JOintGS: Joint Optimization of Cameras, Bodies and 3D Gaussians for In-the-Wild Monocular Reconstruction
作者: Zihan Lou, Jinlong Fan, Sihan Ma, Yuxiang Yang, Jing Zhang
分类: cs.CV
发布日期: 2026-02-04
备注: 15 pages, 15 figures, Project page at https://github.com/MiliLab/JOintGS
🔗 代码/项目: GITHUB
💡 一句话要点
JOintGS:联合优化相机、人体和3D高斯,实现野外单目重建
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 单目重建 3D高斯 人体姿态估计 相机标定 联合优化 野外场景 可动画化身
📋 核心要点
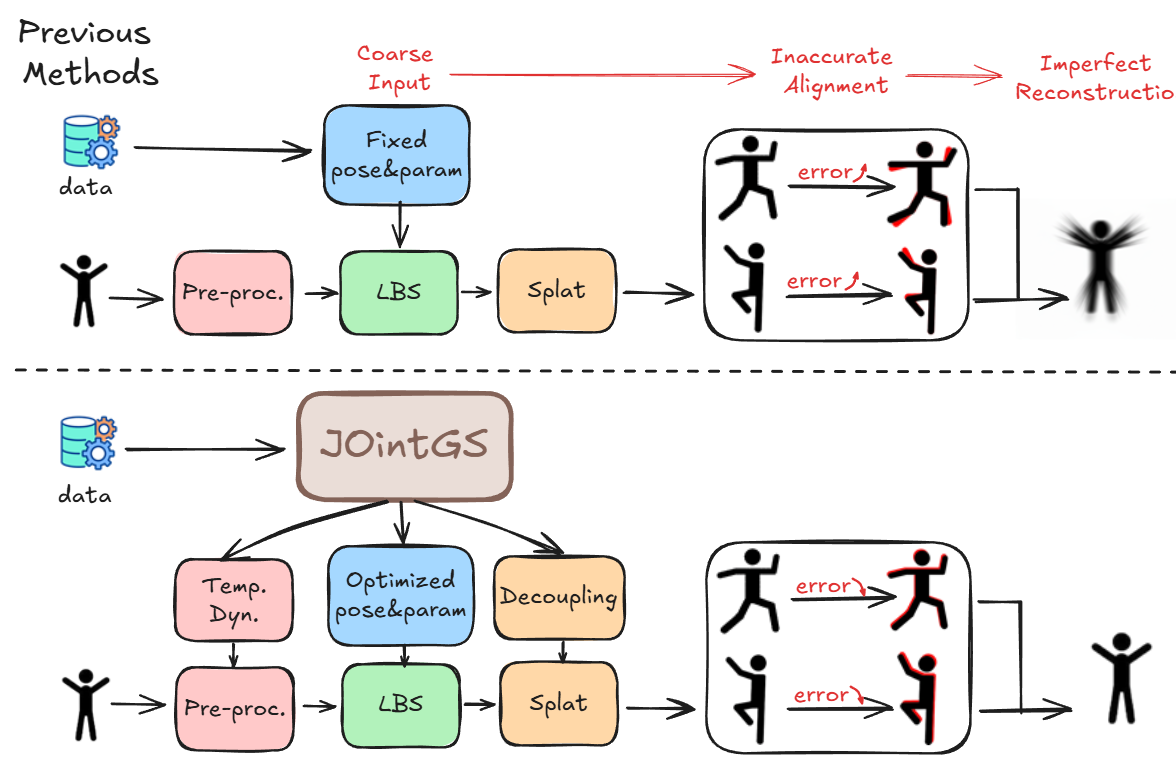
- 现有方法在野外场景中,由于相机参数和人体姿态估计不准确,难以实现高保真可动画3D人体重建。
- JOintGS通过联合优化相机外参、人体姿态和3D高斯表示,利用前景-背景解耦实现相互增强,提升重建质量。
- 实验表明,JOintGS在NeuMan数据集上比现有方法提升了2.1dB PSNR,并对噪声初始化具有更强的鲁棒性。
📝 摘要(中文)
本文提出JOintGS,一个统一的框架,用于从粗略初始化开始,通过协同细化机制联合优化相机外参、人体姿态和3D高斯表示,从而实现野外单目RGB视频中高保真可动画3D人体化身重建。核心思想是显式地解耦前景和背景,从而实现相互增强:静态背景高斯通过多视角一致性锚定相机估计;精细化的相机通过精确的时间对应关系改善人体对齐;优化的人体姿态通过消除静态约束中的动态伪影来增强场景重建。此外,还引入了时间动态模块来捕捉细粒度的姿态相关变形,以及残差颜色场来建模光照变化。在NeuMan和EMDB数据集上的大量实验表明,JOintGS实现了卓越的重建质量,在NeuMan数据集上比最先进的方法提高了2.1分贝的PSNR,同时保持了实时渲染。值得注意的是,与基线相比,我们的方法对噪声初始化的鲁棒性显著增强。
🔬 方法详解
问题定义:现有方法在野外单目重建中,依赖于COLMAP、HMR2.0等方法提供的相机参数和人体姿态初始化,但这些方法在不受约束的场景下精度较低,导致重建质量下降。尤其是在使用3D高斯表示时,对相机标定和姿态标注的精度要求极高,限制了其在实际场景中的应用。因此,如何从粗略的初始化中重建高质量的可动画3D人体化身是一个关键问题。
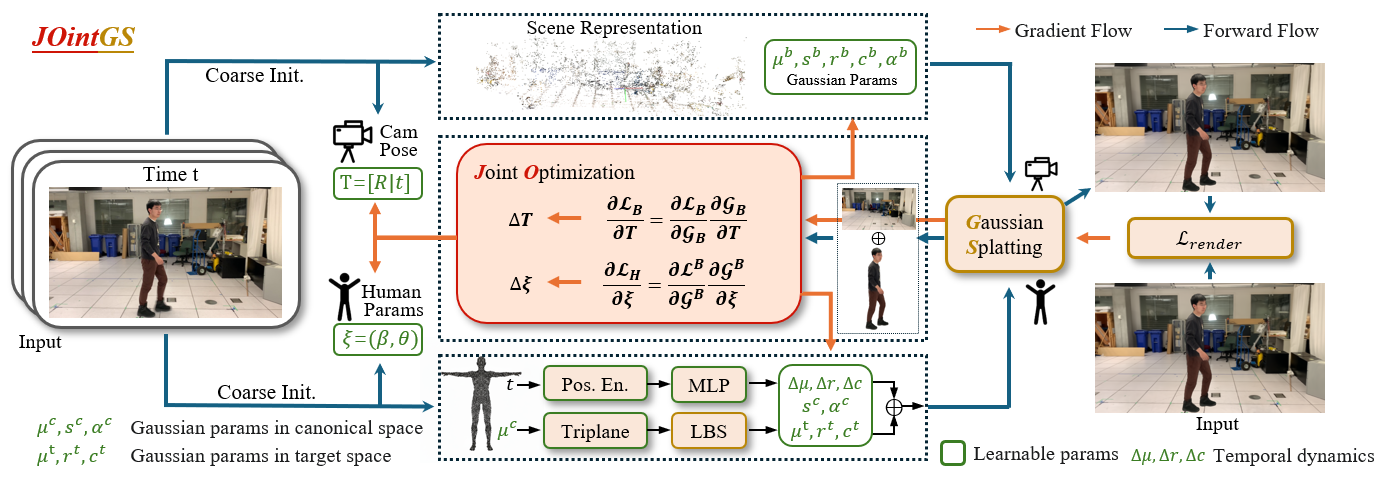
核心思路:JOintGS的核心思路是通过联合优化相机外参、人体姿态和3D高斯表示,利用前景-背景解耦实现相互增强。具体来说,静态背景高斯通过多视角一致性约束来优化相机参数,而精细化的相机参数又可以反过来提升人体姿态的对齐精度,优化后的人体姿态则可以消除静态场景约束中的动态伪影,从而进一步提升场景重建质量。这种协同细化的机制是JOintGS能够从粗略初始化中获得高质量重建的关键。
