Vision-aligned Latent Reasoning for Multi-modal Large Language Model
作者: Byungwoo Jeon, Yoonwoo Jeong, Hyunseok Lee, Minsu Cho, Jinwoo Shin
分类: cs.CV
发布日期: 2026-02-04
备注: 18 pages; 5 figures
💡 一句话要点
提出Vision-aligned Latent Reasoning (VaLR)以提升多模态大语言模型在复杂推理任务中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉推理 长文本理解 潜在空间 视觉对齐
📋 核心要点
- 多模态大语言模型在复杂推理任务中面临视觉信息在长文本生成中逐渐稀释的问题,限制了其性能。
- VaLR框架通过动态生成与视觉对齐的潜在tokens,引导模型在潜在空间中进行推理,从而保持视觉信息。
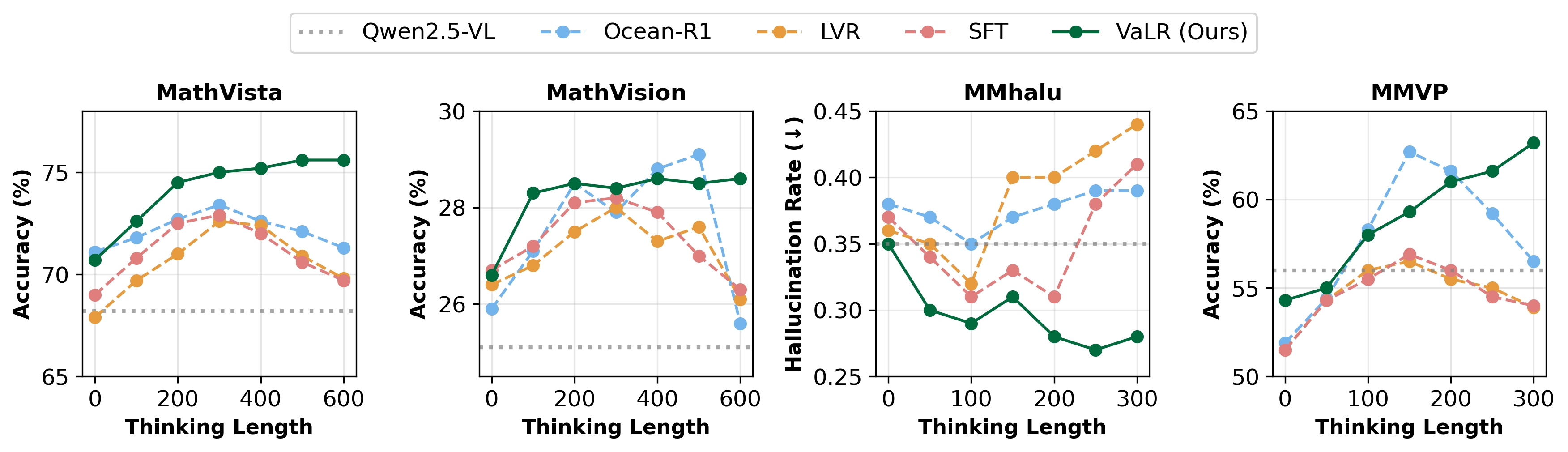
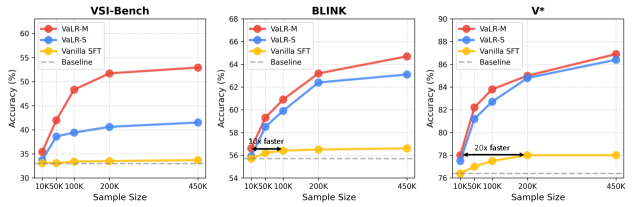
- 实验表明,VaLR在长文本理解和精确视觉感知任务中显著优于现有方法,并在VSI-Bench上提升了19.9%。
📝 摘要(中文)
本文提出了一种名为Vision-aligned Latent Reasoning (VaLR) 的推理框架,旨在解决多模态大语言模型 (MLLM) 在需要多步骤推理的任务中表现不佳的问题。该问题主要是由于长文本生成过程中视觉信息的逐步稀释,阻碍了模型充分利用测试时扩展能力。VaLR 通过在每个思维链推理步骤之前动态生成与视觉对齐的潜在tokens,引导模型基于潜在空间中的感知线索进行推理,从而缓解视觉信息稀释的问题。VaLR 通过将 MLLM 的中间嵌入与视觉编码器的嵌入对齐,从而在推理过程中保持视觉知识。实验结果表明,VaLR 在需要长文本理解或精确视觉感知的各种基准测试中始终优于现有方法,并表现出先前 MLLM 未观察到的测试时扩展行为。特别是在 VSI-Bench 上,VaLR 的性能从 33.0% 显著提高到 52.9%,比 Qwen2.5-VL 提高了 19.9 个百分点。
🔬 方法详解
问题定义:多模态大语言模型在处理需要多步骤推理的任务时,由于视觉信息在长文本生成过程中逐渐稀释,导致模型无法有效利用视觉信息进行推理,从而影响性能。现有方法难以在长推理过程中保持视觉信息的完整性,限制了模型在复杂视觉推理任务中的应用。
核心思路:VaLR的核心思路是在每个推理步骤之前,动态生成与视觉对齐的潜在tokens。这些tokens包含了从视觉编码器提取的视觉信息,并与MLLM的中间嵌入对齐,从而引导模型在潜在空间中进行推理。通过这种方式,VaLR能够有效地保持视觉信息,并避免其在长推理过程中被稀释。
技术框架:VaLR框架主要包含以下几个模块:1) 视觉编码器:用于提取输入图像的视觉特征。2) MLLM:作为主要的推理模型。3) 潜在Token生成器:在每个推理步骤之前,基于视觉编码器的输出和MLLM的中间嵌入,生成与视觉对齐的潜在tokens。4) 对齐模块:通过损失函数,将MLLM的中间嵌入与视觉编码器的嵌入对齐,从而保证潜在tokens包含丰富的视觉信息。整个流程是,首先通过视觉编码器提取视觉特征,然后在每个推理步骤之前,利用潜在Token生成器生成与视觉对齐的潜在tokens,并将这些tokens输入到MLLM中进行推理。
关键创新:VaLR的关键创新在于动态生成与视觉对齐的潜在tokens,并在推理过程中保持视觉信息的完整性。与现有方法不同,VaLR不是直接将视觉信息输入到MLLM中,而是在潜在空间中进行视觉信息的融合和推理。这种方法能够有效地避免视觉信息在长推理过程中被稀释,从而提高模型的性能。
