S-MUSt3R: Sliding Multi-view 3D Reconstruction
作者: Leonid Antsfeld, Boris Chidlovskii, Yohann Cabon, Vincent Leroy, Jerome Revaud
分类: cs.CV, cs.RO
发布日期: 2026-02-04
备注: 8 pages, 5 figures, 5 tables
💡 一句话要点
S-MUSt3R:滑动多视角3D重建,扩展单目3D重建基础模型至大规模RGB流
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 单目3D重建 基础模型 SLAM 序列分割 回环优化
📋 核心要点
- 现有3D视觉基础模型在处理大规模RGB流3D重建时面临内存限制的挑战。
- S-MUSt3R通过序列分割、分割对齐和轻量级回环优化,有效解决了基础模型的可扩展性问题。
- 实验表明,S-MUSt3R在长RGB序列上实现了准确一致的3D重建,性能与传统方法相当。
📝 摘要(中文)
本文提出S-MUSt3R,一个简单高效的流水线,旨在扩展基础模型在单目3D重建中的应用范围。该方法通过序列分割、分割对齐和轻量级回环优化策略,解决了基础模型在大规模重建中面临的内存瓶颈。无需模型重训练,S-MUSt3R即可受益于MUSt3R模型强大的3D重建能力,并在轨迹和重建性能上与具有更复杂架构的传统方法相媲美。在TUM、7-Scenes和机器人导航数据集上的评估表明,S-MUSt3R能够成功处理长RGB序列,并生成准确且一致的3D重建结果。该研究突显了利用MUSt3R模型在真实场景中进行可扩展单目3D场景重建的潜力,尤其是在直接在度量空间中进行预测方面具有重要优势。
🔬 方法详解
问题定义:论文旨在解决单目视觉3D重建中,现有基础模型因内存限制难以处理大规模RGB视频流的问题。传统方法虽然可以处理大规模场景,但通常架构复杂,且难以直接预测度量空间下的3D结构。
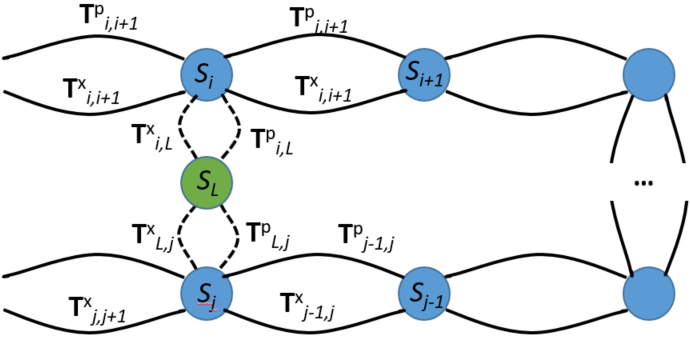
核心思路:论文的核心思路是将长序列分割成多个短序列片段,分别利用MUSt3R模型进行3D重建,然后通过对齐这些片段,并进行轻量级的回环优化,最终得到全局一致的3D重建结果。这种分而治之的策略有效降低了内存需求,使得基础模型能够应用于更大规模的场景。
技术框架:S-MUSt3R的整体流程包括三个主要阶段:1) 序列分割:将输入的RGB视频流分割成多个短序列片段。2) 分割对齐:利用MUSt3R模型对每个片段进行3D重建,然后通过帧间匹配和位姿估计,将这些片段对齐到同一个坐标系下。3) 回环优化:检测并优化全局的回环约束,以消除累积误差,提高重建精度。
关键创新:该方法最重要的创新在于将基础模型与传统SLAM技术相结合,利用基础模型的强大3D感知能力,同时借助传统SLAM技术的可扩展性。通过序列分割和对齐,有效解决了基础模型在大规模场景下的内存瓶颈。
关键设计:序列分割的长度需要根据场景和硬件条件进行调整,以保证每个片段都能在内存中完成重建。分割对齐阶段采用基于特征点的帧间匹配方法,并使用RANSAC算法剔除外点。回环优化采用g2o等图优化库,优化相机位姿和路标点坐标。
🖼️ 关键图片

📊 实验亮点
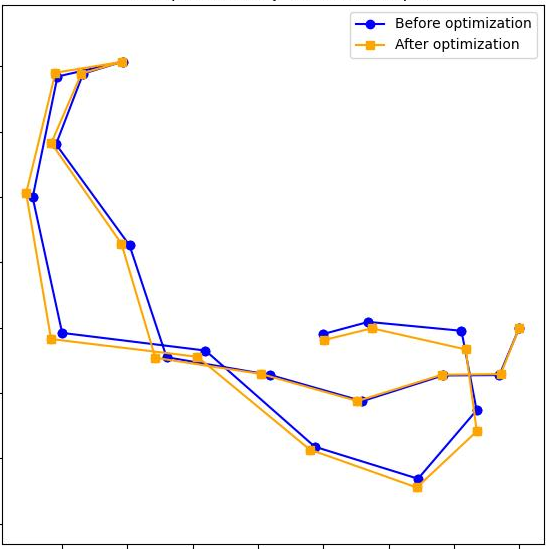
S-MUSt3R在TUM、7-Scenes和机器人导航数据集上进行了评估,结果表明其在轨迹和重建精度上与传统方法相当,甚至在某些场景下优于传统方法。尤其是在长序列的机器人导航数据集中,S-MUSt3R能够成功运行并生成一致的3D重建结果,验证了其在大规模场景下的可扩展性。
🎯 应用场景
S-MUSt3R在机器人导航、增强现实、虚拟现实、自动驾驶等领域具有广泛的应用前景。它可以帮助机器人在未知环境中进行自主导航和地图构建,为AR/VR应用提供更逼真的3D场景,并为自动驾驶系统提供更准确的环境感知能力。该研究的实际价值在于降低了3D重建的计算成本和硬件要求,使得更多设备可以实现高质量的3D重建。
📄 摘要(原文)
The recent paradigm shift in 3D vision led to the rise of foundation models with remarkable capabilities in 3D perception from uncalibrated images. However, extending these models to large-scale RGB stream 3D reconstruction remains challenging due to memory limitations. This work proposes S-MUSt3R, a simple and efficient pipeline that extends the limits of foundation models for monocular 3D reconstruction. Our approach addresses the scalability bottleneck of foundation models through a simple strategy of sequence segmentation followed by segment alignment and lightweight loop closure optimization. Without model retraining, we benefit from remarkable 3D reconstruction capacities of MUSt3R model and achieve trajectory and reconstruction performance comparable to traditional methods with more complex architecture. We evaluate S-MUSt3R on TUM, 7-Scenes and proprietary robot navigation datasets and show that S-MUSt3R runs successfully on long RGB sequences and produces accurate and consistent 3D reconstruction. Our results highlight the potential of leveraging the MUSt3R model for scalable monocular 3D scene in real-world settings, with an important advantage of making predictions directly in the metric space.