Understanding Degradation with Vision Language Model
作者: Guanzhou Lan, Chenyi Liao, Yuqi Yang, Qianli Ma, Zhigang Wang, Dong Wang, Bin Zhao, Xuelong Li
分类: cs.CV
发布日期: 2026-02-04
备注: 17 pages
💡 一句话要点
提出DU-VLM,用于理解图像退化并实现高质量图像复原。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像退化理解 视觉语言模型 自回归预测 图像恢复 零样本控制
📋 核心要点
- 现有视觉-语言模型在理解图像退化背后的物理参数方面存在不足,无法准确建模退化过程。
- 提出DU-VLM,通过将退化理解定义为分层结构化预测任务,并采用自回归的token预测范式统一不同子任务。
- DU-VLM在准确性和鲁棒性方面显著优于通用基线,并可作为预训练扩散模型的零样本控制器,实现高质量图像恢复。
📝 摘要(中文)
理解视觉退化是计算机视觉中一个关键但具有挑战性的问题。虽然最近的视觉-语言模型(VLMs)擅长定性描述,但它们在理解图像退化背后的参数物理原理方面往往不足。本文将退化理解重新定义为一个分层结构化预测任务,需要同时估计退化类型、参数键及其连续物理值。尽管这些子任务在不同的空间中运行,但我们证明了它们可以在一个自回归的下一个token预测范式下统一起来,其误差受值空间量化网格的限制。基于这一洞察,我们引入了DU-VLM,这是一个多模态链式思考模型,通过监督微调和使用结构化奖励的强化学习进行训练。此外,我们表明DU-VLM可以作为预训练扩散模型的零样本控制器,从而无需微调生成骨干即可实现高保真图像恢复。我们还引入了DU-110k,一个包含11万个带有grounded物理注释的干净-退化图像对的大规模数据集。大量的实验表明,我们的方法在准确性和鲁棒性方面都显著优于通用基线,并表现出对未见分布的泛化能力。
🔬 方法详解
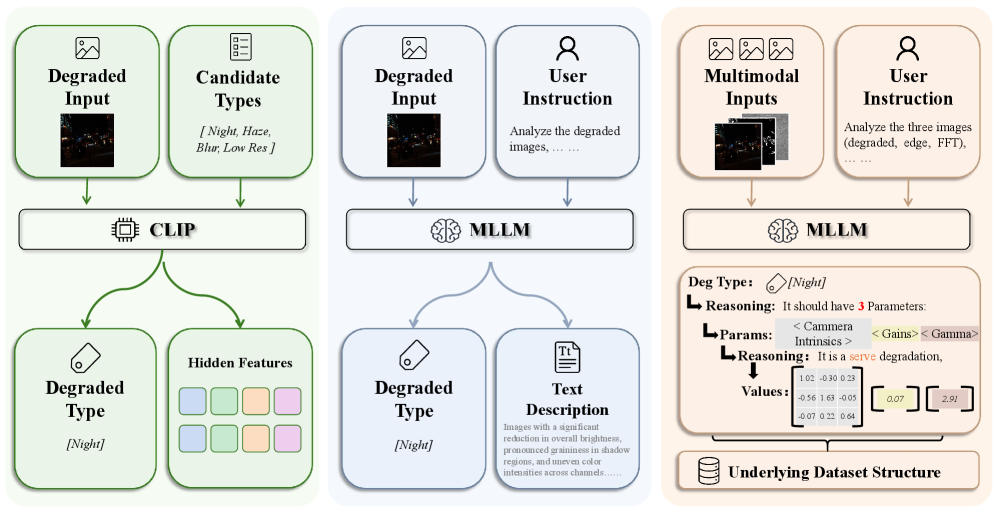
问题定义:论文旨在解决视觉退化理解问题,即如何准确地识别图像中存在的退化类型,并估计其对应的物理参数。现有方法,特别是通用的视觉-语言模型,虽然可以进行定性描述,但在理解退化过程背后的参数化物理机制方面存在不足,无法进行精确的建模和控制。
核心思路:论文的核心思路是将退化理解问题转化为一个分层结构化的预测任务,包括退化类型识别、参数键预测和连续物理值估计三个子任务。关键在于将这三个子任务统一到一个自回归的下一个token预测框架中,从而利用语言模型的强大生成能力来建模退化过程。
技术框架:DU-VLM的整体框架是一个多模态的链式思考模型。它首先接收退化图像作为输入,然后通过视觉编码器提取图像特征。接着,模型利用语言模型进行自回归的token预测,依次预测退化类型、参数键和参数值。模型通过监督微调和强化学习进行训练,其中强化学习使用结构化的奖励函数,鼓励模型生成准确的退化描述。
关键创新:最重要的创新点在于将退化理解问题转化为一个统一的自回归token预测任务。这种方法允许模型利用语言模型的先验知识和强大的生成能力,从而更准确地理解和建模复杂的退化过程。此外,DU-VLM还可以作为预训练扩散模型的零样本控制器,无需额外的微调即可实现高质量的图像恢复。
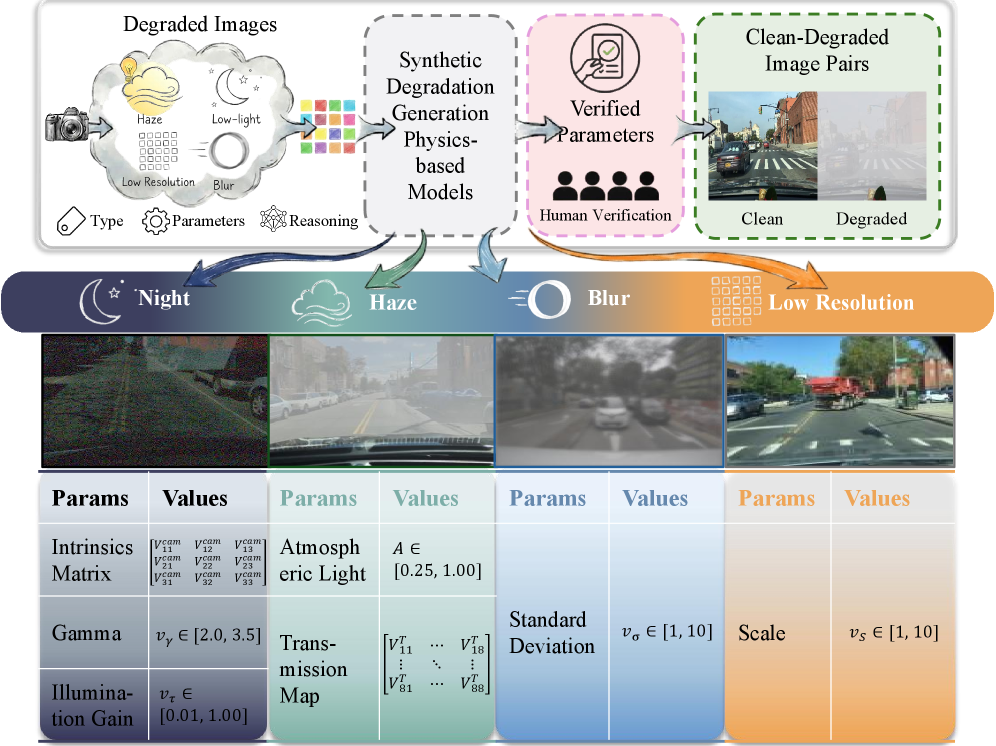
关键设计:DU-VLM的关键设计包括:1) 分层结构化的预测任务定义,将退化理解分解为三个可控的子任务;2) 自回归的token预测框架,利用语言模型建模退化过程;3) 结构化的奖励函数,在强化学习中引导模型生成准确的退化描述;4) 大规模数据集DU-110k,提供充足的训练数据和grounded物理注释。
