GT-SVJ: Generative-Transformer-Based Self-Supervised Video Judge For Efficient Video Reward Modeling
作者: Shivanshu Shekhar, Uttaran Bhattacharya, Raghavendra Addanki, Mehrab Tanjim, Somdeb Sarkhel, Tong Zhang
分类: cs.CV
发布日期: 2026-02-05
💡 一句话要点
提出基于生成Transformer的自监督视频评价模型,高效进行视频奖励建模。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 视频奖励建模 自监督学习 生成模型 能量模型 对比学习 视频质量评估 Transformer 时间建模
📋 核心要点
- 现有基于视觉-语言模型的视频奖励建模方法难以捕捉视频中的细微时间动态。
- 论文提出将视频生成模型转化为能量模型,通过对比学习区分高质量和低质量视频。
- 实验表明,该方法仅需少量人工标注即可在视频质量评估任务上取得领先性能。
📝 摘要(中文)
将视频生成模型与人类偏好对齐仍然具有挑战性。目前的方法依赖于视觉-语言模型(VLMs)进行奖励建模,但这些模型难以捕捉细微的时间动态。我们提出了一种根本不同的方法:将视频生成模型重新用作奖励模型,因为它们本身就设计用于建模时间结构。我们提出了基于生成Transformer的自监督视频评价模型(GT-SVJ),这是一种新颖的评估模型,可将最先进的视频生成模型转换为强大的、具有时间感知能力的奖励模型。我们的关键见解是,生成模型可以被重新表述为能量模型(EBMs),该模型为高质量视频分配低能量,为降质视频分配高能量,从而使其能够通过对比目标以惊人的精度区分视频质量。为了防止模型利用真实视频和生成视频之间的表面差异,我们通过受控的潜在空间扰动设计了具有挑战性的合成负样本视频:时间切片、特征交换和帧洗牌,这些操作模拟了真实但细微的视觉降级。这迫使模型学习有意义的时空特征,而不是琐碎的人工痕迹。GT-SVJ仅使用3万个人工标注,就在GenAI-Bench和MonteBench上实现了最先进的性能,比现有的基于VLM的方法减少了6倍到65倍。
🔬 方法详解
问题定义:论文旨在解决视频奖励建模问题,即如何有效地评估生成视频的质量并使其与人类偏好对齐。现有方法主要依赖于视觉-语言模型,但这些模型在捕捉视频中的时间动态方面存在不足,需要大量人工标注数据。
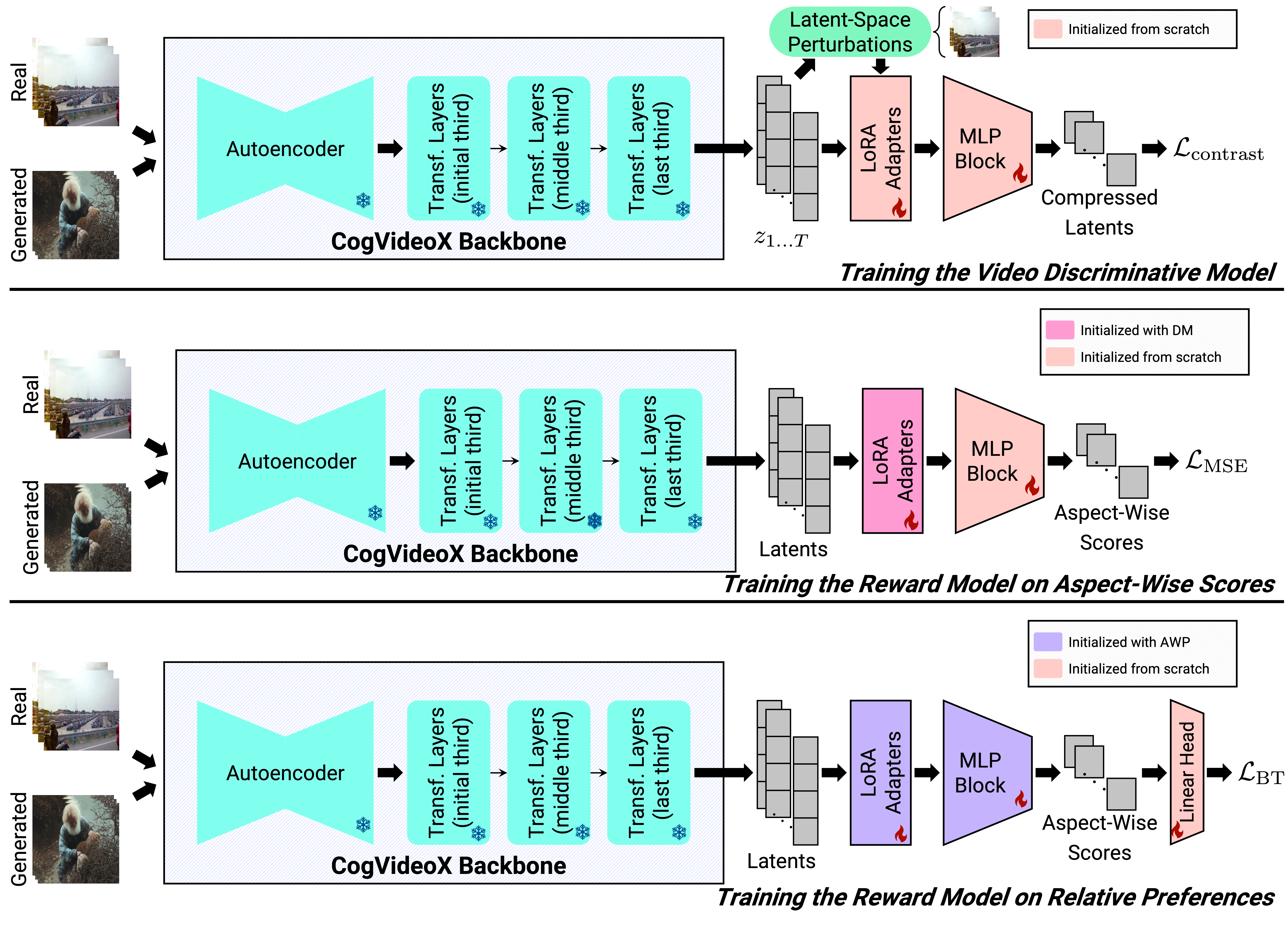
核心思路:论文的核心思路是将视频生成模型重新用作奖励模型。视频生成模型本身就擅长建模视频的时间结构,因此可以将其转化为能量模型,通过区分高质量和低质量视频来评估视频质量。高质量视频被分配低能量,而低质量视频被分配高能量。
技术框架:GT-SVJ模型主要包含以下几个阶段:首先,利用预训练的视频生成模型作为基础架构。然后,将该模型转化为能量模型,并使用对比学习目标进行训练。在训练过程中,模型需要区分真实视频和合成的负样本视频。最后,训练好的能量模型可以用于评估生成视频的质量。
关键创新:论文的关键创新在于将视频生成模型重新用作奖励模型,并设计了一系列具有挑战性的合成负样本视频。这些负样本视频通过时间切片、特征交换和帧洗牌等操作生成,能够模拟真实但细微的视觉降级,从而迫使模型学习有意义的时空特征。
关键设计:在对比学习中,论文采用了InfoNCE损失函数,鼓励模型将真实视频的能量值降低,同时将负样本视频的能量值升高。此外,为了生成高质量的负样本,论文设计了三种扰动策略:时间切片(随机截断视频片段)、特征交换(交换不同视频片段的特征)和帧洗牌(随机打乱视频帧的顺序)。这些策略旨在模拟真实视频中可能出现的各种质量问题。
🖼️ 关键图片


📊 实验亮点
