Med-MMFL: A Multimodal Federated Learning Benchmark in Healthcare
作者: Aavash Chhetri, Bibek Niroula, Pratik Shrestha, Yash Raj Shrestha, Lesley A Anderson, Prashnna K Gyawali, Loris Bazzani, Binod Bhattarai
分类: cs.CV, cs.AI
发布日期: 2026-02-04
🔗 代码/项目: GITHUB
💡 一句话要点
Med-MMFL:医疗多模态联邦学习基准,促进算法公平评估与可复现性研究。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 多模态学习 医疗影像 自然语言处理 基准测试 数据隐私 模型训练
📋 核心要点
- 现有医疗联邦学习基准主要集中于单模态或双模态数据,缺乏对多模态数据的全面支持,限制了算法的有效评估。
- Med-MMFL基准旨在提供一个全面的多模态医疗联邦学习评估平台,包含多种模态、任务和联邦场景,促进算法的公平比较。
- 该基准测试了六种先进的联邦学习算法,涵盖分割、分类、模态对齐和VQA等任务,并在不同联邦场景下进行了评估。
📝 摘要(中文)
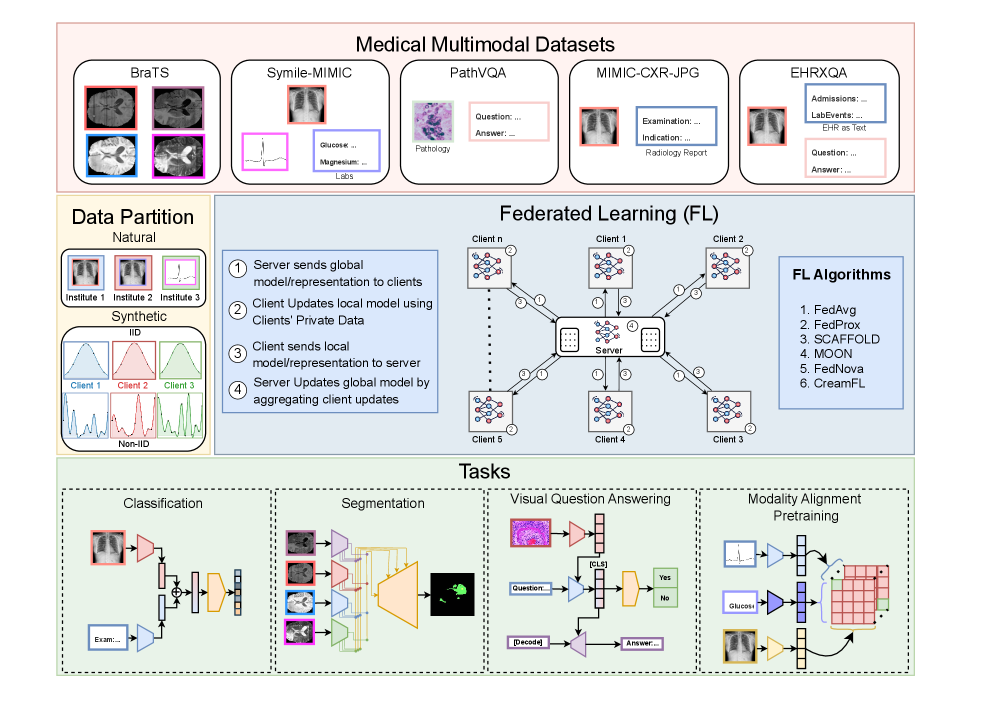
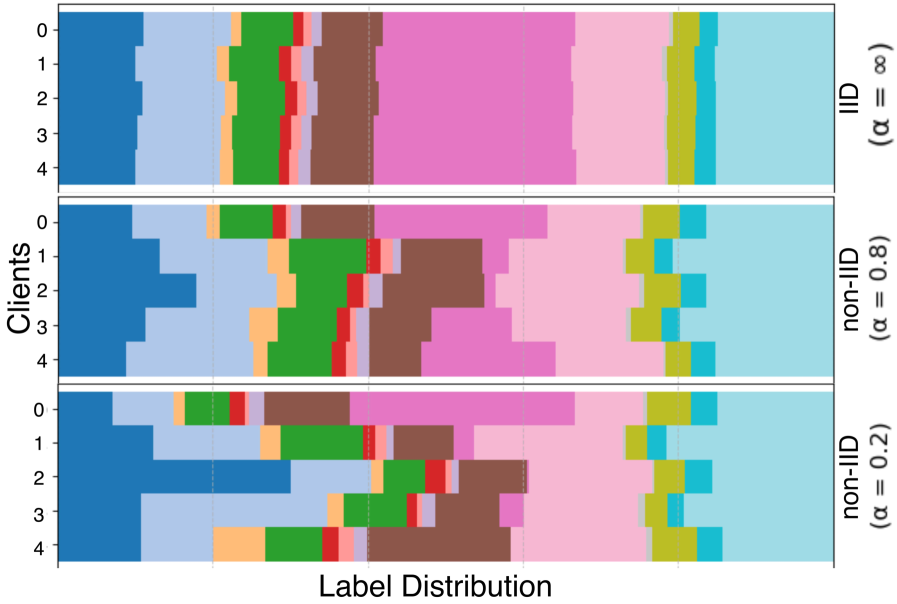
联邦学习(FL)能够在保护数据隐私的前提下,实现跨去中心化医疗机构的协同模型训练。然而,现有的医疗FL基准仍然稀缺,主要集中在单模态或双模态,且医疗任务范围有限。这种差距凸显了对标准化评估的需求,以促进对医疗多模态联邦学习(MMFL)的系统性理解。为此,我们推出了Med-MMFL,这是首个全面的医疗领域MMFL基准,涵盖了多样化的模态、任务和联邦场景。我们的基准评估了六种代表性的最先进的FL算法,涵盖了不同的聚合策略、损失函数公式和正则化技术。它跨越了具有2到4种模态的数据集,总共包含10种独特的医疗模态,包括文本、病理图像、心电图、X射线、放射学报告和多个MRI序列。实验在自然联邦、合成IID和合成非IID设置下进行,以模拟真实世界的异构性。我们评估了分割、分类、模态对齐(检索)和VQA任务。为了支持在真实的医疗环境下,未来多模态联邦学习(MMFL)方法的可重复性和公平比较,我们发布了完整的基准实现,包括数据处理和分区管道,网址为https://github.com/bhattarailab/Med-MMFL-Benchmark。
🔬 方法详解
问题定义:现有的医疗联邦学习基准测试集主要集中于单模态或双模态数据,无法充分评估多模态联邦学习算法在实际医疗场景中的性能。此外,缺乏统一的数据处理和评估流程,导致不同算法之间的比较困难。因此,需要一个全面的、标准化的多模态医疗联邦学习基准,以促进该领域的研究进展。
核心思路:Med-MMFL的核心思路是构建一个包含多种医疗模态、任务和联邦场景的综合性基准测试集。通过提供统一的数据处理和评估流程,以及多种代表性的联邦学习算法的实现,该基准旨在促进多模态联邦学习算法的公平比较和可重复性研究。
技术框架:Med-MMFL基准包含以下主要模块:1) 数据集:包含多种医疗模态的数据集,如文本、病理图像、心电图、X射线、放射学报告和MRI序列。2) 任务:支持分割、分类、模态对齐(检索)和VQA等多种医疗任务。3) 联邦场景:提供自然联邦、合成IID和合成非IID等多种联邦场景,以模拟真实世界的异构性。4) 算法:包含六种代表性的最先进的联邦学习算法的实现。5) 评估指标:提供统一的评估指标,用于评估不同算法的性能。
关键创新:Med-MMFL的关键创新在于它是首个全面的医疗领域多模态联邦学习基准。它涵盖了多种医疗模态、任务和联邦场景,并提供了统一的数据处理和评估流程,以及多种代表性的联邦学习算法的实现。这使得研究人员能够更方便地评估和比较不同的多模态联邦学习算法,从而促进该领域的研究进展。