🖼️ 关键图片

📊 实验亮点
DU-VLM在退化理解任务上显著优于通用基线,在准确性和鲁棒性方面均有提升。DU-VLM能够作为预训练扩散模型的零样本控制器,实现高保真图像恢复,无需对生成骨干进行微调。论文还构建了一个包含11万个图像对的大规模数据集DU-110k,为相关研究提供了宝贵资源。
🎯 应用场景
该研究成果可应用于多种图像处理和计算机视觉任务,例如图像修复、图像增强、图像质量评估等。通过准确理解图像退化类型和参数,可以更有效地去除图像噪声、模糊等伪影,提高图像质量和视觉效果。此外,该技术还可用于自动驾驶、医学影像分析等领域,提升算法的鲁棒性和准确性。
📄 摘要(原文)
Understanding visual degradations is a critical yet challenging problem in computer vision. While recent Vision-Language Models (VLMs) excel at qualitative description, they often fall short in understanding the parametric physics underlying image degradations. In this work, we redefine degradation understanding as a hierarchical structured prediction task, necessitating the concurrent estimation of degradation types, parameter keys, and their continuous physical values. Although these sub-tasks operate in disparate spaces, we prove that they can be unified under one autoregressive next-token prediction paradigm, whose error is bounded by the value-space quantization grid. Building on this insight, we introduce DU-VLM, a multimodal chain-of-thought model trained with supervised fine-tuning and reinforcement learning using structured rewards. Furthermore, we show that DU-VLM can serve as a zero-shot controller for pre-trained diffusion models, enabling high-fidelity image restoration without fine-tuning the generative backbone. We also introduce \textbf{DU-110k}, a large-scale dataset comprising 110,000 clean-degraded pairs with grounded physical annotations. Extensive experiments demonstrate that our approach significantly outperforms generalist baselines in both accuracy and robustness, exhibiting generalization to unseen distributions.