GT-SVJ在GenAI-Bench和MonteBench数据集上取得了最先进的性能,并且仅使用了3万个人工标注,比现有的基于VLM的方法减少了6倍到65倍。这表明该方法在视频奖励建模方面具有更高的效率和更好的性能。
🎯 应用场景
该研究成果可广泛应用于视频生成、视频编辑、视频压缩等领域。通过高效的视频奖励建模,可以更好地指导视频生成模型的训练,生成更符合人类偏好的高质量视频内容。此外,该方法还可以用于视频质量评估、视频监控等领域,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Aligning video generative models with human preferences remains challenging: current approaches rely on Vision-Language Models (VLMs) for reward modeling, but these models struggle to capture subtle temporal dynamics. We propose a fundamentally different approach: repurposing video generative models, which are inherently designed to model temporal structure, as reward models. We present the Generative-Transformer-based Self-Supervised Video Judge (\modelname), a novel evaluation model that transforms state-of-the-art video generation models into powerful temporally-aware reward models. Our key insight is that generative models can be reformulated as energy-based models (EBMs) that assign low energy to high-quality videos and high energy to degraded ones, enabling them to discriminate video quality with remarkable precision when trained via contrastive objectives. To prevent the model from exploiting superficial differences between real and generated videos, we design challenging synthetic negative videos through controlled latent-space perturbations: temporal slicing, feature swapping, and frame shuffling, which simulate realistic but subtle visual degradations. This forces the model to learn meaningful spatiotemporal features rather than trivial artifacts. \modelname achieves state-of-the-art performance on GenAI-Bench and MonteBench using only 30K human-annotations: $6\times$ to $65\times$ fewer than existing VLM-based approaches.