hierarchical information significantly enhances the model's understanding of complex scenes.