AGILE: Hand-Object Interaction Reconstruction from Video via Agentic Generation
作者: Jin-Chuan Shi, Binhong Ye, Tao Liu, Junzhe He, Yangjinhui Xu, Xiaoyang Liu, Zeju Li, Hao Chen, Chunhua Shen
分类: cs.CV, cs.GR, cs.RO
发布日期: 2026-02-04
备注: 11 pages
💡 一句话要点
AGILE:通过Agentic生成从视频中重建手-物交互
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 手-物交互重建 Agentic生成 视觉-语言模型 姿态估计 机器人仿真
📋 核心要点
- 现有方法在严重遮挡下重建手-物交互时,依赖神经渲染易产生碎片化几何体,且依赖SfM初始化易失败。
- AGILE框架采用Agentic生成范式,利用视觉-语言模型引导生成完整物体网格,并提出鲁棒的锚定和跟踪策略。
- 实验表明,AGILE在HO3D、DexYCB和真实场景视频上,相比基线方法,在全局几何精度和鲁棒性上均有提升。
📝 摘要(中文)
从单目视频中重建动态手-物交互对于灵巧操作数据收集以及为机器人和VR创建逼真的数字孪生至关重要。然而,当前方法面临两个主要障碍:(1)依赖神经渲染通常会在严重遮挡下产生碎片化、非仿真就绪的几何体;(2)依赖脆弱的运动结构(SfM)初始化导致在真实场景视频中频繁失败。为了克服这些限制,我们引入AGILE,一个鲁棒的框架,它将交互学习的范式从重建转变为agentic生成。首先,我们采用一个agentic流程,其中视觉-语言模型(VLM)引导生成模型合成一个完整的、水密的物体网格,具有高保真纹理,独立于视频遮挡。其次,完全绕过脆弱的SfM,我们提出了一种鲁棒的锚定和跟踪策略。我们使用基础模型在单个交互开始帧初始化物体姿态,并通过利用我们生成的资产和视频观察之间的强视觉相似性,在时间上传播它。最后,一个接触感知优化集成了语义、几何和交互稳定性约束,以强制物理合理性。在HO3D、DexYCB和真实场景视频上的大量实验表明,AGILE在全局几何精度方面优于基线,同时在现有技术经常崩溃的具有挑战性的序列上表现出卓越的鲁棒性。通过优先考虑物理有效性,我们的方法产生仿真就绪的资产,并通过机器人应用的真实到仿真重定向进行验证。
🔬 方法详解
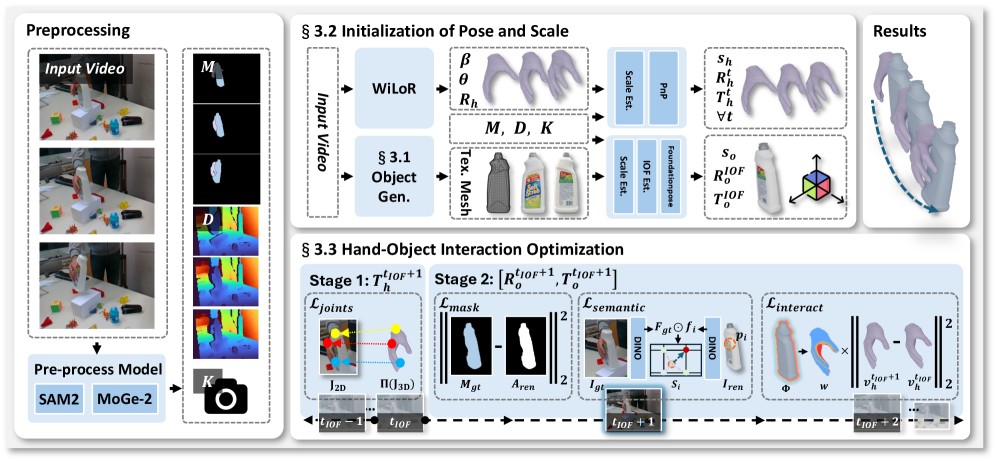
问题定义:论文旨在解决从单目视频中鲁棒且精确地重建动态手-物交互的问题。现有方法主要痛点在于:1) 依赖神经渲染,在遮挡严重的情况下容易产生不完整的几何体,难以直接用于仿真;2) 依赖于脆弱的Structure-from-Motion (SfM) 初始化,在真实场景视频中容易失败,导致重建结果不稳定。
核心思路:AGILE的核心思路是将重建问题转化为一个agentic生成问题。不再依赖于从视频中直接推断几何信息,而是利用视觉-语言模型(VLM)引导生成模型,生成一个完整、水密、具有高保真纹理的物体网格。同时,采用一种鲁棒的锚定和跟踪策略,避免使用容易出错的SfM初始化。这样设计的目的是为了提高重建的鲁棒性和几何完整性,使其更适用于仿真环境。
技术框架:AGILE的整体框架包含以下几个主要模块: 1. Agentic Object Generation: 使用VLM引导生成模型,生成高质量的物体网格。 2. Robust Anchor-and-Track: 在交互开始帧初始化物体姿态,然后利用视觉相似性进行时间上的姿态跟踪。 3. Contact-Aware Optimization: 结合语义、几何和交互稳定性约束,对重建结果进行优化,保证物理合理性。
关键创新:AGILE最重要的技术创新点在于其agentic生成范式和鲁棒的姿态初始化与跟踪策略。与现有方法相比,AGILE不再依赖于从视频中直接重建几何信息,而是通过生成的方式获得完整的物体模型,从而避免了遮挡带来的问题。同时,通过锚定和跟踪策略,避免了对脆弱的SfM初始化的依赖,提高了算法的鲁棒性。
关键设计: 1. VLM引导的物体生成: 具体使用的VLM模型和生成模型类型未知,但其作用是根据视频内容生成高质量的物体网格。 2. 锚定和跟踪策略: 使用基础模型初始化物体姿态,并利用生成的物体网格与视频帧之间的视觉相似性进行姿态跟踪。具体相似性度量方式未知。 3. 接触感知优化: 损失函数包含语义损失、几何损失和交互稳定性损失,以保证重建结果的物理合理性。具体损失函数形式未知。
🖼️ 关键图片


