ReGLA: Efficient Receptive-Field Modeling with Gated Linear Attention Network
作者: Junzhou Li, Manqi Zhao, Yilin Gao, Zhiheng Yu, Yin Li, Dongsheng Jiang, Li Xiao
分类: cs.CV
发布日期: 2026-02-05
备注: 11 pages, 4 figures
💡 一句话要点
提出ReGLA:一种基于门控线性注意力网络的高效感受野建模方法,适用于高分辨率图像。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 线性注意力 高分辨率图像 轻量级模型 卷积神经网络 门控机制 多教师蒸馏 高效计算 混合网络
📋 核心要点
- Transformer在高分辨率图像上计算成本高,轻量级模型难以兼顾精度和速度。
- ReGLA结合高效卷积提取局部特征,并使用ReLU门控线性注意力进行全局建模。
- ReGLA在ImageNet上达到80.85%的Top-1精度,并在COCO和ADE20K上超越iFormer。
📝 摘要(中文)
本文提出ReGLA,一系列轻量级混合网络,旨在平衡高分辨率图像上的精度和延迟。该网络结合了高效卷积用于局部特征提取,以及基于ReLU的门控线性注意力用于全局建模。ReGLA包含三个关键创新:高效大感受野(ELRF)模块,用于增强卷积效率并保持大的感受野;ReLU门控调制注意力(RGMA)模块,用于保持线性复杂度的同时增强局部特征表示;以及多教师蒸馏策略,以提升下游任务的性能。大量实验验证了ReGLA的优越性;特别是ReGLA-M在ImageNet-1K(224px)上实现了80.85%的Top-1准确率,在512px分辨率下仅有4.98ms的延迟。此外,ReGLA在下游任务中优于同等规模的iFormer模型,在COCO目标检测上实现了3.1%的AP增益,在ADE20K语义分割上实现了3.6%的mIoU增益,使其成为高分辨率视觉应用的最先进解决方案。
🔬 方法详解
问题定义:现有基于Transformer的模型在高分辨率图像处理中面临计算复杂度高的挑战,尤其是在轻量级模型中,如何在保证精度的同时降低延迟是一个关键问题。传统的Transformer模型通常具有平方级的复杂度,这限制了它们在高分辨率图像上的应用。
核心思路:ReGLA的核心思路是结合卷积神经网络(CNN)和线性注意力机制的优势。利用CNN高效提取局部特征,并使用线性注意力机制进行全局建模,从而在降低计算复杂度的同时,保持模型的表达能力。通过门控机制进一步增强特征表示能力。
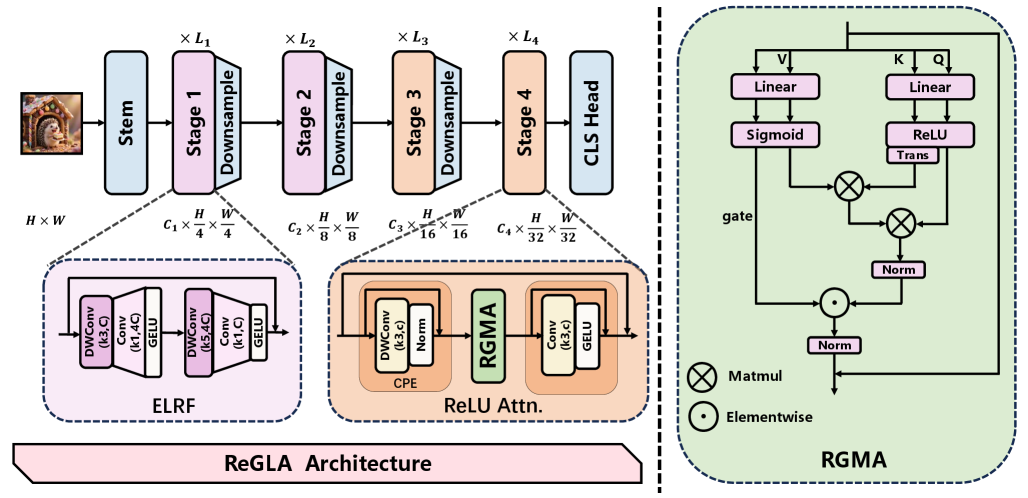
技术框架:ReGLA是一种混合网络,其整体架构包含以下几个主要模块: 1. Efficient Large Receptive Field (ELRF)模块:用于增强卷积的效率,同时保持较大的感受野。 2. ReLU Gated Modulated Attention (RGMA)模块:用于在保持线性复杂度的同时,增强局部特征表示。 3. 多教师蒸馏策略:用于提升模型在下游任务中的性能。 整个网络通过堆叠这些模块,逐步提取图像特征,并最终用于分类、检测或分割等任务。
关键创新:ReGLA的关键创新在于ELRF和RGMA模块的设计。ELRF模块通过高效的卷积操作,在降低计算量的同时,保持了较大的感受野,这使得模型能够更好地捕捉图像中的全局信息。RGMA模块则通过ReLU门控机制,增强了局部特征的表示能力,并且保持了线性复杂度,避免了传统Transformer的平方级复杂度问题。
关键设计: 1. ELRF模块:具体实现细节未知,但其目标是在减少参数量和计算量的同时,保持大的感受野。 2. RGMA模块:使用ReLU作为门控函数,调制注意力权重,增强局部特征的表示能力。具体调制方式未知。 3. 多教师蒸馏:使用多个预训练好的模型作为教师,指导ReGLA模型的训练,从而提升模型在下游任务中的性能。具体蒸馏策略未知。
