A labeled dataset of simulated phlebotomy procedures for medical AI: polygon annotations for object detection and human-object interaction
作者: Raúl Jiménez Cruz, César Torres-Huitzil, Marco Franceschetti, Ronny Seiger, Luciano García-Bañuelos, Barbara Weber
分类: cs.CV
发布日期: 2026-02-04
💡 一句话要点
构建模拟静脉采血数据集,用于医学AI中物体检测与人机交互研究
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction)
关键词: 静脉采血 医学图像 物体检测 人机交互 深度学习 数据集 医学AI
📋 核心要点
- 现有医学培训缺乏自动化工具,难以提供个性化和实时的反馈,影响培训效果。
- 本研究构建了一个带标签的静脉采血模拟数据集,包含多种医疗工具和人机交互场景,为AI辅助医学培训提供数据基础。
- 该数据集包含高质量的图像和精确的多边形标注,并划分了训练、验证和测试集,方便研究人员使用。
📝 摘要(中文)
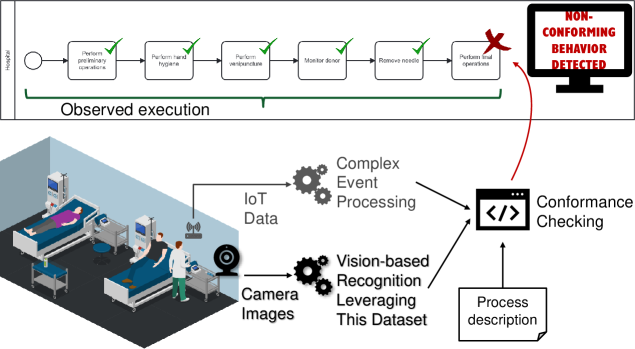
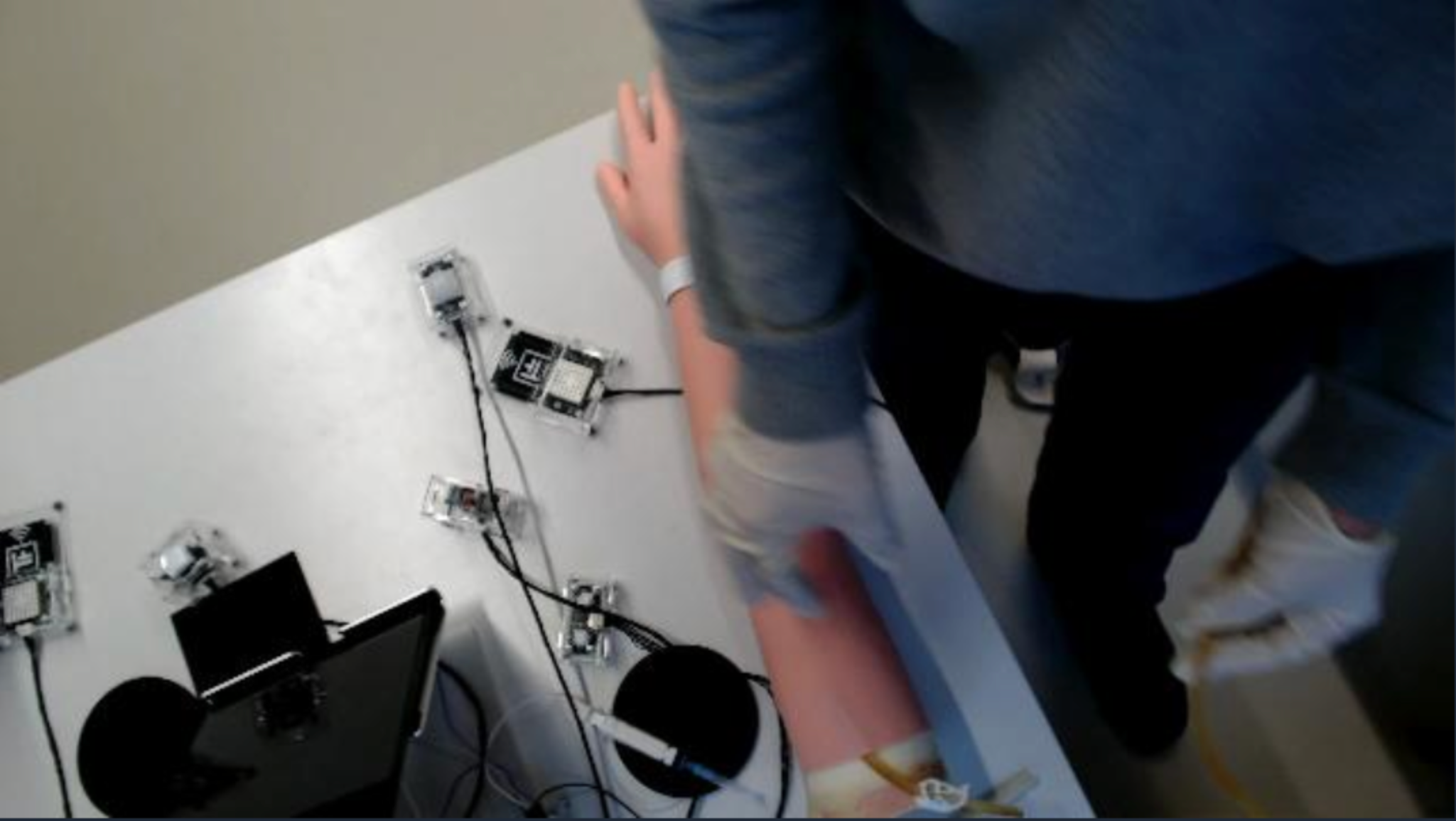
本文介绍了一个包含11884张带标签图像的数据集,该数据集记录了在训练手臂上进行的模拟静脉采血过程。图像是从受控条件下录制的高清视频中提取的,并使用结构相似性指数测量(SSIM)过滤进行处理,以减少冗余。在帧选择之前,对所有视频应用了自动面部匿名化步骤。每张图像都包含五个医学相关类别的多边形注释:注射器、橡皮筋、消毒湿巾、手套和训练手臂。注释以与现代物体检测框架(例如YOLOv8)兼容的分割格式导出,确保了广泛的可用性。该数据集被划分为训练集(70%)、验证集(15%)和测试集(15%),旨在推进医学培训自动化和人机交互领域的研究。它支持多种应用,包括静脉采血工具检测、程序步骤识别、工作流程分析、一致性检查以及开发为医学学员提供结构化反馈的教育系统。数据和随附的标签文件可在Zenodo上公开获取。
🔬 方法详解
问题定义:现有医学培训,特别是静脉采血等操作,依赖于人工指导,效率低且难以标准化。缺乏高质量、带标注的数据集,阻碍了利用人工智能技术进行自动化培训和评估的研究进展。现有方法难以实现对医疗工具的精确检测和人机交互行为的准确理解。
核心思路:本研究的核心思路是构建一个大规模、高质量的模拟静脉采血数据集,该数据集包含丰富的图像和精确的标注,涵盖了静脉采血过程中的关键对象和交互行为。通过提供这样的数据集,可以促进基于深度学习的物体检测和人机交互模型的发展,从而实现自动化医学培训。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 录制高清视频:在受控条件下录制模拟静脉采血过程的高清视频。2) 图像提取与过滤:从视频中提取图像帧,并使用结构相似性指数测量(SSIM)过滤,以减少冗余。3) 面部匿名化:对所有视频应用自动面部匿名化步骤,以保护隐私。4) 多边形标注:使用专业工具对图像中的关键对象(注射器、橡皮筋、消毒湿巾、手套和训练手臂)进行多边形标注。5) 数据集划分:将数据集划分为训练集(70%)、验证集(15%)和测试集(15%)。
关键创新:该研究的关键创新在于构建了一个专门针对模拟静脉采血过程的高质量、带标注的数据集。与现有的医学图像数据集相比,该数据集更加关注人机交互行为,并提供了精确的多边形标注,这使得研究人员可以更好地训练物体检测和人机交互模型。此外,该数据集还采用了结构相似性指数测量(SSIM)过滤和面部匿名化等技术,以提高数据质量和保护隐私。