技术框架:JOintGS的整体框架包含以下几个主要模块:1) 初始化模块:使用现有的方法(如COLMAP、HMR2.0)对相机参数和人体姿态进行粗略初始化。2) 联合优化模块:这是JOintGS的核心模块,它同时优化相机外参、人体姿态和3D高斯表示。该模块利用显式的前景-背景解耦,通过多视角一致性约束和时间对应关系来实现相互增强。3) 时间动态模块:该模块用于捕捉细粒度的姿态相关变形,从而提升重建的真实感。4) 残差颜色场模块:该模块用于建模光照变化,从而提升渲染的真实感。
关键创新:JOintGS最重要的技术创新点在于其联合优化框架和显式的前景-背景解耦。传统的3D高斯方法通常依赖于精确的相机标定和姿态标注,而JOintGS通过联合优化,使得相机参数、人体姿态和3D高斯表示能够相互促进,从而降低了对初始化的精度要求。此外,显式的前景-背景解耦使得静态背景能够用于优化相机参数,而优化后的相机参数又可以用于提升人体姿态的对齐精度,这种相互增强的机制是JOintGS能够取得优异性能的关键。
关键设计:JOintGS的关键设计包括:1) 使用3D高斯表示场景,以实现高质量的渲染和实时性能。2) 设计了多视角一致性损失函数,用于优化相机参数。3) 设计了时间对应关系损失函数,用于优化人体姿态。4) 引入了时间动态模块,用于捕捉细粒度的姿态相关变形。5) 引入了残差颜色场模块,用于建模光照变化。具体的参数设置和网络结构细节可以在论文的实验部分找到。
🖼️ 关键图片

📊 实验亮点
JOintGS在NeuMan数据集上取得了显著的性能提升,PSNR指标比最先进的方法提高了2.1dB。此外,JOintGS对噪声初始化的鲁棒性也显著增强,即使在相机参数和人体姿态初始化不准确的情况下,仍然能够重建出高质量的3D人体化身。实验结果表明,JOintGS在重建质量和鲁棒性方面都优于现有方法。
🎯 应用场景
JOintGS在虚拟现实、增强现实、游戏开发、电影制作等领域具有广泛的应用前景。它可以用于创建逼真的虚拟化身,实现沉浸式的交互体验。此外,该技术还可以用于人体动作捕捉、运动分析、远程协作等领域,具有重要的实际价值和未来影响。
📄 摘要(原文)
Reconstructing high-fidelity animatable 3D human avatars from monocular RGB videos remains challenging, particularly in unconstrained in-the-wild scenarios where camera parameters and human poses from off-the-shelf methods (e.g., COLMAP, HMR2.0) are often inaccurate. Splatting (3DGS) advances demonstrate impressive rendering quality and real-time performance, they critically depend on precise camera calibration and pose annotations, limiting their applicability in real-world settings. We present JOintGS, a unified framework that jointly optimizes camera extrinsics, human poses, and 3D Gaussian representations from coarse initialization through a synergistic refinement mechanism. Our key insight is that explicit foreground-background disentanglement enables mutual reinforcement: static background Gaussians anchor camera estimation via multi-view consistency; refined cameras improve human body alignment through accurate temporal correspondence; optimized human poses enhance scene reconstruction by removing dynamic artifacts from static constraints. We further introduce a temporal dynamics module to capture fine-grained pose-dependent deformations and a residual color field to model illumination variations. Extensive experiments on NeuMan and EMDB datasets demonstrate that JOintGS achieves superior reconstruction quality, with 2.1~dB PSNR improvement over state-of-the-art methods on NeuMan dataset, while maintaining real-time rendering. Notably, our method shows significantly enhanced robustness to noisy initialization compared to the baseline.Our source code is available at https://github.com/MiliLab/JOintGS.