PoseGaussian: Pose-Driven Novel View Synthesis for Robust 3D Human Reconstruction
作者: Ju Shen, Chen Chen, Tam V. Nguyen, Vijayan K. Asari
分类: cs.CV, cs.GR
发布日期: 2026-02-05
💡 一句话要点
提出PoseGaussian,利用姿态引导的高保真人体新视角合成框架
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 新视角合成 人体重建 高斯溅射 姿态引导 时间一致性
📋 核心要点
- 现有方法在处理动态人体新视角合成时,难以有效利用人体姿态信息,导致重建精度和时间一致性不足。
- PoseGaussian框架将人体姿态信息融入几何和时间建模,通过姿态引导的深度细化和时间一致性增强,提升重建质量。
- 实验表明,PoseGaussian在多个数据集上取得了state-of-the-art的性能,并在感知质量和结构精度上均有显著提升。
📝 摘要(中文)
本文提出PoseGaussian,一个姿态引导的高斯溅射框架,用于高保真的人体新视角合成。人体姿态在我们的设计中具有双重作用:作为结构先验,它与颜色编码器融合以细化深度估计;作为时间线索,它由专门的姿态编码器处理,以增强跨帧的时间一致性。这些组件被集成到一个完全可微、端到端可训练的流程中。与先前仅将姿态用作条件或用于扭曲的工作不同,PoseGaussian将姿态信号嵌入到几何和时间阶段,以提高鲁棒性和泛化性。它专门用于解决动态人体场景中固有的挑战,例如铰接运动和严重的自遮挡。值得注意的是,我们的框架实现了100 FPS的实时渲染,保持了标准高斯溅射流程的效率。我们在ZJU-MoCap、THuman2.0和内部数据集上验证了我们的方法,在感知质量和结构精度方面展示了最先进的性能(PSNR 30.86,SSIM 0.979,LPIPS 0.028)。
🔬 方法详解
问题定义:现有的人体新视角合成方法在处理动态场景时,尤其是在存在铰接运动和自遮挡的情况下,难以充分利用人体姿态信息,导致重建结果的几何精度和时间一致性较差。这些方法通常将姿态作为简单的条件输入或用于图像扭曲,无法有效指导三维重建过程。
核心思路:PoseGaussian的核心思路是将人体姿态信息深度融入到高斯溅射框架中,利用姿态作为结构先验来指导深度估计,并作为时间线索来增强时间一致性。通过这种方式,姿态信息不仅被用于图像渲染,还被用于优化三维场景的几何结构和动态变化。
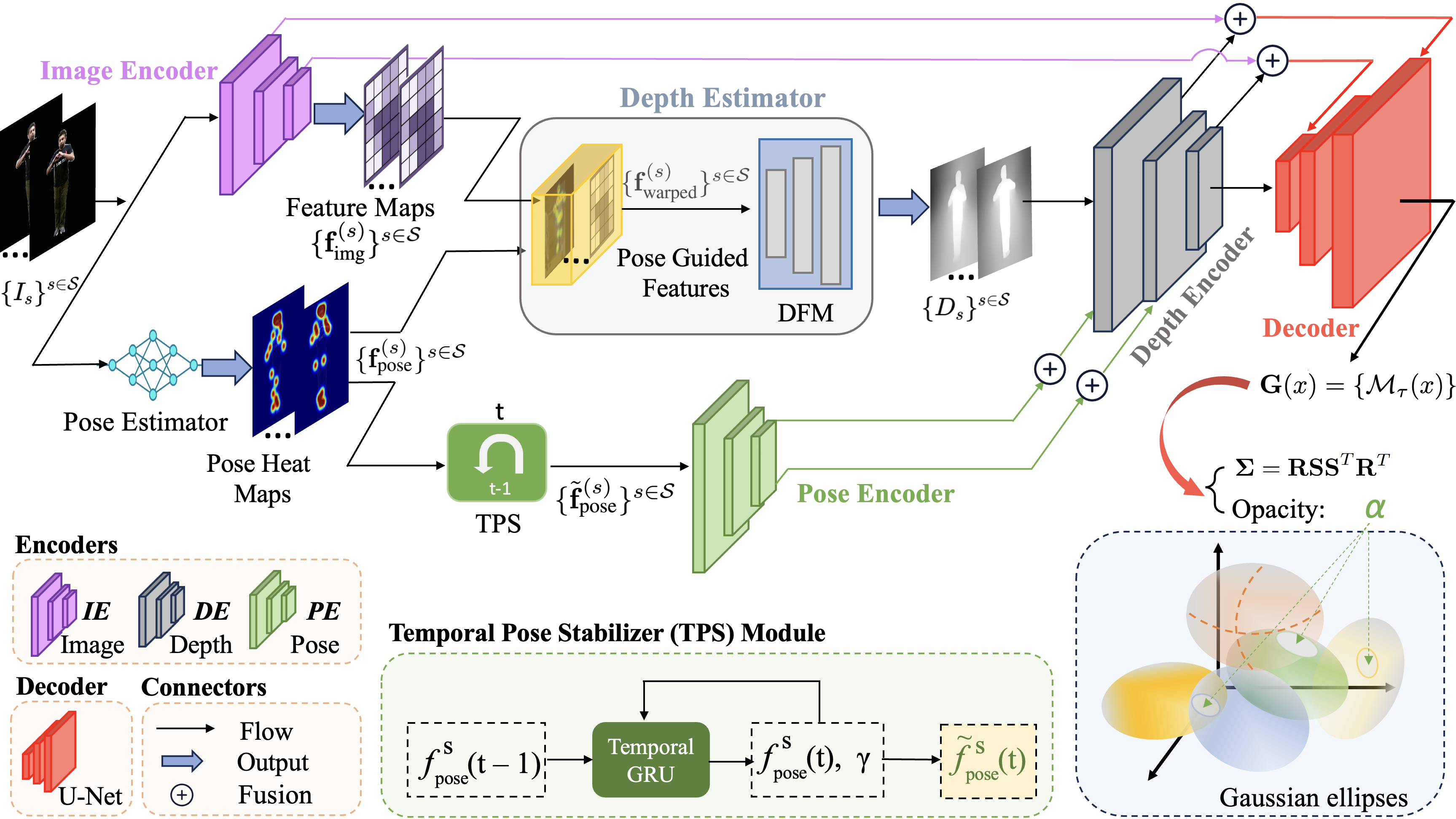
技术框架:PoseGaussian框架包含颜色编码器、姿态编码器和高斯溅射渲染模块。颜色编码器提取图像特征,姿态编码器处理人体姿态信息。姿态信息与颜色特征融合,用于细化深度估计。姿态编码器的输出还用于增强跨帧的时间一致性。整个框架是端到端可训练的。
关键创新:PoseGaussian的关键创新在于将姿态信息嵌入到几何和时间建模的两个关键阶段。与现有方法不同,PoseGaussian不仅仅将姿态作为条件输入,而是利用姿态信息来指导深度估计和时间一致性建模,从而提高了重建的鲁棒性和泛化能力。
关键设计:PoseGaussian使用高斯溅射作为基础渲染方法,并在此基础上引入了姿态引导的深度细化模块和时间一致性增强模块。深度细化模块利用姿态信息来优化高斯分布的深度参数。时间一致性增强模块则利用姿态信息来平滑高斯分布在时间上的变化。损失函数包括图像重建损失、深度一致性损失和时间一致性损失。
