When and Where to Attack? Stage-wise Attention-Guided Adversarial Attack on Large Vision Language Models
作者: Jaehyun Kwak, Nam Cao, Boryeong Cho, Segyu Lee, Sumyeong Ahn, Se-Young Yun
分类: cs.CV
发布日期: 2026-02-04
备注: Pre-print
🔗 代码/项目: GITHUB
💡 一句话要点
提出SAGA,一种阶段式注意力引导的视觉语言模型对抗攻击方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 对抗攻击 注意力机制 多模态安全 深度学习
📋 核心要点
- 现有LVLM对抗攻击方法,如随机裁剪,效率低,未能充分利用有限的扰动预算。
- SAGA通过注意力机制引导,逐步将扰动集中在高注意力区域,提高攻击效率。
- 实验表明,SAGA在多个LVLM上实现了最先进的攻击成功率,同时保持了对抗样本的隐蔽性。
📝 摘要(中文)
针对大型视觉语言模型(LVLMs)的对抗攻击对于揭示现代多模态系统的安全漏洞至关重要。最近基于输入转换(如随机裁剪)的攻击表明,空间局部扰动可能比全局图像操作更有效。然而,随机裁剪整个图像本质上是随机的,并且未能有效利用有限的像素扰动预算。我们有两个关键观察结果:(i)区域注意力得分与对抗损失敏感性呈正相关,以及(ii)攻击高注意力区域会引起注意力向后续显著区域的结构化重新分配。基于这些发现,我们提出了一种阶段式注意力引导攻击(SAGA),该框架逐步将扰动集中在高注意力区域。SAGA能够更有效地利用有限的扰动预算,产生高度难以察觉的对抗样本,同时在十个LVLM上始终如一地实现最先进的攻击成功率。
🔬 方法详解
问题定义:论文旨在解决大型视觉语言模型(LVLMs)的对抗攻击问题。现有方法,特别是基于随机裁剪的攻击,存在效率低下的问题,因为它们没有充分利用有限的像素扰动预算,导致攻击效果不稳定且容易被察觉。这些方法未能有效定位图像中对模型决策影响最大的区域进行攻击。
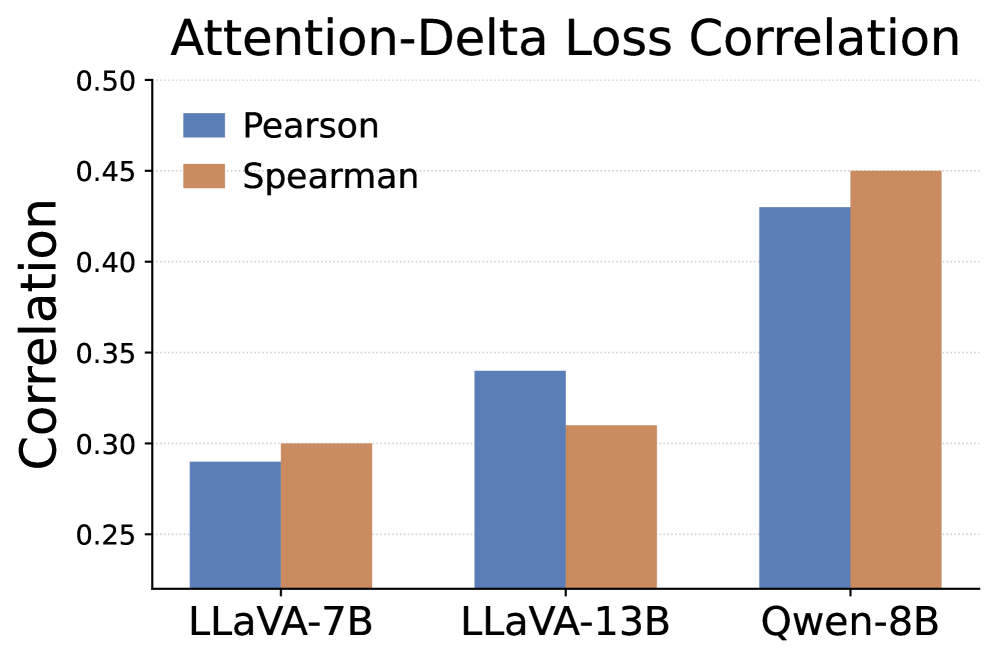
核心思路:论文的核心思路是利用视觉语言模型中的注意力机制来引导对抗扰动的生成。作者观察到,图像区域的注意力得分与对抗损失的敏感性之间存在正相关关系,并且攻击高注意力区域会导致注意力向其他显著区域转移。因此,通过逐步将扰动集中在高注意力区域,可以更有效地利用扰动预算,从而提高攻击的成功率和隐蔽性。
技术框架:SAGA(Stage-wise Attention-Guided Attack)的整体框架是一个迭代的攻击过程,包含以下主要阶段: 1. 注意力图生成:使用LVLM提取输入图像的注意力图,识别出图像中具有高注意力的区域。 2. 区域选择:根据注意力得分选择需要攻击的区域。在初始阶段,选择注意力最高的区域。在后续阶段,根据注意力重新分布的情况选择新的区域。 3. 扰动生成:在选定的区域上生成对抗扰动。可以使用各种对抗攻击算法,如FGSM或PGD。 4. 扰动应用:将生成的扰动添加到原始图像中,生成对抗样本。 5. 迭代:重复上述步骤,直到达到攻击目标或达到最大迭代次数。
关键创新:SAGA的关键创新在于其注意力引导的阶段式攻击策略。与传统的全局扰动或随机裁剪方法不同,SAGA能够根据模型的注意力分布动态地调整攻击区域,从而更有效地利用扰动预算。此外,SAGA的阶段式攻击策略能够诱导模型将注意力转移到其他区域,从而进一步提高攻击的成功率。