关键设计:数据集包含11884张图像,涵盖了静脉采血过程中的各种场景和角度。标注采用多边形标注,可以精确地描述对象的形状和位置。数据集被划分为训练集、验证集和测试集,方便研究人员进行模型训练和评估。标注格式与YOLOv8等现代物体检测框架兼容,易于使用。
🖼️ 关键图片

📊 实验亮点
该数据集包含11884张带多边形标注的图像,涵盖了五个医学相关类别。通过结构相似性指数测量(SSIM)过滤减少了数据冗余,并进行了面部匿名化处理,保证了数据质量和隐私。数据集划分合理,方便模型训练和评估。标注格式与YOLOv8等主流框架兼容,易于使用。
🎯 应用场景
该数据集可应用于医学培训自动化、人机交互研究、医疗机器人等领域。通过训练AI模型,可以实现静脉采血工具的自动检测、程序步骤的自动识别、工作流程的自动分析以及一致性检查。此外,还可以开发为医学学员提供结构化反馈的教育系统,提高培训效率和质量。该数据集的发布将促进医学AI领域的发展,并为未来的医疗应用提供新的可能性。
📄 摘要(原文)
This data article presents a dataset of 11,884 labeled images documenting a simulated blood extraction (phlebotomy) procedure performed on a training arm. Images were extracted from high-definition videos recorded under controlled conditions and curated to reduce redundancy using Structural Similarity Index Measure (SSIM) filtering. An automated face-anonymization step was applied to all videos prior to frame selection. Each image contains polygon annotations for five medically relevant classes: syringe, rubber band, disinfectant wipe, gloves, and training arm. The annotations were exported in a segmentation format compatible with modern object detection frameworks (e.g., YOLOv8), ensuring broad usability. This dataset is partitioned into training (70%), validation (15%), and test (15%) subsets and is designed to advance research in medical training automation and human-object interaction. It enables multiple applications, including phlebotomy tool detection, procedural step recognition, workflow analysis, conformance checking, and the development of educational systems that provide structured feedback to medical trainees. The data and accompanying label files are publicly available on Zenodo.