Magic-MM-Embedding: Towards Visual-Token-Efficient Universal Multimodal Embedding with MLLMs
作者: Qi Li, Yanzhe Zhao, Yongxin Zhou, Yameng Wang, Yandong Yang, Yuanjia Zhou, Jue Wang, Zuojian Wang, Jinxiang Liu
分类: cs.CV
发布日期: 2026-02-05
💡 一句话要点
提出Magic-MM-Embedding,通过视觉token压缩和多阶段训练提升MLLM在通用多模态嵌入中的效率和性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 视觉token压缩 对比学习 多阶段训练 信息检索 跨模态理解
📋 核心要点
- 现有MLLM在通用多模态检索中计算成本高昂,主要瓶颈在于视觉输入token数量庞大。
- Magic-MM-Embedding通过视觉token压缩降低计算量,并采用多阶段训练策略提升模型性能。
- 实验结果表明,该模型在效率和性能上均超越现有方法,实现了显著的性能提升。
📝 摘要(中文)
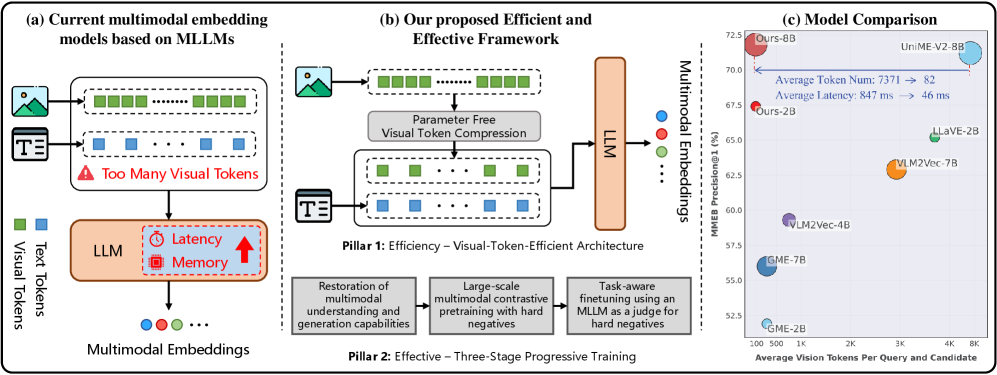
多模态大型语言模型(MLLM)在通用多模态检索中展现了巨大的潜力,旨在为给定的查询找到各种模态的相关项。但由于处理大量视觉输入token所带来的巨大计算成本,其实际应用常常受到阻碍。本文提出了Magic-MM-Embedding,一系列新型模型,在通用多模态嵌入中实现了高效率和最先进的性能。我们的方法建立在两个协同支柱之上:(1)一种高效的MLLM架构,结合了视觉token压缩,以大幅降低推理延迟和内存占用;(2)一种多阶段渐进式训练策略,旨在不仅恢复而且显著提升性能。这种由粗到精的训练范式首先进行广泛的持续预训练,以恢复多模态理解和生成能力,然后进行大规模对比预训练和困难负样本挖掘,以增强判别能力,最后在MLLM-as-a-Judge的指导下进行任务感知微调阶段,以实现精确的数据管理。综合实验表明,我们的模型优于现有方法,同时具有更高的推理效率。
🔬 方法详解
问题定义:论文旨在解决通用多模态检索中,多模态大型语言模型(MLLM)处理视觉信息时计算成本过高的问题。现有方法在处理大量视觉token时,推理延迟高、内存占用大,限制了MLLM在实际场景中的应用。
核心思路:论文的核心思路是通过视觉token压缩来减少计算量,并设计多阶段训练策略来弥补压缩可能带来的性能损失,甚至进一步提升性能。这种方法旨在在效率和性能之间取得平衡。
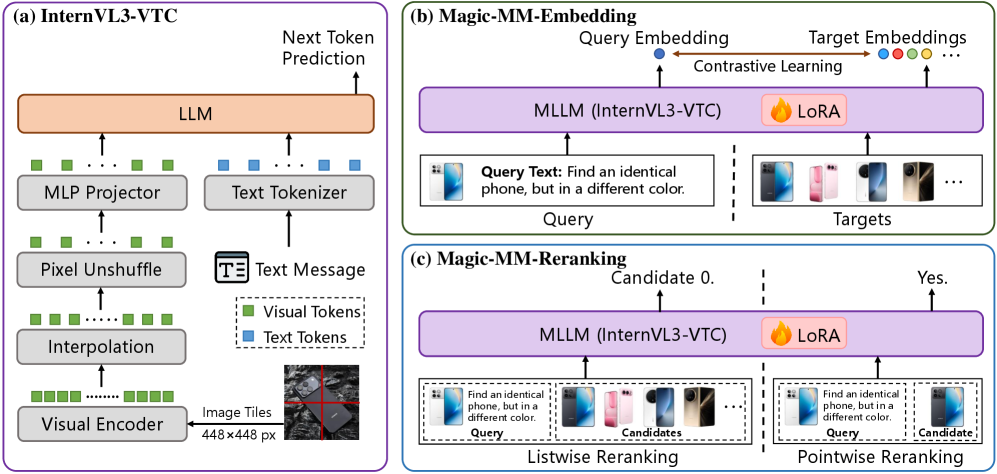
技术框架:Magic-MM-Embedding的整体框架包含两个主要部分:高效的MLLM架构和多阶段渐进式训练策略。高效的MLLM架构通过视觉token压缩模块减少视觉token的数量。多阶段训练策略包括:1) 持续预训练,恢复多模态理解和生成能力;2) 大规模对比预训练和困难负样本挖掘,增强判别能力;3) 任务感知微调,利用MLLM作为裁判进行数据筛选和优化。
关键创新:该论文的关键创新在于将视觉token压缩技术与多阶段训练策略相结合,实现了效率和性能的双重提升。与现有方法相比,Magic-MM-Embedding能够在保证甚至提升性能的前提下,显著降低计算成本。此外,利用MLLM作为裁判进行数据筛选也是一个创新点。
关键设计:视觉token压缩的具体实现方式未知,但其目标是减少输入MLLM的视觉token数量。多阶段训练策略中的损失函数和具体参数设置未知,但对比预训练和困难负样本挖掘是增强判别能力的关键。任务感知微调阶段,MLLM-as-a-Judge的具体实现方式和数据筛选标准未知。
