Fast-SAM3D: 3Dfy Anything in Images but Faster
作者: Weilun Feng, Mingqiang Wu, Zhiliang Chen, Chuanguang Yang, Haotong Qin, Yuqi Li, Xiaokun Liu, Guoxin Fan, Zhulin An, Libo Huang, Yulun Zhang, Michele Magno, Yongjun Xu
分类: cs.CV
发布日期: 2026-02-05
🔗 代码/项目: GITHUB
💡 一句话要点
Fast-SAM3D:加速图像三维重建,提升推理效率且保持精度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱八:物理动画 (Physics-based Animation)
关键词: 三维重建 单视图重建 模型加速 异构性感知 计算优化
📋 核心要点
- 现有SAM3D方法推理延迟高,阻碍了其在实际场景中的应用,需要更高效的解决方案。
- Fast-SAM3D通过动态调整计算资源分配,针对性地优化pipeline中的异构性,实现加速。
- 实验表明,Fast-SAM3D在几乎不损失精度的前提下,实现了高达2.67倍的端到端加速。
📝 摘要(中文)
SAM3D实现了复杂场景的可扩展、开放世界三维重建,但其高昂的推理延迟阻碍了部署。本文对SAM3D的推理过程进行了首次系统性研究,发现通用加速策略在此背景下表现不佳。研究表明,这些失败源于忽略了pipeline固有的多层次异构性:形状和布局之间的运动学差异、纹理细化的内在稀疏性以及几何体之间的光谱差异。为此,我们提出了Fast-SAM3D,一个无需训练的框架,可动态地将计算与瞬时生成复杂度对齐。我们的方法集成了三种异构性感知机制:(1)模态感知步骤缓存,将结构演化与敏感的布局更新解耦;(2)联合时空Token雕刻,将细化集中在高熵区域;(3)光谱感知Token聚合,以适应解码分辨率。大量实验表明,Fast-SAM3D在可忽略的保真度损失下,提供了高达2.67倍的端到端加速,为高效单视图三维生成建立了一个新的Pareto前沿。
🔬 方法详解
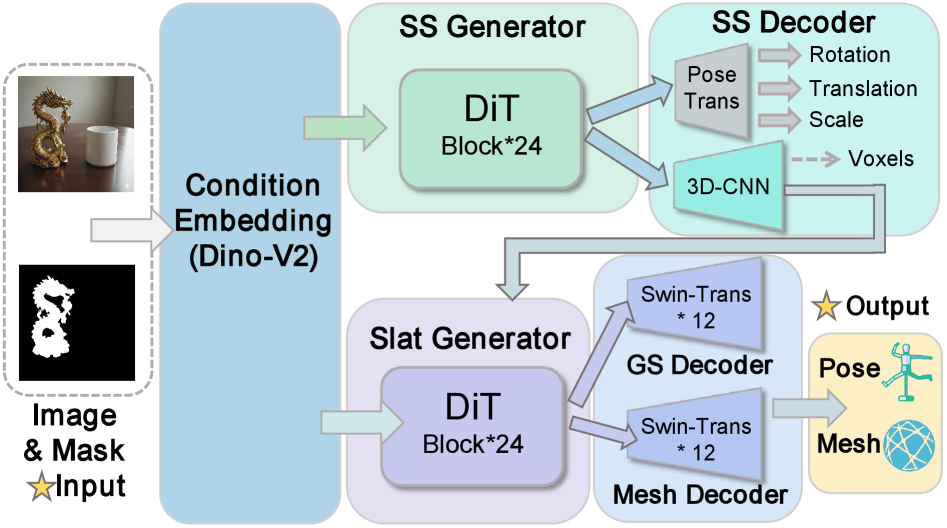
问题定义:SAM3D虽然能够从单张图像中重建三维场景,但其推理速度慢,难以满足实时性要求。现有的通用加速方法无法有效解决SAM3D的性能瓶颈,因为它们忽略了SAM3D pipeline中存在的多层次异构性,例如形状和布局的不同特性,纹理细化的稀疏性,以及几何体的光谱差异。
核心思路:Fast-SAM3D的核心思路是根据场景的复杂度和各个模块的特性,动态地调整计算资源的分配,从而在保证重建质量的前提下,最大程度地减少计算量。通过针对性的优化策略,解决SAM3D pipeline中存在的异构性问题,实现加速。
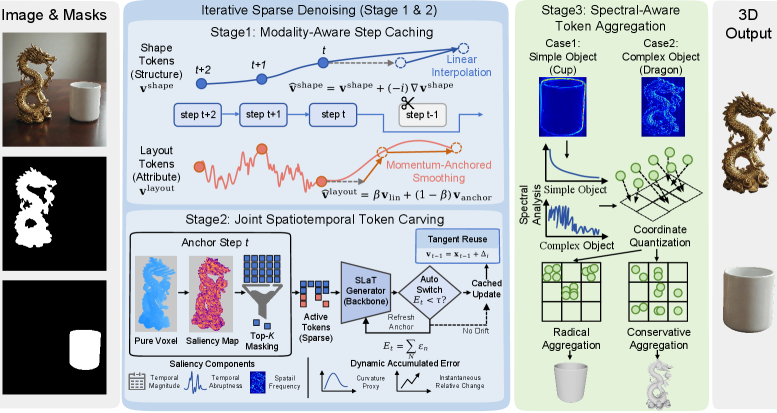
技术框架:Fast-SAM3D是一个无需训练的框架,主要包含三个模块:(1) Modality-Aware Step Caching(模态感知步骤缓存):将结构演化与敏感的布局更新解耦,减少不必要的计算。(2) Joint Spatiotemporal Token Carving(联合时空Token雕刻):将细化操作集中在高熵区域,减少对低熵区域的计算。(3) Spectral-Aware Token Aggregation(光谱感知Token聚合):根据几何体的光谱特性,自适应地调整解码分辨率。
关键创新:Fast-SAM3D的关键创新在于其异构性感知的设计。它不是简单地应用通用的加速策略,而是深入分析了SAM3D pipeline的特点,针对不同的模块和数据,采用了不同的优化方法。这种针对性的优化策略能够更有效地减少计算量,同时保证重建质量。
关键设计:(1) Modality-Aware Step Caching:通过缓存中间步骤的结果,避免重复计算,尤其是在布局更新不频繁的情况下。(2) Joint Spatiotemporal Token Carving:使用熵作为衡量区域重要性的指标,只对高熵区域进行细化。(3) Spectral-Aware Token Aggregation:根据几何体的光谱特性,动态调整解码分辨率,避免对低频区域进行过多的计算。
