RFM-Pose:Reinforcement-Guided Flow Matching for Fast Category-Level 6D Pose Estimation
作者: Diya He, Qingchen Liu, Cong Zhang, Jiahu Qin
分类: cs.CV, cs.RO
发布日期: 2026-02-05
备注: This work has been submitted to the IEEE for possible publication
💡 一句话要点
RFM-Pose:基于强化学习引导的Flow Matching,加速类别级6D位姿估计
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 6D位姿估计 类别级位姿估计 Flow Matching 强化学习 生成模型
📋 核心要点
- 类别级6D位姿估计面临旋转对称性歧义问题,现有基于Score的生成模型采样成本高,效率受限。
- RFM-Pose采用Flow Matching生成模型,通过强化学习优化采样策略,联合优化位姿生成和假设评分。
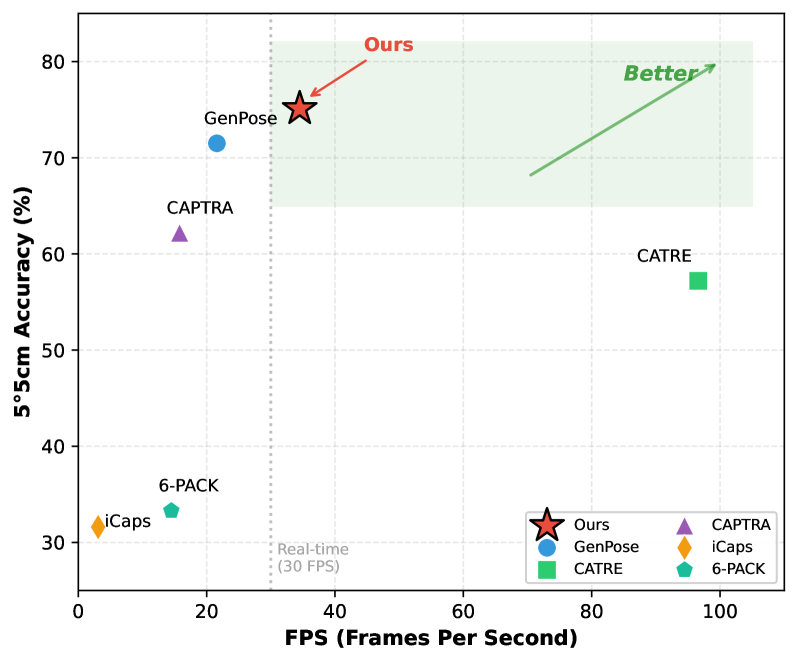
- 在REAL275数据集上,RFM-Pose在显著降低计算成本的同时,实现了良好的位姿估计性能,并可应用于位姿跟踪。
📝 摘要(中文)
本文提出了一种新的框架RFM-Pose,旨在加速类别级6D物体位姿生成,同时主动评估采样的假设。为了提高采样效率,该方法采用Flow Matching生成模型,并沿着从简单先验到位姿分布的最优传输路径生成位姿候选。为了进一步优化这些候选,该方法将Flow Matching采样过程建模为马尔可夫决策过程,并应用近端策略优化来微调采样策略。特别地,该方法将Flow Field解释为可学习的策略,并将估计器映射到价值网络,从而在强化学习框架内实现位姿生成和假设评分的联合优化。在REAL275基准上的实验表明,RFM-Pose在显著降低计算成本的同时,实现了良好的性能。此外,与先前的工作类似,该方法可以很容易地适应于物体位姿跟踪,并在该设置中获得有竞争力的结果。
🔬 方法详解
问题定义:类别级6D位姿估计旨在预测场景中物体的精确三维位置和方向。现有的基于score的生成模型虽然在一定程度上解决了旋转对称性问题,但由于score-based diffusion的高采样成本,其效率仍然有限。因此,如何提高类别级6D位姿估计的效率,同时保持或提高精度,是本文要解决的核心问题。
核心思路:本文的核心思路是利用Flow Matching生成模型来提高采样效率,并使用强化学习来优化采样策略。Flow Matching能够沿着最优传输路径生成位姿候选,从而减少了采样所需的步骤。通过将Flow Matching采样过程建模为马尔可夫决策过程,并使用强化学习进行微调,可以进一步提高采样效率和位姿估计的准确性。
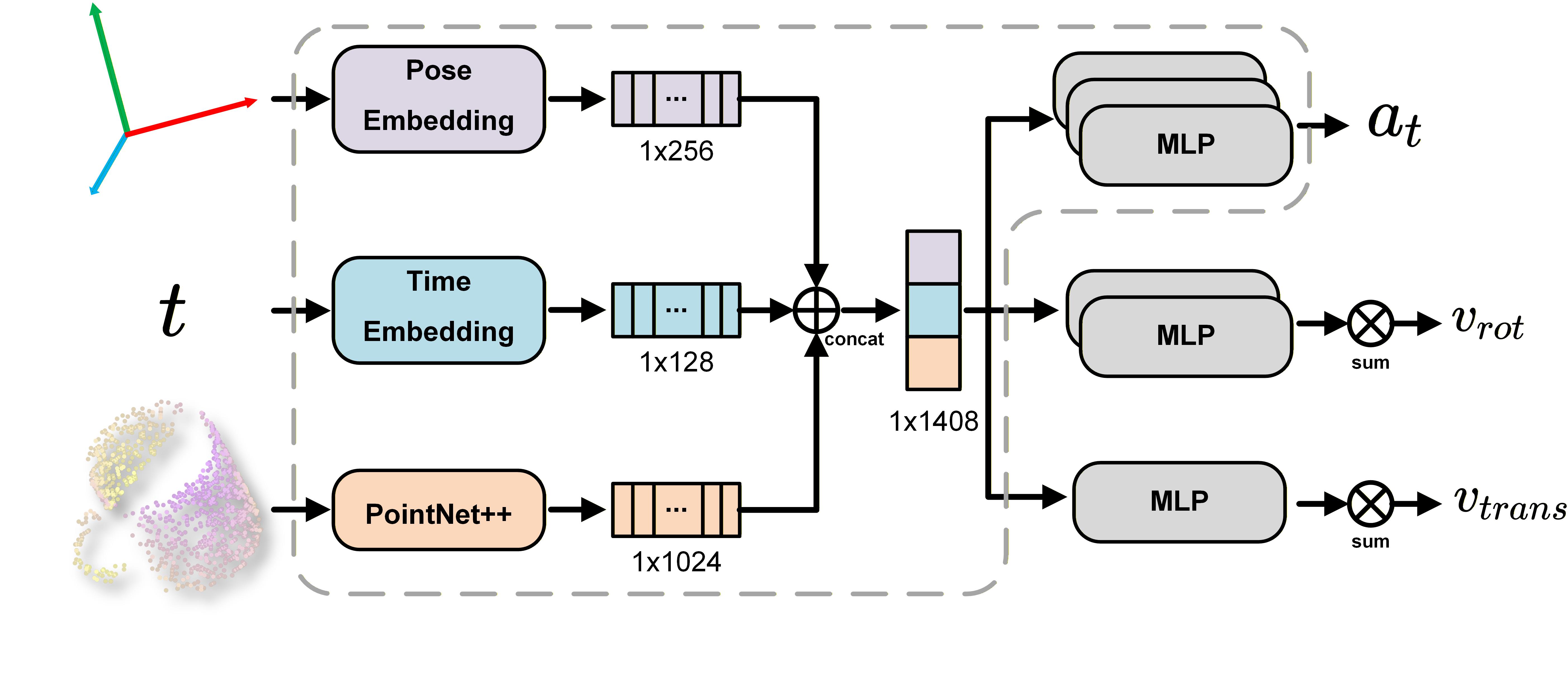
技术框架:RFM-Pose框架主要包含以下几个模块:1) Flow Matching生成模型:用于生成初始的位姿候选;2) 强化学习模块:将Flow Field解释为可学习的策略,并使用近端策略优化(PPO)算法进行微调;3) 价值网络:用于评估生成的位姿候选的质量,并指导强化学习过程。整体流程是先使用Flow Matching生成位姿候选,然后使用强化学习模块对采样策略进行优化,最后使用价值网络对生成的位姿进行评分。
关键创新:本文最重要的技术创新点在于将Flow Matching生成模型与强化学习相结合,实现位姿生成和假设评分的联合优化。通过将Flow Field解释为可学习的策略,并使用强化学习进行微调,可以有效地提高采样效率和位姿估计的准确性。此外,将估计器映射到价值网络,使得可以对生成的位姿候选进行评分,从而进一步提高位姿估计的精度。
关键设计:Flow Matching模型使用最优传输路径进行位姿生成,具体实现细节未知。强化学习模块使用近端策略优化(PPO)算法进行策略优化,具体奖励函数的设计未知。价值网络的设计细节未知,但其作用是评估生成的位姿候选的质量,并指导强化学习过程。
