Adaptive 1D Video Diffusion Autoencoder
作者: Yao Teng, Minxuan Lin, Xian Liu, Shuai Wang, Xiao Yang, Xihui Liu
分类: cs.CV
发布日期: 2026-02-04
💡 一句话要点
提出One-DVA,一种自适应一维视频扩散自编码器,解决视频压缩和生成问题。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 视频自编码器 扩散模型 Transformer 自适应压缩 视频生成
📋 核心要点
- 现有视频自编码器存在固定压缩率、CNN架构不灵活和确定性解码器难以恢复细节等问题,限制了视频生成的质量和效率。
- One-DVA采用基于Transformer的自适应一维编码和扩散解码,通过变长dropout动态调整潜在向量长度,实现高效压缩和高质量重建。
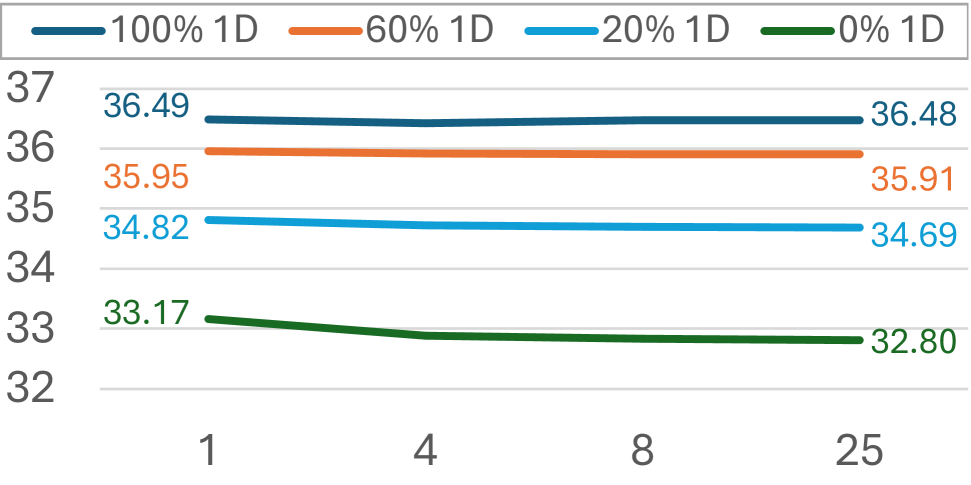
- 实验表明,One-DVA在重建指标上与3D-CNN VAE相当,并支持自适应压缩,同时通过正则化和微调提升了生成效果。
📝 摘要(中文)
本文提出了一种名为一维扩散视频自编码器(One-DVA)的框架,用于解决现有视频自编码器在视频生成中存在的局限性。这些局限性包括:固定压缩率导致简单视频的token浪费,CNN架构缺乏灵活性无法进行变长潜在空间建模,以及确定性解码器难以从压缩的潜在空间中恢复细节。One-DVA是一个基于Transformer的框架,采用自适应的一维编码和基于扩散的解码。编码器使用基于查询的视觉Transformer提取时空特征并生成潜在表示,同时使用变长dropout机制动态调整潜在向量的长度。解码器是一个像素空间的扩散Transformer,以潜在向量作为条件重建视频。通过两阶段训练策略,One-DVA在相同的压缩率下,重建指标上达到了与3D-CNN VAE相当的性能。更重要的是,它支持自适应压缩,从而实现更高的压缩率。为了更好地支持下游的潜在生成,本文进一步正则化One-DVA的潜在分布,并微调其解码器以减轻生成过程引起的伪影。
🔬 方法详解
问题定义:现有视频自编码器在压缩视频时存在三个主要问题:一是固定压缩率,对于内容简单的视频会浪费计算资源;二是CNN架构缺乏灵活性,难以适应变长的潜在表示;三是确定性解码器难以从高度压缩的潜在空间中恢复视频细节,导致重建质量下降。这些问题限制了视频压缩和生成的效率和质量。
核心思路:One-DVA的核心思路是利用Transformer的强大建模能力,结合自适应压缩和扩散模型,实现高效且高质量的视频自编码。具体来说,使用基于查询的Transformer进行时空特征提取,并通过变长dropout机制实现自适应压缩,最后使用扩散Transformer进行像素空间的视频重建。
技术框架:One-DVA的整体架构包含编码器和解码器两部分。编码器是一个基于查询的视觉Transformer,用于提取视频的时空特征,并生成潜在表示。编码器还包含一个变长dropout机制,用于动态调整潜在向量的长度,实现自适应压缩。解码器是一个像素空间的扩散Transformer,以编码器输出的潜在表示作为条件,逐步生成视频帧。整个框架采用两阶段训练策略,首先训练自编码器进行视频重建,然后正则化潜在空间并微调解码器以提升生成效果。
关键创新:One-DVA的关键创新在于以下几点:一是采用基于查询的Transformer进行时空特征提取,能够更好地捕捉视频中的动态信息;二是引入变长dropout机制,实现自适应的视频压缩,避免了对简单视频的资源浪费;三是使用扩散Transformer作为解码器,能够生成更加逼真的视频,并有效缓解确定性解码器带来的细节缺失问题。
关键设计:在编码器中,查询向量的设计至关重要,需要能够有效地捕捉视频中的时空信息。变长dropout机制的dropout率需要根据视频的内容进行动态调整,以实现最佳的压缩效果。在解码器中,扩散模型的噪声schedule和采样策略会影响生成视频的质量和速度。此外,损失函数的设计也需要考虑重建误差和潜在空间的正则化,以保证自编码器的性能和生成效果。