🖼️ 关键图片
📊 实验亮点
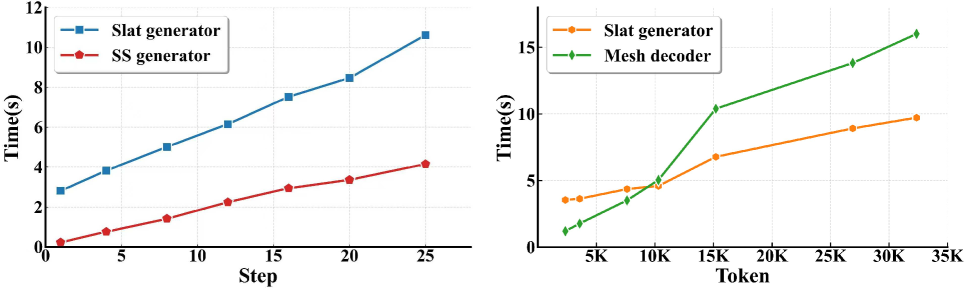
Fast-SAM3D在实验中实现了显著的加速效果,在几乎不损失精度的前提下,实现了高达2.67倍的端到端加速。这表明Fast-SAM3D能够有效地解决SAM3D推理速度慢的问题,为高效单视图三维生成提供了一个新的解决方案。实验结果证明了Fast-SAM3D的有效性和实用性。
🎯 应用场景
Fast-SAM3D可应用于机器人导航、虚拟现实、增强现实、游戏开发等领域。它能够快速地从单张图像中重建三维场景,为这些应用提供高质量的三维数据。通过提高三维重建的速度,Fast-SAM3D可以促进这些技术在实际场景中的应用,例如,机器人可以更快地理解周围环境,从而更好地进行导航和交互。
📄 摘要(原文)
SAM3D enables scalable, open-world 3D reconstruction from complex scenes, yet its deployment is hindered by prohibitive inference latency. In this work, we conduct the \textbf{first systematic investigation} into its inference dynamics, revealing that generic acceleration strategies are brittle in this context. We demonstrate that these failures stem from neglecting the pipeline's inherent multi-level \textbf{heterogeneity}: the kinematic distinctiveness between shape and layout, the intrinsic sparsity of texture refinement, and the spectral variance across geometries. To address this, we present \textbf{Fast-SAM3D}, a training-free framework that dynamically aligns computation with instantaneous generation complexity. Our approach integrates three heterogeneity-aware mechanisms: (1) \textit{Modality-Aware Step Caching} to decouple structural evolution from sensitive layout updates; (2) \textit{Joint Spatiotemporal Token Carving} to concentrate refinement on high-entropy regions; and (3) \textit{Spectral-Aware Token Aggregation} to adapt decoding resolution. Extensive experiments demonstrate that Fast-SAM3D delivers up to \textbf{2.67$\times$} end-to-end speedup with negligible fidelity loss, establishing a new Pareto frontier for efficient single-view 3D generation. Our code is released in https://github.com/wlfeng0509/Fast-SAM3D.