Wid3R: Wide Field-of-View 3D Reconstruction via Camera Model Conditioning
作者: Dongki Jung, Jaehoon Choi, Adil Qureshi, Somi Jeong, Dinesh Manocha, Suyong Yeon
分类: cs.CV
发布日期: 2026-02-05
💡 一句话要点
Wid3R:通过相机模型条件化实现宽视场3D重建
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D重建 宽视场 相机模型 球谐函数 多视图几何
📋 核心要点
- 现有3D重建方法依赖于针孔相机模型或校正后的图像,限制了其在鱼眼或全景相机等宽视场场景的应用。
- Wid3R通过引入球谐函数射线表示和相机模型token,实现了对宽视场相机畸变的建模,从而进行3D重建。
- Wid3R作为首个支持360度图像前馈3D重建的多视图基础模型,展现了强大的零样本鲁棒性,并在Stanford2D3D数据集上取得了显著提升。
📝 摘要(中文)
本文提出Wid3R,一种用于视觉几何重建的前馈神经网络,支持宽视场相机模型。现有方法通常假设输入图像是经过校正的或由针孔相机捕获的,因为它们的架构和训练数据集都只针对透视图像。这些假设限制了它们在现实场景中的适用性,而现实场景通常使用鱼眼或全景相机,并且通常需要仔细的校准和去畸变。相比之下,Wid3R是一种通用的多视图3D估计方法,可以对宽视场相机类型进行建模。我们的方法利用带有球谐函数的射线表示和网络中的新型相机模型token,从而实现感知畸变的3D重建。此外,Wid3R是第一个直接从360度图像支持前馈3D重建的多视图基础模型。它展示了强大的零样本鲁棒性,并且始终优于先前的方法,在Stanford2D3D上实现了高达+77.33的改进。
🔬 方法详解
问题定义:现有基于深度学习的3D重建方法主要针对针孔相机模型或经过校正的图像,无法直接处理来自鱼眼、全景相机等宽视场相机的图像。这些宽视场相机在实际应用中越来越常见,但传统方法需要繁琐的校准和去畸变过程,限制了其易用性和效率。因此,如何直接从宽视场图像中进行高效、准确的3D重建是一个重要的挑战。
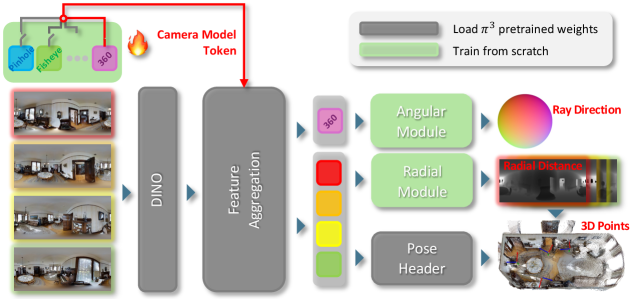
核心思路:Wid3R的核心思路是通过显式地建模相机模型,使网络能够感知并处理不同类型的相机畸变。具体来说,它引入了一种新型的相机模型token,该token包含了相机内参等信息,并将其作为网络的输入。此外,Wid3R使用球谐函数来表示射线,从而能够更好地处理宽视场图像中存在的较大视差和畸变。
技术框架:Wid3R的整体架构是一个前馈神经网络,它以多视图图像和对应的相机参数作为输入,输出3D场景的重建结果。该网络主要包含以下几个模块:1) 特征提取模块:用于从输入图像中提取图像特征。2) 相机模型编码模块:将相机参数编码为相机模型token。3) 射线表示模块:使用球谐函数来表示从相机中心发出的射线。4) 3D重建模块:将图像特征、相机模型token和射线表示结合起来,预测3D场景的几何结构。
关键创新:Wid3R的关键创新在于其对相机模型的显式建模和对射线表示的改进。通过引入相机模型token,网络能够感知不同类型的相机畸变,从而更好地进行3D重建。使用球谐函数表示射线,能够更好地处理宽视场图像中存在的较大视差和畸变。此外,Wid3R是第一个直接从360度图像支持前馈3D重建的多视图基础模型。
关键设计:Wid3R的关键设计包括:1) 相机模型token的设计:该token包含了相机内参等信息,并经过嵌入层进行编码。2) 球谐函数的阶数选择:作者通过实验确定了合适的球谐函数阶数,以在精度和计算效率之间取得平衡。3) 损失函数的设计:作者使用了多种损失函数,包括几何损失和光度损失,以提高重建结果的质量。
🖼️ 关键图片


📊 实验亮点
Wid3R在Stanford2D3D数据集上取得了显著的性能提升,相比于现有方法,实现了高达+77.33的改进。此外,Wid3R展现了强大的零样本鲁棒性,能够在未见过的场景和相机类型上进行有效的3D重建。这些实验结果表明,Wid3R是一种高效、准确且通用的宽视场3D重建方法。
🎯 应用场景
Wid3R在机器人导航、自动驾驶、虚拟现实/增强现实等领域具有广泛的应用前景。它可以直接处理来自鱼眼相机或全景相机的图像,无需进行繁琐的校准和去畸变,从而简化了系统部署和维护。此外,Wid3R的零样本鲁棒性使其能够适应不同的场景和相机类型,具有很强的通用性。
📄 摘要(原文)
We present Wid3R, a feed-forward neural network for visual geometry reconstruction that supports wide field-of-view camera models. Prior methods typically assume that input images are rectified or captured with pinhole cameras, since both their architectures and training datasets are tailored to perspective images only. These assumptions limit their applicability in real-world scenarios that use fisheye or panoramic cameras and often require careful calibration and undistortion. In contrast, Wid3R is a generalizable multi-view 3D estimation method that can model wide field-of-view camera types. Our approach leverages a ray representation with spherical harmonics and a novel camera model token within the network, enabling distortion-aware 3D reconstruction. Furthermore, Wid3R is the first multi-view foundation model to support feed-forward 3D reconstruction directly from 360 imagery. It demonstrates strong zero-shot robustness and consistently outperforms prior methods, achieving improvements of up to +77.33 on Stanford2D3D.