VISTA-Bench: Do Vision-Language Models Really Understand Visualized Text as Well as Pure Text?
作者: Qing'an Liu, Juntong Feng, Yuhao Wang, Xinzhe Han, Yujie Cheng, Yue Zhu, Haiwen Diao, Yunzhi Zhuge, Huchuan Lu
分类: cs.CV
发布日期: 2026-02-04
备注: 27 pages, 19 figures
🔗 代码/项目: GITHUB
💡 一句话要点
VISTA-Bench:评估视觉语言模型对图像中可视化文本的理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 可视化文本理解 跨模态学习 基准测试 多模态感知
📋 核心要点
- 现有视觉语言模型在处理图像中可视化文本时存在理解能力不足的问题,与处理纯文本相比存在性能差距。
- VISTA-Bench通过对比纯文本和可视化文本的查询,系统性地评估了视觉语言模型对可视化文本的理解能力。
- 实验结果表明,现有模型在处理可视化文本时性能显著下降,且对渲染变化敏感,揭示了模型在模态理解上的局限性。
📝 摘要(中文)
视觉语言模型(VLMs)在跨文本和视觉输入的跨模态理解方面取得了显著的成果,但现有的基准测试主要集中于纯文本查询。在现实场景中,语言也经常以嵌入在图像中的可视化文本形式出现,这就引出了一个问题:当前VLMs是否能以类似的方式处理此类输入请求。我们推出了VISTA-Bench,这是一个系统的基准测试,涵盖了多模态感知、推理和单模态理解等领域。它通过对比纯文本和可视化文本问题,在受控的渲染条件下评估可视化文本理解能力。对20多个具有代表性的VLMs的广泛评估表明,存在明显的模态差距:在纯文本查询中表现良好的模型,当等效的语义内容以可视化文本呈现时,性能通常会大幅下降。这种差距会随着感知难度的增加而进一步扩大,突显了模型对渲染变化的敏感性,尽管语义没有改变。总的来说,VISTA-Bench提供了一个原则性的评估框架,用于诊断这一局限性,并指导在token化的文本和像素之间实现更统一的语言表示。
🔬 方法详解
问题定义:现有视觉语言模型(VLMs)在处理纯文本查询时表现出色,但在现实场景中,文本经常以可视化形式嵌入图像中。现有基准测试主要关注纯文本,忽略了对VLMs理解图像中可视化文本能力的评估。因此,需要一个专门的基准来评估VLMs在处理可视化文本时的性能,并诊断其局限性。
核心思路:VISTA-Bench的核心思路是通过系统性地对比VLMs在处理纯文本和可视化文本时的表现,来评估其对可视化文本的理解能力。通过控制渲染条件,确保语义内容一致,从而突出模型在模态理解上的差异。这种对比评估能够揭示模型在处理不同模态信息时的局限性,并指导模型改进。
技术框架:VISTA-Bench包含多模态感知、推理和单模态理解等多个领域。它通过生成纯文本和对应的可视化文本问题,输入到VLMs中进行回答。然后,对比模型在两种模态下的表现,评估其对可视化文本的理解能力。该框架还考虑了渲染变化对模型性能的影响,通过改变字体、颜色、大小等渲染参数,评估模型对感知难度的敏感性。
关键创新:VISTA-Bench的关键创新在于它首次系统性地评估了VLMs对图像中可视化文本的理解能力。与现有基准测试主要关注纯文本不同,VISTA-Bench专门针对可视化文本设计,能够更全面地评估VLMs的跨模态理解能力。此外,VISTA-Bench还考虑了渲染变化对模型性能的影响,能够更深入地分析模型在处理不同感知难度下的表现。
关键设计:VISTA-Bench的关键设计包括:1) 受控的渲染条件,确保纯文本和可视化文本的语义内容一致;2) 多样化的渲染参数,包括字体、颜色、大小等,以评估模型对感知难度的敏感性;3) 多领域的评估任务,涵盖多模态感知、推理和单模态理解等,以全面评估模型的理解能力;4) 详细的性能指标,用于量化模型在不同模态下的表现。
🖼️ 关键图片


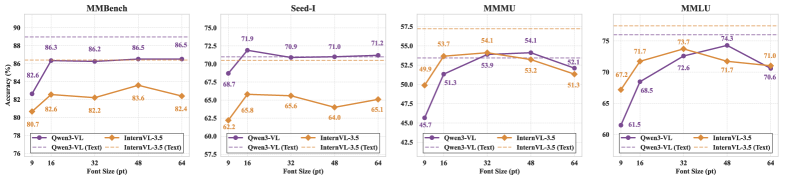
📊 实验亮点
VISTA-Bench对20多个代表性VLMs进行了广泛评估,结果表明,模型在处理可视化文本时性能显著下降。例如,在某些任务上,模型在可视化文本上的准确率比在纯文本上低20%以上。此外,实验还发现,模型对渲染变化非常敏感,即使语义内容不变,渲染参数的微小变化也会导致性能大幅下降。这些结果表明,现有VLMs在处理可视化文本方面存在明显的局限性。
🎯 应用场景
VISTA-Bench的研究成果可以应用于提升视觉语言模型在实际场景中的应用能力,例如文档理解、场景文本识别、图像检索等。通过提高模型对图像中可视化文本的理解能力,可以使其更好地理解真实世界的复杂场景,从而在智能客服、自动驾驶、智能家居等领域发挥更大的作用。未来,该研究可以促进更鲁棒、更通用的视觉语言模型的发展。
📄 摘要(原文)
Vision-Language Models (VLMs) have achieved impressive performance in cross-modal understanding across textual and visual inputs, yet existing benchmarks predominantly focus on pure-text queries. In real-world scenarios, language also frequently appears as visualized text embedded in images, raising the question of whether current VLMs handle such input requests comparably. We introduce VISTA-Bench, a systematic benchmark from multimodal perception, reasoning, to unimodal understanding domains. It evaluates visualized text understanding by contrasting pure-text and visualized-text questions under controlled rendering conditions. Extensive evaluation of over 20 representative VLMs reveals a pronounced modality gap: models that perform well on pure-text queries often degrade substantially when equivalent semantic content is presented as visualized text. This gap is further amplified by increased perceptual difficulty, highlighting sensitivity to rendering variations despite unchanged semantics. Overall, VISTA-Bench provides a principled evaluation framework to diagnose this limitation and to guide progress toward more unified language representations across tokenized text and pixels. The source dataset is available at https://github.com/QingAnLiu/VISTA-Bench.