Decoupled Hierarchical Distillation for Multimodal Emotion Recognition
作者: Yong Li, Yuanzhi Wang, Yi Ding, Shiqing Zhang, Ke Lu, Cuntai Guan
分类: cs.CV
发布日期: 2026-02-04
备注: arXiv admin note: text overlap with arXiv:2303.13802
期刊: IEEE Transactions on Pattern Analysis and Machine Intelligence 2026
DOI: 10.1109/TPAMI.2026.3660754
💡 一句话要点
提出解耦分层蒸馏框架DHMD,提升多模态情感识别性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态情感识别 知识蒸馏 特征解耦 跨模态对齐 图神经网络
📋 核心要点
- 现有MER方法难以有效处理多模态数据中固有的异构性和不同模态贡献的差异。
- DHMD通过解耦模态特征并采用分层知识蒸馏策略,实现跨模态知识的有效迁移和特征对齐。
- 实验表明,DHMD在多个基准数据集上显著优于现有方法,并在可视化分析中验证了其有效性。
📝 摘要(中文)
本文提出了一种新颖的解耦分层多模态蒸馏(DHMD)框架,用于解决多模态情感识别(MER)中模态异构性和模态贡献差异的问题。DHMD利用自回归机制将每个模态的特征解耦为模态无关(同质)和模态独有(异质)成分。该框架采用两阶段知识蒸馏(KD)策略:(1)通过每个解耦特征空间中的图蒸馏单元(GD-Unit)进行粗粒度KD,其中动态图促进模态间的自适应蒸馏;(2)通过跨模态字典匹配机制进行细粒度KD,该机制对齐跨模态的语义粒度,以产生更具区分性的MER表示。这种分层蒸馏方法能够实现灵活的知识转移,并有效改善跨模态特征对齐。实验结果表明,DHMD始终优于最先进的MER方法,在CMU-MOSI/CMU-MOSEI数据集上分别实现了1.3%/2.4% (ACC$_7$)、1.3%/1.9% (ACC$_2$)和1.9%/1.8% (F1)的相对改进。可视化结果表明,DHMD中的图边和字典激活在模态无关/独有特征空间中表现出有意义的分布模式。
🔬 方法详解
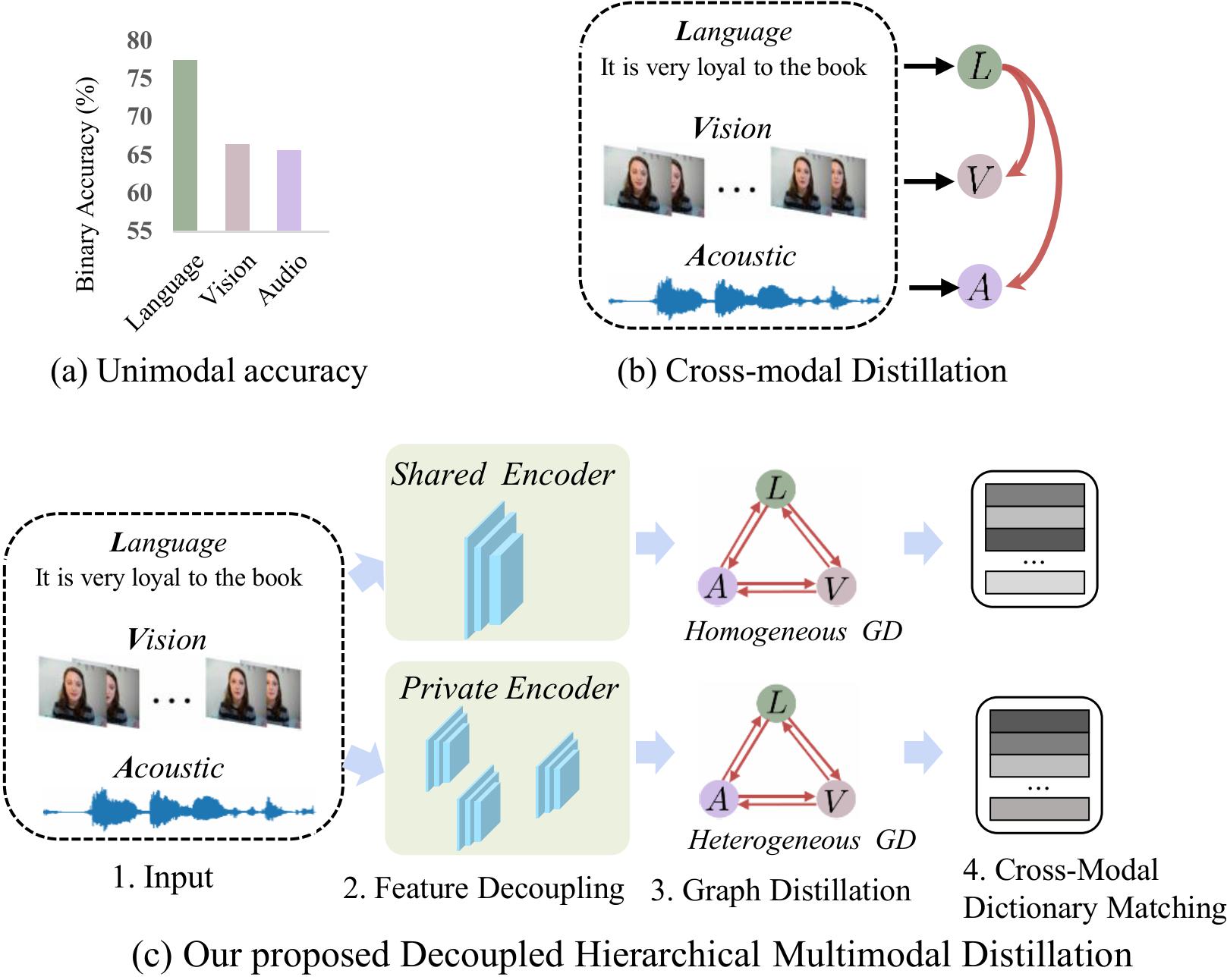
问题定义:多模态情感识别旨在融合来自语言、视觉和听觉等多种模态的信息,以推断人类的情感。现有方法在处理不同模态之间的异构性以及各模态贡献度差异方面存在不足,导致情感识别精度受限。
核心思路:论文的核心思路是将每个模态的特征解耦为模态无关的同质成分和模态独有的异质成分,然后通过分层知识蒸馏的方式,在不同粒度上进行跨模态知识的迁移和对齐。这种解耦操作有助于更好地理解和利用不同模态的信息,而分层蒸馏则可以更灵活地控制知识迁移的过程。