🖼️ 关键图片

📊 实验亮点
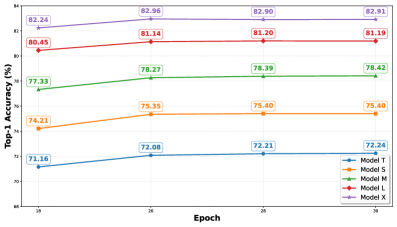
ReGLA-M在ImageNet-1K数据集上达到了80.85%的Top-1准确率,同时在512px分辨率下仅有4.98ms的延迟。在COCO目标检测任务中,ReGLA相比于同等规模的iFormer模型,实现了3.1%的AP提升。在ADE20K语义分割任务中,ReGLA实现了3.6%的mIoU提升。这些结果表明ReGLA在精度和效率上都具有显著优势。
🎯 应用场景
ReGLA适用于需要处理高分辨率图像的视觉应用,例如自动驾驶、医学图像分析、遥感图像处理和高清视频监控等。其高效的计算性能和良好的精度使其能够在资源受限的设备上部署,并为这些领域提供更准确、更快速的图像分析能力,具有广阔的应用前景。
📄 摘要(原文)
Balancing accuracy and latency on high-resolution images is a critical challenge for lightweight models, particularly for Transformer-based architectures that often suffer from excessive latency. To address this issue, we introduce \textbf{ReGLA}, a series of lightweight hybrid networks, which integrates efficient convolutions for local feature extraction with ReLU-based gated linear attention for global modeling. The design incorporates three key innovations: the Efficient Large Receptive Field (ELRF) module for enhancing convolutional efficiency while preserving a large receptive field; the ReLU Gated Modulated Attention (RGMA) module for maintaining linear complexity while enhancing local feature representation; and a multi-teacher distillation strategy to boost performance on downstream tasks. Extensive experiments validate the superiority of ReGLA; particularly the ReGLA-M achieves \textbf{80.85\%} Top-1 accuracy on ImageNet-1K at $224px$, with only \textbf{4.98 ms} latency at $512px$. Furthermore, ReGLA outperforms similarly scaled iFormer models in downstream tasks, achieving gains of \textbf{3.1\%} AP on COCO object detection and \textbf{3.6\%} mIoU on ADE20K semantic segmentation, establishing it as a state-of-the-art solution for high-resolution visual applications.