🖼️ 关键图片

📊 实验亮点
论文提出的Magic-MM-Embedding模型在通用多模态嵌入任务上取得了显著的性能提升,超越了现有方法。具体性能数据和对比基线未知,但论文强调了模型在推理效率方面的优势,表明其在实际应用中具有更高的价值。
🎯 应用场景
该研究成果可广泛应用于多模态信息检索、跨模态内容理解、智能推荐系统等领域。通过降低计算成本,使得MLLM能够更高效地处理视觉信息,从而提升用户体验,并推动多模态人工智能技术在实际场景中的应用。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have shown immense promise in universal multimodal retrieval, which aims to find relevant items of various modalities for a given query. But their practical application is often hindered by the substantial computational cost incurred from processing a large number of tokens from visual inputs. In this paper, we propose Magic-MM-Embedding, a series of novel models that achieve both high efficiency and state-of-the-art performance in universal multimodal embedding. Our approach is built on two synergistic pillars: (1) a highly efficient MLLM architecture incorporating visual token compression to drastically reduce inference latency and memory footprint, and (2) a multi-stage progressive training strategy designed to not only recover but significantly boost performance. This coarse-to-fine training paradigm begins with extensive continue pretraining to restore multimodal understanding and generation capabilities, progresses to large-scale contrastive pretraining and hard negative mining to enhance discriminative power, and culminates in a task-aware fine-tuning stage guided by an MLLM-as-a-Judge for precise data curation. Comprehensive experiments show that our model outperforms existing methods by a large margin while being more inference-efficient.