Laminating Representation Autoencoders for Efficient Diffusion
作者: Ramón Calvo-González, François Fleuret
分类: cs.CV
发布日期: 2026-02-04
💡 一句话要点
提出 FlatDINO,通过层叠表示自编码器高效压缩 DINOv2 特征用于扩散模型。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 扩散模型 自编码器 特征压缩 图像生成 DINOv2 变分自编码器 计算效率
📋 核心要点
- 现有扩散模型直接处理 DINOv2 等编码器产生的密集 patch 特征时,存在显著的冗余,导致计算成本过高。
- FlatDINO 是一种变分自编码器,通过将高维特征压缩为低维 token 序列,有效降低了扩散模型的计算复杂度。
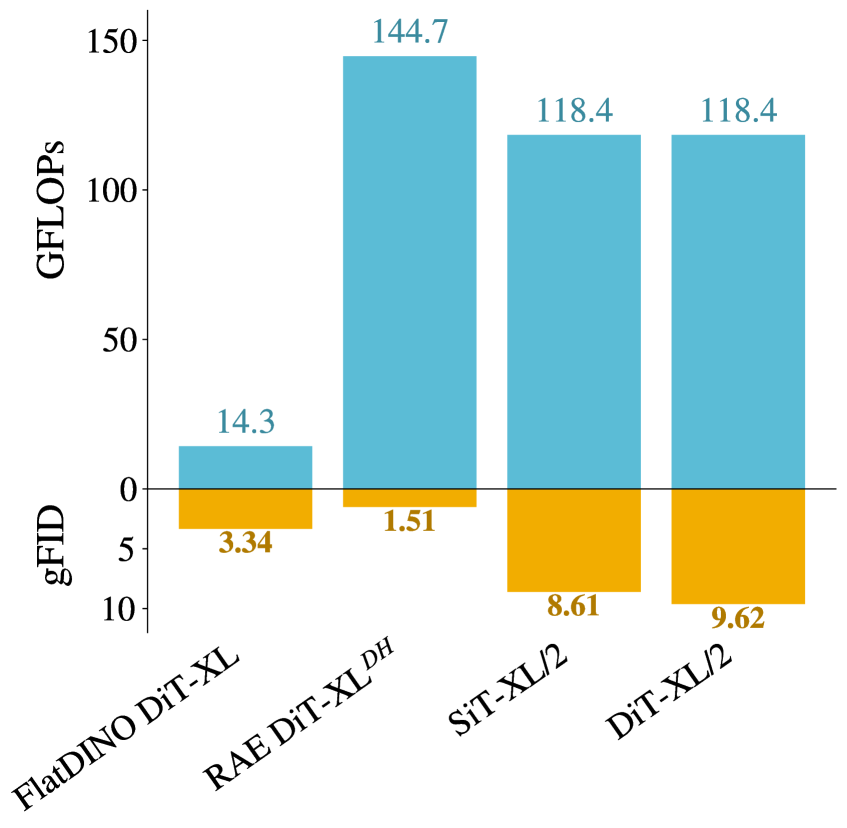
- 实验表明,在 ImageNet 256x256 上,FlatDINO 显著降低了 FLOPs,同时保持了良好的图像生成质量(gFID 1.80)。
📝 摘要(中文)
最近的研究表明,扩散模型可以直接在 SSL patch 特征上操作,而不是在像素空间潜在空间中操作,从而生成高质量的图像。然而,来自 DINOv2 等编码器的密集 patch 网格包含大量的冗余,使得扩散过程不必要地昂贵。我们提出了 FlatDINO,一种变分自编码器,将这种表示压缩成一个只有 32 个连续 token 的一维序列——序列长度减少 8 倍,总维度压缩 48 倍。在 ImageNet 256x256 上,一个在 FlatDINO 潜在空间上训练的 DiT-XL,在使用无分类器指导的情况下,实现了 1.80 的 gFID,同时每次前向传递所需的 FLOPs 减少 8 倍,每个训练步骤所需的 FLOPs 减少高达 4.5 倍(与在未压缩的 DINOv2 特征上进行扩散相比)。这些是初步结果,这项工作正在进行中。
🔬 方法详解
问题定义:论文旨在解决扩散模型在处理高维视觉特征时计算成本过高的问题。现有方法,如直接在 DINOv2 特征上进行扩散,由于特征的冗余性,导致训练和推理效率低下。
核心思路:论文的核心思路是利用自编码器学习一种更紧凑的特征表示,从而降低扩散模型的计算负担。通过压缩 DINOv2 的高维特征,减少扩散模型需要处理的 token 数量,提高效率。
技术框架:FlatDINO 采用变分自编码器(VAE)的框架。首先,编码器将 DINOv2 的 patch 特征映射到低维潜在空间。然后,解码器将潜在空间的表示重构回原始特征空间。扩散模型(DiT-XL)则在 FlatDINO 学习到的潜在空间上进行训练和采样。
关键创新:关键创新在于设计了一种能够有效压缩 DINOv2 特征的自编码器,并将其与扩散模型相结合。与直接在原始 DINOv2 特征上进行扩散相比,FlatDINO 显著降低了计算复杂度,同时保持了良好的生成性能。
关键设计:FlatDINO 将 DINOv2 特征压缩成一个长度为 32 的一维 token 序列。损失函数包括 VAE 的重构损失和 KL 散度损失,用于保证潜在空间的平滑性和可解释性。扩散模型采用 DiT-XL 架构,并在 FlatDINO 的潜在空间上进行训练。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在 ImageNet 256x256 上,使用 FlatDINO 压缩后的特征训练的 DiT-XL 模型,在使用无分类器指导的情况下,实现了 1.80 的 gFID。与直接在未压缩的 DINOv2 特征上进行扩散相比,每次前向传递所需的 FLOPs 减少 8 倍,每个训练步骤所需的 FLOPs 减少高达 4.5 倍。
🎯 应用场景
该研究成果可应用于图像生成、图像编辑、视频生成等领域。通过降低扩散模型的计算成本,可以使其在资源受限的设备上运行,并加速生成过程。此外,该方法还可以推广到其他高维数据的生成任务中,例如音频生成、文本生成等。
📄 摘要(原文)
Recent work has shown that diffusion models can generate high-quality images by operating directly on SSL patch features rather than pixel-space latents. However, the dense patch grids from encoders like DINOv2 contain significant redundancy, making diffusion needlessly expensive. We introduce FlatDINO, a variational autoencoder that compresses this representation into a one-dimensional sequence of just 32 continuous tokens -an 8x reduction in sequence length and 48x compression in total dimensionality. On ImageNet 256x256, a DiT-XL trained on FlatDINO latents achieves a gFID of 1.80 with classifier-free guidance while requiring 8x fewer FLOPs per forward pass and up to 4.5x fewer FLOPs per training step compared to diffusion on uncompressed DINOv2 features. These are preliminary results and this work is in progress.