关键设计:VaLR的关键设计包括:1) 潜在Token生成器的结构:可以使用Transformer或其他神经网络结构。2) 对齐损失函数:可以使用对比损失或交叉熵损失等。3) MLLM的中间嵌入的选择:可以选择不同层的嵌入进行对齐。4) 潜在tokens的数量:需要根据具体的任务进行调整。论文中可能详细描述了这些参数的具体设置和选择依据。
🖼️ 关键图片

📊 实验亮点
VaLR在VSI-Bench基准测试中取得了显著的性能提升,从33.0%提高到52.9%,相比Qwen2.5-VL提升了19.9个百分点。此外,VaLR在其他需要长文本理解或精确视觉感知的基准测试中也优于现有方法,并表现出测试时扩展行为,表明其具有良好的泛化能力和可扩展性。
🎯 应用场景
VaLR框架具有广泛的应用前景,可以应用于需要复杂视觉推理的任务中,例如视觉问答、图像描述、机器人导航等。该研究的实际价值在于提升多模态大语言模型在复杂任务中的性能,使其能够更好地理解和利用视觉信息。未来,VaLR可以进一步扩展到其他模态,例如语音和文本,从而构建更加强大的多模态智能系统。
📄 摘要(原文)
Despite recent advancements in Multi-modal Large Language Models (MLLMs) on diverse understanding tasks, these models struggle to solve problems which require extensive multi-step reasoning. This is primarily due to the progressive dilution of visual information during long-context generation, which hinders their ability to fully exploit test-time scaling. To address this issue, we introduce Vision-aligned Latent Reasoning (VaLR), a simple, yet effective reasoning framework that dynamically generates vision-aligned latent tokens before each Chain of Thought reasoning step, guiding the model to reason based on perceptual cues in the latent space. Specifically, VaLR is trained to preserve visual knowledge during reasoning by aligning intermediate embeddings of MLLM with those from vision encoders. Empirical results demonstrate that VaLR consistently outperforms existing approaches across a wide range of benchmarks requiring long-context understanding or precise visual perception, while exhibiting test-time scaling behavior not observed in prior MLLMs. In particular, VaLR improves the performance significantly from 33.0% to 52.9% on VSI-Bench, achieving a 19.9%p gain over Qwen2.5-VL.