📊 实验亮点
AGILE在HO3D、DexYCB和真实场景视频上进行了广泛的实验,结果表明AGILE在全局几何精度方面优于基线方法。尤其是在现有技术容易崩溃的具有挑战性的序列上,AGILE表现出卓越的鲁棒性。通过真实到仿真重定向的验证,证明了AGILE生成的资产可以直接用于机器人仿真,具有很高的实用价值。具体的性能提升数据未知。
🎯 应用场景
AGILE的研究成果可广泛应用于机器人灵巧操作、虚拟现实(VR)和增强现实(AR)等领域。通过从视频中重建逼真的手-物交互,可以为机器人提供高质量的训练数据,提高其操作能力。在VR/AR中,可以创建更真实、更具交互性的虚拟环境,提升用户体验。此外,该技术还可用于动画制作、游戏开发等领域,具有广阔的应用前景。
📄 摘要(原文)
Reconstructing dynamic hand-object interactions from monocular videos is critical for dexterous manipulation data collection and creating realistic digital twins for robotics and VR. However, current methods face two prohibitive barriers: (1) reliance on neural rendering often yields fragmented, non-simulation-ready geometries under heavy occlusion, and (2) dependence on brittle Structure-from-Motion (SfM) initialization leads to frequent failures on in-the-wild footage. To overcome these limitations, we introduce AGILE, a robust framework that shifts the paradigm from reconstruction to agentic generation for interaction learning. First, we employ an agentic pipeline where a Vision-Language Model (VLM) guides a generative model to synthesize a complete, watertight object mesh with high-fidelity texture, independent of video occlusions. Second, bypassing fragile SfM entirely, we propose a robust anchor-and-track strategy. We initialize the object pose at a single interaction onset frame using a foundation model and propagate it temporally by leveraging the strong visual similarity between our generated asset and video observations. Finally, a contact-aware optimization integrates semantic, geometric, and interaction stability constraints to enforce physical plausibility. Extensive experiments on HO3D, DexYCB, and in-the-wild videos reveal that AGILE outperforms baselines in global geometric accuracy while demonstrating exceptional robustness on challenging sequences where prior art frequently collapses. By prioritizing physical validity, our method produces simulation-ready assets validated via real-to-sim retargeting for robotic applications.