关键设计:Med-MMFL的关键设计包括:1) 数据集的选择:选择具有代表性的医疗数据集,涵盖多种模态和任务。2) 联邦场景的模拟:模拟真实世界的异构性,提供多种联邦场景。3) 算法的选择:选择代表性的最先进的联邦学习算法,涵盖不同的聚合策略、损失函数公式和正则化技术。4) 评估指标的设计:设计统一的评估指标,用于评估不同算法的性能。
🖼️ 关键图片

📊 实验亮点
Med-MMFL基准测试了六种先进的联邦学习算法,涵盖了不同的聚合策略、损失函数和正则化技术。实验结果表明,不同算法在不同的模态、任务和联邦场景下表现各异,突出了多模态联邦学习的复杂性和挑战性。该基准为未来算法的改进提供了重要的参考。
🎯 应用场景
Med-MMFL基准可用于评估和比较不同的多模态联邦学习算法在医疗领域的性能,促进更有效的算法设计。该基准能够推动联邦学习在医疗影像分析、疾病诊断、个性化治疗等方面的应用,最终提升医疗服务的质量和效率,同时保障患者隐私。
📄 摘要(原文)
Federated learning (FL) enables collaborative model training across decentralized medical institutions while preserving data privacy. However, medical FL benchmarks remain scarce, with existing efforts focusing mainly on unimodal or bimodal modalities and a limited range of medical tasks. This gap underscores the need for standardized evaluation to advance systematic understanding in medical MultiModal FL (MMFL). To this end, we introduce Med-MMFL, the first comprehensive MMFL benchmark for the medical domain, encompassing diverse modalities, tasks, and federation scenarios. Our benchmark evaluates six representative state-of-the-art FL algorithms, covering different aggregation strategies, loss formulations, and regularization techniques. It spans datasets with 2 to 4 modalities, comprising a total of 10 unique medical modalities, including text, pathology images, ECG, X-ray, radiology reports, and multiple MRI sequences. Experiments are conducted across naturally federated, synthetic IID, and synthetic non-IID settings to simulate real-world heterogeneity. We assess segmentation, classification, modality alignment (retrieval), and VQA tasks. To support reproducibility and fair comparison of future multimodal federated learning (MMFL) methods under realistic medical settings, we release the complete benchmark implementation, including data processing and partitioning pipelines, at https://github.com/bhattarailab/Med-MMFL-Benchmark .