🖼️ 关键图片

📊 实验亮点
RFM-Pose在REAL275基准测试中表现出色,在显著降低计算成本的同时,实现了良好的性能。具体的数据提升和对比基线信息未知,但论文强调了计算成本的显著降低和性能的良好表现。此外,该方法还可应用于物体位姿跟踪,并取得了有竞争力的结果。
🎯 应用场景
该研究成果可广泛应用于虚拟现实、增强现实和机器人等领域。在虚拟现实和增强现实中,精确的6D位姿估计可以提高用户体验,实现更自然的交互。在机器人领域,该技术可以帮助机器人更好地理解和操作物体,从而实现更智能的自动化。
📄 摘要(原文)
Object pose estimation is a fundamental problem in computer vision and plays a critical role in virtual reality and embodied intelligence, where agents must understand and interact with objects in 3D space. Recently, score based generative models have to some extent solved the rotational symmetry ambiguity problem in category level pose estimation, but their efficiency remains limited by the high sampling cost of score-based diffusion. In this work, we propose a new framework, RFM-Pose, that accelerates category-level 6D object pose generation while actively evaluating sampled hypotheses. To improve sampling efficiency, we adopt a flow-matching generative model and generate pose candidates along an optimal transport path from a simple prior to the pose distribution. To further refine these candidates, we cast the flow-matching sampling process as a Markov decision process and apply proximal policy optimization to fine-tune the sampling policy. In particular, we interpret the flow field as a learnable policy and map an estimator to a value network, enabling joint optimization of pose generation and hypothesis scoring within a reinforcement learning framework. Experiments on the REAL275 benchmark demonstrate that RFM-Pose achieves favorable performance while significantly reducing computational cost. Moreover, similar to prior work, our approach can be readily adapted to object pose tracking and attains competitive results in this setting.