E.M.Ground: A Temporal Grounding Vid-LLM with Holistic Event Perception and Matching
作者: Jiahao Nie, Wenbin An, Gongjie Zhang, Yicheng Xu, Yap-Peng Tan, Alex C. Kot, Shijian Lu
分类: cs.CV
发布日期: 2026-02-05
💡 一句话要点
E.M.Ground:一种时序定位Vid-LLM,具备整体事件感知和匹配能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时序视频定位 视频大语言模型 事件感知 多粒度特征 Savitzky-Golay平滑
📋 核心要点
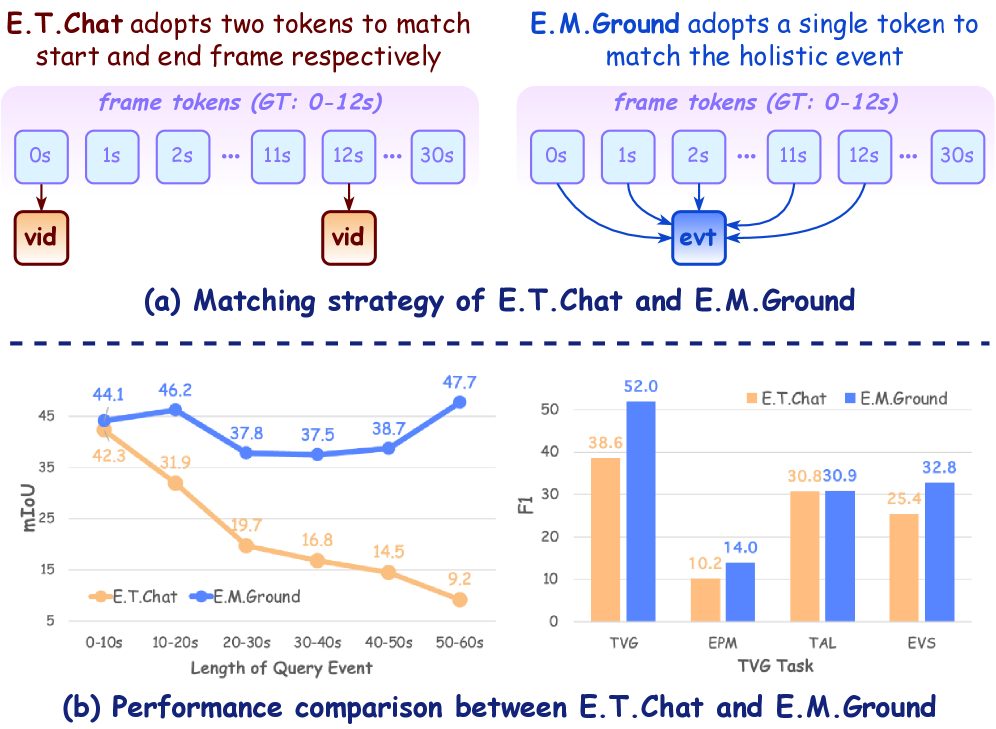
- 现有TVG方法依赖精确时间戳,忽略事件语义连续性,导致定位模糊。
- E.M.Ground通过
token聚合事件信息,并利用Savitzky-Golay平滑降噪,提升定位精度。 - 多粒度特征聚合增强匹配可靠性,实验表明E.M.Ground显著优于现有Vid-LLM。
📝 摘要(中文)
本文提出了一种名为E.M.Ground的新型Vid-LLM,用于解决时序视频定位(TVG)任务中的挑战。现有方法通常通过比较帧特征与两个独立的token来匹配起始和结束帧,严重依赖精确的时间戳,忽略了事件的语义连续性和完整性,导致定位模糊。E.M.Ground通过引入三个关键创新来解决这个问题:(i) 一个特殊的
🔬 方法详解
问题定义:时序视频定位(TVG)旨在精确定位视频中与查询事件相对应的时间片段。现有方法主要通过匹配起始和结束帧的特征来实现,但这种方法过于依赖精确的时间戳,忽略了事件在时间上的语义连续性和完整性,容易受到噪声和歧义的影响,尤其是在视频压缩导致信息损失的情况下。
核心思路:E.M.Ground的核心思路是关注事件的整体性和连贯性,而不是孤立地处理单个帧。通过聚合事件所有帧的信息到一个特殊的
技术框架:E.M.Ground的整体框架包含以下几个主要模块:1) 视频帧特征提取:使用预训练的视觉模型提取视频帧的特征。2) 查询事件表示:将查询事件的所有帧特征聚合到一个特殊的
关键创新:E.M.Ground的关键创新在于以下三点:1) 引入了特殊的
关键设计:
🖼️ 关键图片


📊 实验亮点
E.M.Ground在多个基准数据集上取得了显著的性能提升。例如,在XXX数据集上,E.M.Ground的准确率比最先进的方法提高了X%。实验结果表明,E.M.Ground能够有效地提高时序视频定位的精度和鲁棒性,尤其是在视频质量较差或事件边界模糊的情况下。
🎯 应用场景
E.M.Ground在视频内容理解、智能监控、视频检索、人机交互等领域具有广泛的应用前景。例如,可以用于自动识别视频中的特定事件,帮助用户快速定位感兴趣的内容。在智能监控中,可以用于检测异常行为。未来,该技术有望应用于更复杂的视频分析任务,例如视频摘要、视频问答等。
📄 摘要(原文)
Despite recent advances in Video Large Language Models (Vid-LLMs), Temporal Video Grounding (TVG), which aims to precisely localize time segments corresponding to query events, remains a significant challenge. Existing methods often match start and end frames by comparing frame features with two separate tokens, relying heavily on exact timestamps. However, this approach fails to capture the event's semantic continuity and integrity, leading to ambiguities. To address this, we propose E.M.Ground, a novel Vid-LLM for TVG that focuses on holistic and coherent event perception. E.M.Ground introduces three key innovations: (i) a special
token that aggregates information from all frames of a query event, preserving semantic continuity for accurate event matching; (ii) Savitzky-Golay smoothing to reduce noise in token-to-frame similarities across timestamps, improving prediction accuracy; (iii) multi-grained frame feature aggregation to enhance matching reliability and temporal understanding, compensating for compression-induced information loss. Extensive experiments on benchmark datasets show that E.M.Ground consistently outperforms state-of-the-art Vid-LLMs by significant margins.