🖼️ 关键图片
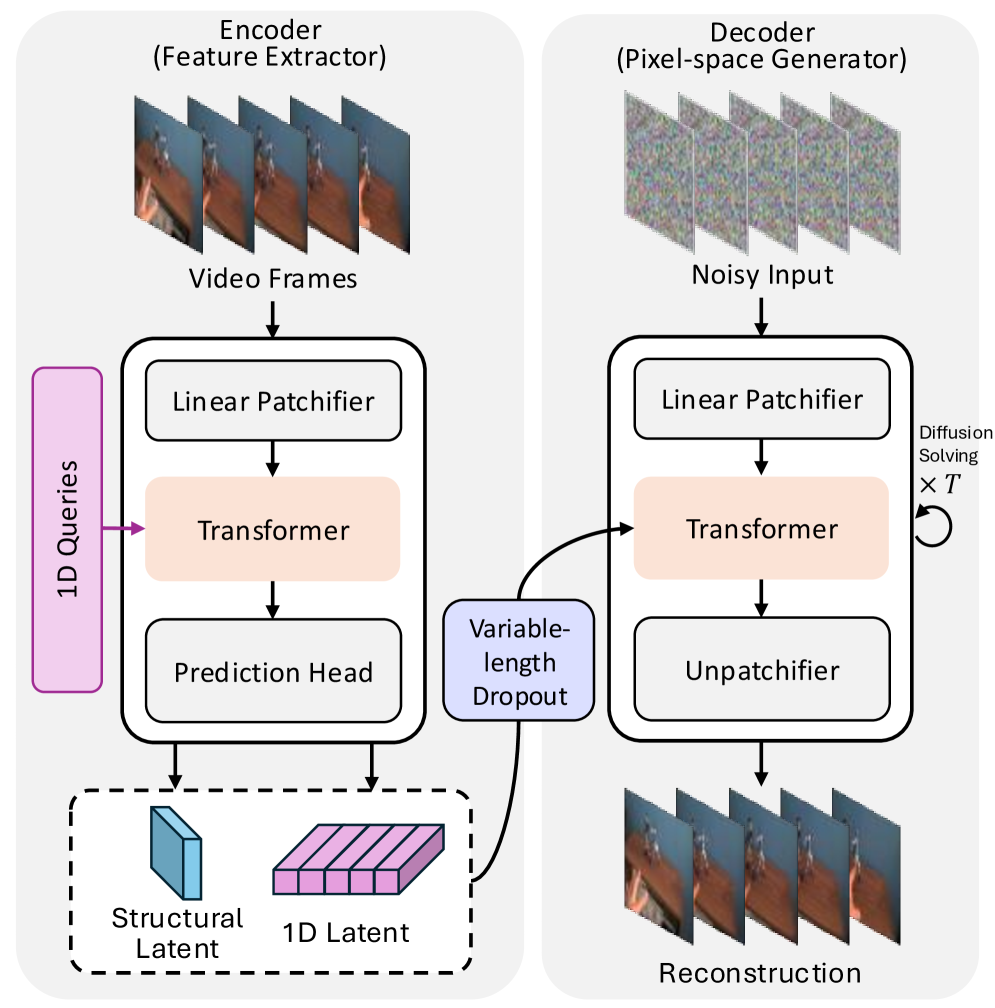

📊 实验亮点
One-DVA在重建指标上达到了与3D-CNN VAE相当的性能,同时支持自适应压缩,能够实现更高的压缩率。通过对潜在空间的正则化和解码器的微调,One-DVA能够生成更加逼真的视频,并有效缓解生成过程中的伪影问题。这些实验结果表明,One-DVA是一种有效的视频自编码器,具有良好的性能和潜力。
🎯 应用场景
One-DVA具有广泛的应用前景,包括视频压缩、视频生成、视频编辑、视频修复等。它可以用于开发更高效的视频编解码器,生成高质量的视频内容,实现智能化的视频编辑和修复功能。此外,One-DVA还可以应用于虚拟现实、增强现实等领域,为用户提供更加沉浸式的体验。
📄 摘要(原文)
Recent video generation models largely rely on video autoencoders that compress pixel-space videos into latent representations. However, existing video autoencoders suffer from three major limitations: (1) fixed-rate compression that wastes tokens on simple videos, (2) inflexible CNN architectures that prevent variable-length latent modeling, and (3) deterministic decoders that struggle to recover appropriate details from compressed latents. To address these issues, we propose One-Dimensional Diffusion Video Autoencoder (One-DVA), a transformer-based framework for adaptive 1D encoding and diffusion-based decoding. The encoder employs query-based vision transformers to extract spatiotemporal features and produce latent representations, while a variable-length dropout mechanism dynamically adjusts the latent length. The decoder is a pixel-space diffusion transformer that reconstructs videos with the latents as input conditions. With a two-stage training strategy, One-DVA achieves performance comparable to 3D-CNN VAEs on reconstruction metrics at identical compression ratios. More importantly, it supports adaptive compression and thus can achieve higher compression ratios. To better support downstream latent generation, we further regularize the One-DVA latent distribution for generative modeling and fine-tune its decoder to mitigate artifacts caused by the generation process.