关键设计:SAGA的关键设计包括: 1. 注意力图的获取:使用LVLM的视觉编码器提取注意力图。具体实现取决于所使用的LVLM的架构。 2. 区域选择策略:根据注意力得分选择攻击区域。可以使用不同的选择策略,如选择注意力最高的K个区域,或选择注意力得分高于阈值的区域。 3. 扰动生成算法:可以使用各种对抗攻击算法生成扰动,如FGSM、PGD等。论文中使用了PGD算法。 4. 扰动预算的控制:限制每个像素的扰动幅度,以保证对抗样本的隐蔽性。通常使用L-infinity范数来约束扰动。
🖼️ 关键图片


📊 实验亮点
SAGA在十个不同的LVLM上进行了广泛的实验,结果表明SAGA始终优于现有的对抗攻击方法,实现了最先进的攻击成功率。与基线方法相比,SAGA在保持对抗样本隐蔽性的同时,显著提高了攻击的成功率,证明了其有效性和优越性。代码已开源。
🎯 应用场景
该研究成果可应用于评估和提高大型视觉语言模型的安全性。通过对抗攻击,可以发现LVLM的潜在漏洞,并为开发更鲁棒的模型提供指导。此外,该技术还可以用于防御对抗攻击,例如通过检测和过滤对抗样本来提高LVLM的可靠性。该研究对多模态安全领域具有重要意义。
📄 摘要(原文)
Adversarial attacks against Large Vision-Language Models (LVLMs) are crucial for exposing safety vulnerabilities in modern multimodal systems. Recent attacks based on input transformations, such as random cropping, suggest that spatially localized perturbations can be more effective than global image manipulation. However, randomly cropping the entire image is inherently stochastic and fails to use the limited per-pixel perturbation budget efficiently. We make two key observations: (i) regional attention scores are positively correlated with adversarial loss sensitivity, and (ii) attacking high-attention regions induces a structured redistribution of attention toward subsequent salient regions. Based on these findings, we propose Stage-wise Attention-Guided Attack (SAGA), an attention-guided framework that progressively concentrates perturbations on high-attention regions. SAGA enables more efficient use of constrained perturbation budgets, producing highly imperceptible adversarial examples while consistently achieving state-of-the-art attack success rates across ten LVLMs. The source code is available at https://github.com/jackwaky/SAGA.