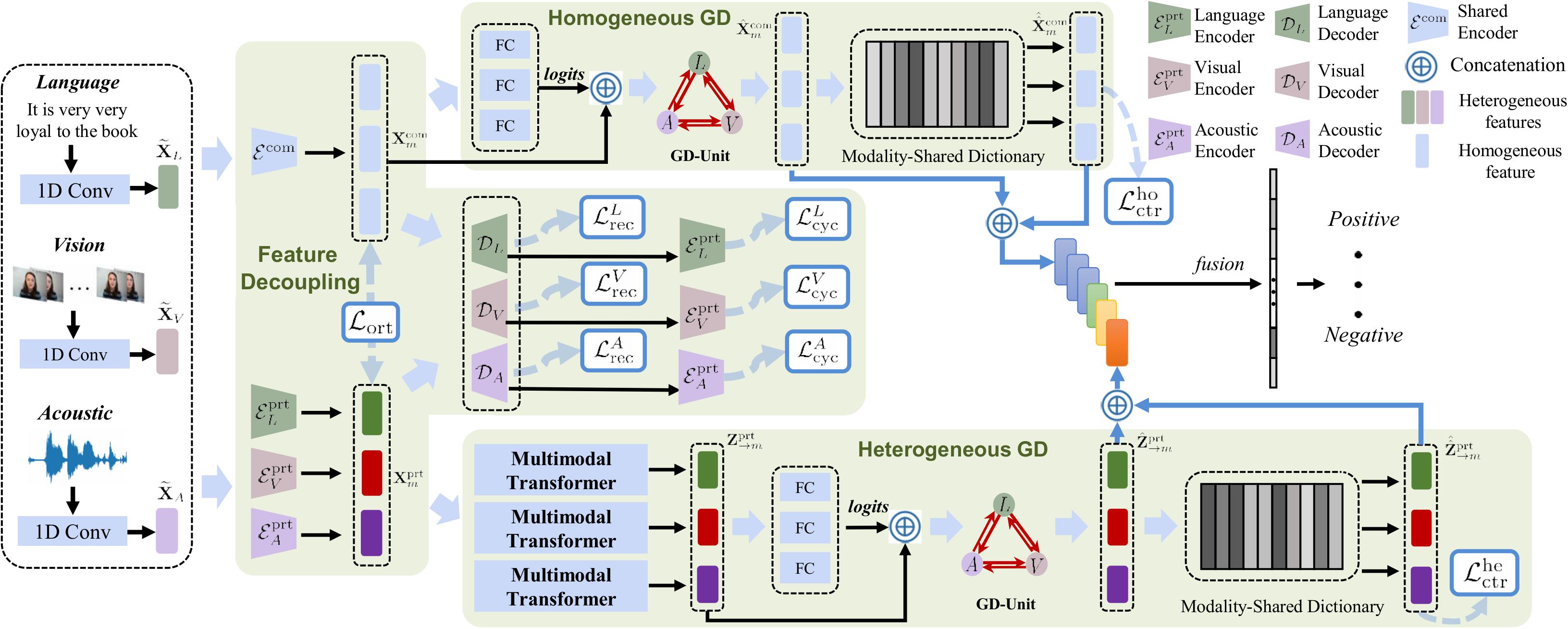
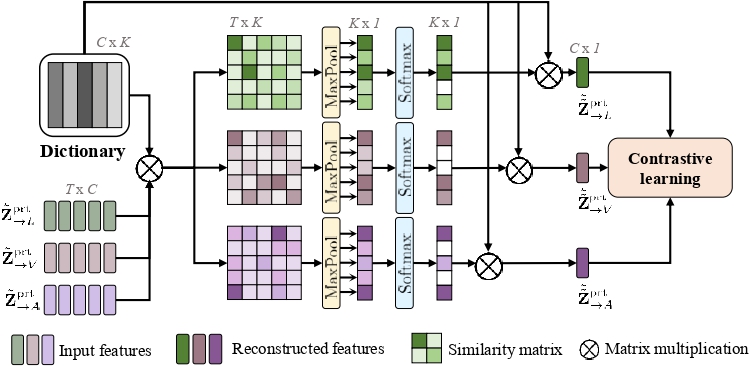
技术框架:DHMD框架主要包含三个部分:特征解耦模块、粗粒度知识蒸馏模块(GD-Unit)和细粒度知识蒸馏模块(跨模态字典匹配)。首先,特征解耦模块利用自回归机制将每个模态的特征分解为同质和异质成分。然后,GD-Unit在解耦后的特征空间中进行粗粒度的知识蒸馏,通过动态图结构自适应地学习模态间的关系。最后,跨模态字典匹配模块通过对齐跨模态的语义粒度,进行细粒度的知识蒸馏,从而生成更具区分性的情感表示。
关键创新:该论文的关键创新在于提出了解耦分层蒸馏的框架。与传统的知识蒸馏方法不同,DHMD首先对模态特征进行解耦,从而更好地处理模态异构性问题。此外,分层蒸馏策略允许在不同粒度上进行知识迁移,提高了模型的灵活性和性能。动态图结构和跨模态字典匹配机制也是重要的创新点,它们分别用于自适应地学习模态关系和对齐跨模态语义。
关键设计:在特征解耦模块中,使用了自回归机制来分离同质和异质成分。GD-Unit中的动态图结构允许模型自适应地学习模态间的关系,图的边权重可以通过注意力机制学习得到。跨模态字典匹配模块通过最小化跨模态特征之间的距离来实现语义对齐。损失函数包括重构损失、蒸馏损失和对齐损失,用于优化模型的各个部分。具体参数设置(如学习率、batch size等)在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DHMD在CMU-MOSI和CMU-MOSEI数据集上均取得了显著的性能提升。在CMU-MOSI数据集上,DHMD的ACC$_7$提升了1.3%,ACC$_2$提升了1.3%,F1提升了1.9%。在CMU-MOSEI数据集上,DHMD的ACC$_7$提升了2.4%,ACC$_2$提升了1.9%,F1提升了1.8%。这些结果表明,DHMD能够有效地处理多模态情感识别任务,并优于现有的最先进方法。
🎯 应用场景
该研究成果可应用于情感分析、人机交互、智能客服、心理健康评估等领域。通过更准确地识别用户的情感状态,可以提升用户体验,改善沟通效果,并为个性化服务提供支持。未来,该方法可以扩展到更多模态和更复杂的情感识别任务中。
📄 摘要(原文)
Human multimodal emotion recognition (MER) seeks to infer human emotions by integrating information from language, visual, and acoustic modalities. Although existing MER approaches have achieved promising results, they still struggle with inherent multimodal heterogeneities and varying contributions from different modalities. To address these challenges, we propose a novel framework, Decoupled Hierarchical Multimodal Distillation (DHMD). DHMD decouples each modality's features into modality-irrelevant (homogeneous) and modality-exclusive (heterogeneous) components using a self-regression mechanism. The framework employs a two-stage knowledge distillation (KD) strategy: (1) coarse-grained KD via a Graph Distillation Unit (GD-Unit) in each decoupled feature space, where a dynamic graph facilitates adaptive distillation among modalities, and (2) fine-grained KD through a cross-modal dictionary matching mechanism, which aligns semantic granularities across modalities to produce more discriminative MER representations. This hierarchical distillation approach enables flexible knowledge transfer and effectively improves cross-modal feature alignment. Experimental results demonstrate that DHMD consistently outperforms state-of-the-art MER methods, achieving 1.3\%/2.4\% (ACC$_7$), 1.3\%/1.9\% (ACC$_2$) and 1.9\%/1.8\% (F1) relative improvement on CMU-MOSI/CMU-MOSEI dataset, respectively. Meanwhile, visualization results reveal that both the graph edges and dictionary activations in DHMD exhibit meaningful distribution patterns across modality-irrelevant/-exclusive feature spaces.