KVSmooth: Mitigating Hallucination in Multi-modal Large Language Models through Key-Value Smoothing
作者: Siyu Jiang, Feiyang Chen, Xiaojin Zhang, Kun He
分类: cs.CV
发布日期: 2026-02-04
💡 一句话要点
提出KVSmooth以解决多模态大语言模型中的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 幻觉现象 自适应平滑 注意力机制 指数移动平均 模型推理 性能提升
📋 核心要点
- 现有多模态大语言模型在生成过程中常常出现幻觉现象,导致输出与视觉事实不一致,影响模型的可靠性。
- KVSmooth通过对隐藏状态进行注意力熵引导的自适应平滑,采用指数移动平均(EMA)来减轻幻觉现象,且无需额外训练。
- 实验结果显示,KVSmooth在减少幻觉(CHAIR_S从41.8降至18.2)的同时,F1得分从77.5提升至79.2,展现出更高的精确度和召回率。
📝 摘要(中文)
尽管多模态大语言模型(MLLMs)在各种任务上取得了显著进展,但幻觉现象——即生成视觉上不一致的对象、属性或关系——仍然是其可靠部署的主要障碍。与纯语言模型不同,MLLMs必须将生成过程与视觉输入相结合。然而,现有模型在解码过程中常常遭遇语义漂移,导致输出与视觉事实偏离。为了解决这一问题,本文提出KVSmooth,这是一种无训练且可插拔的方法,通过对隐藏状态进行注意力熵引导的自适应平滑来减轻幻觉现象。KVSmooth在KV缓存中对键和值应用指数移动平均(EMA),并通过动态量化每个标记的注意力分布熵来自适应调整平滑强度。实验表明,KVSmooth显著降低了幻觉现象,同时提高了整体性能。
🔬 方法详解
问题定义:本文旨在解决多模态大语言模型(MLLMs)在生成过程中出现的幻觉现象,现有方法在解码时容易导致输出与视觉事实的偏离,影响模型的可靠性和实用性。
核心思路:KVSmooth的核心思路是通过对隐藏状态进行注意力熵引导的自适应平滑,利用指数移动平均(EMA)来平滑KV缓存中的键和值,从而减轻幻觉现象。
技术框架:KVSmooth的整体架构包括对KV缓存的平滑处理和动态调整平滑强度的机制。具体而言,模型在推理阶段对每个标记的注意力分布进行熵计算,以此来调整平滑的强度。
关键创新:KVSmooth的主要创新在于其训练自由和高效的推理过程,避免了传统方法中需要的重训练或对比解码,能够在不修改模型的情况下直接应用。
关键设计:KVSmooth通过动态量化每个标记的注意力分布熵来适应性地调整平滑强度,确保在不同情况下都能有效减轻幻觉现象。
🖼️ 关键图片
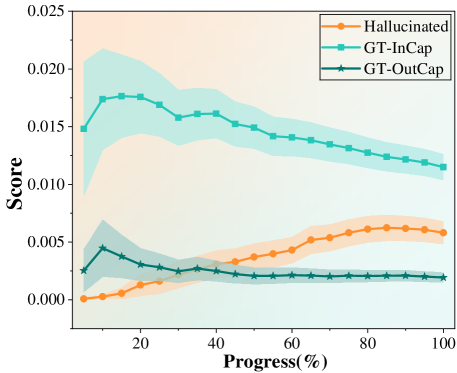


📊 实验亮点
KVSmooth在实验中表现出显著的性能提升,幻觉现象的CHAIR_S指标从41.8降低至18.2,同时F1得分从77.5提升至79.2,展示了该方法在提高精确度和召回率方面的有效性,优于以往方法。
🎯 应用场景
KVSmooth的研究成果具有广泛的应用潜力,尤其在需要高可靠性的多模态生成任务中,如自动驾驶、机器人视觉和智能助手等领域。通过减轻幻觉现象,KVSmooth能够提升多模态大语言模型的实用性和用户体验,推动相关技术的实际应用和发展。
📄 摘要(原文)
Despite the significant progress of Multimodal Large Language Models (MLLMs) across diverse tasks, hallucination -- corresponding to the generation of visually inconsistent objects, attributes, or relations -- remains a major obstacle to their reliable deployment. Unlike pure language models, MLLMs must ground their generation process in visual inputs. However, existing models often suffer from semantic drift during decoding, causing outputs to diverge from visual facts as the sequence length increases. To address this issue, we propose KVSmooth, a training-free and plug-and-play method that mitigates hallucination by performing attention-entropy-guided adaptive smoothing on hidden states. Specifically, KVSmooth applies an exponential moving average (EMA) to both keys and values in the KV-Cache, while dynamically quantifying the sink degree of each token through the entropy of its attention distribution to adaptively adjust the smoothing strength. Unlike computationally expensive retraining or contrastive decoding methods, KVSmooth operates efficiently during inference without additional training or model modification. Extensive experiments demonstrate that KVSmooth significantly reduces hallucination ($\mathit{CHAIR}_{S}$ from $41.8 \rightarrow 18.2$) while improving overall performance ($F_1$ score from $77.5 \rightarrow 79.2$), achieving higher precision and recall simultaneously. In contrast, prior methods often improve one at the expense of the other, validating the effectiveness and generality of our approach.