🖼️ 关键图片

📊 实验亮点
PoseGaussian在ZJU-MoCap、THuman2.0和内部数据集上进行了验证,取得了state-of-the-art的性能。具体而言,在感知质量和结构精度方面,PoseGaussian的PSNR达到了30.86,SSIM达到了0.979,LPIPS达到了0.028,显著优于现有的方法。此外,PoseGaussian还实现了100 FPS的实时渲染速度。
🎯 应用场景
PoseGaussian具有广泛的应用前景,包括虚拟现实、增强现实、游戏开发、电影制作和远程医疗等领域。它可以用于创建逼真且具有时间一致性的虚拟人体模型,从而提升用户体验和交互性。此外,该技术还可以应用于运动分析、姿态识别和人体行为理解等任务。
📄 摘要(原文)
We propose PoseGaussian, a pose-guided Gaussian Splatting framework for high-fidelity human novel view synthesis. Human body pose serves a dual purpose in our design: as a structural prior, it is fused with a color encoder to refine depth estimation; as a temporal cue, it is processed by a dedicated pose encoder to enhance temporal consistency across frames. These components are integrated into a fully differentiable, end-to-end trainable pipeline. Unlike prior works that use pose only as a condition or for warping, PoseGaussian embeds pose signals into both geometric and temporal stages to improve robustness and generalization. It is specifically designed to address challenges inherent in dynamic human scenes, such as articulated motion and severe self-occlusion. Notably, our framework achieves real-time rendering at 100 FPS, maintaining the efficiency of standard Gaussian Splatting pipelines. We validate our approach on ZJU-MoCap, THuman2.0, and in-house datasets, demonstrating state-of-the-art performance in perceptual quality and structural accuracy (PSNR 30.86, SSIM 0.979, LPIPS 0.028).