DiMo: Discrete Diffusion Modeling for Motion Generation and Understanding
作者: Ning Zhang, Zhengyu Li, Kwong Weng Loh, Mingxi Xu, Qi Wang, Zhengyu Wen, Xiaoyu He, Wei Zhao, Kehong Gong, Mingyuan Zhang
分类: cs.CV
发布日期: 2026-02-04
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
DiMo:用于运动生成与理解的离散扩散模型,统一文本-运动双向任务。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 运动生成 运动理解 离散扩散模型 掩码建模 文本-运动双向任务
📋 核心要点
- 现有基于掩码建模的运动生成方法主要集中于文本到运动的生成,缺乏对运动理解能力的关注。
- DiMo采用离散扩散框架,通过迭代掩码token优化,统一处理文本到运动、运动到文本以及运动到运动的生成任务。
- 实验结果表明,DiMo在运动质量和双向理解方面表现出色,并且无需修改架构即可应用于多种运动生成任务。
📝 摘要(中文)
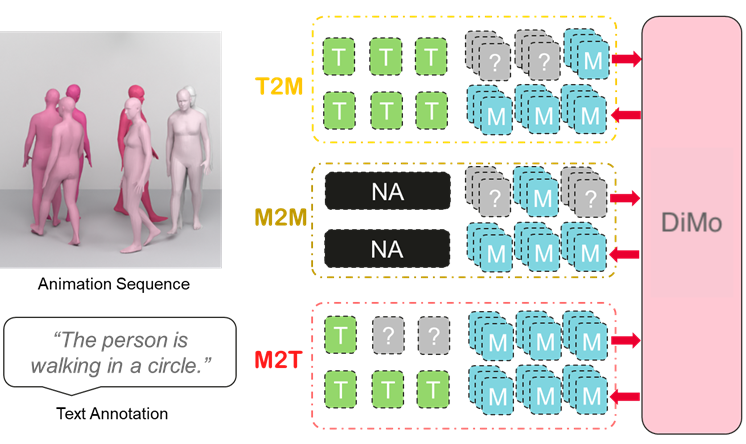
本文提出DiMo,一个离散扩散风格的框架,将掩码建模扩展到双向文本-运动理解和生成。与GPT风格的自回归方法不同,DiMo执行迭代的掩码token优化,在一个模型中统一了文本到运动(T2M)、运动到文本(M2T)和无文本的运动到运动(M2M)。这种解码范式自然地实现了推理时质量-延迟的权衡,通过调整优化步骤的数量。此外,我们使用残差向量量化(RVQ)来提高运动token的保真度,并使用组相对策略优化(GRPO)来增强对齐和可控性。在HumanML3D和KIT-ML上的实验表明,在一个统一的框架下,该模型具有强大的运动质量和有竞争力的双向理解能力。此外,我们展示了模型在无文本运动补全、文本引导运动预测和运动字幕校正方面的能力,而无需架构更改。
🔬 方法详解
问题定义:现有运动生成方法,特别是基于掩码建模的方法,主要关注文本到运动的生成,忽略了运动到文本的理解能力。此外,传统的自回归方法在处理运动数据时,通常需要将运动数据离散化为token序列,然后进行顺序解码,效率较低,且难以实现质量和延迟之间的平衡。
核心思路:DiMo的核心思路是利用离散扩散模型,通过迭代地对掩码的运动token进行优化,实现文本和运动之间的双向理解和生成。这种方法避免了自回归模型的顺序解码,允许并行处理,从而提高了效率。同时,通过调整优化步骤的数量,可以灵活地控制生成质量和延迟之间的权衡。
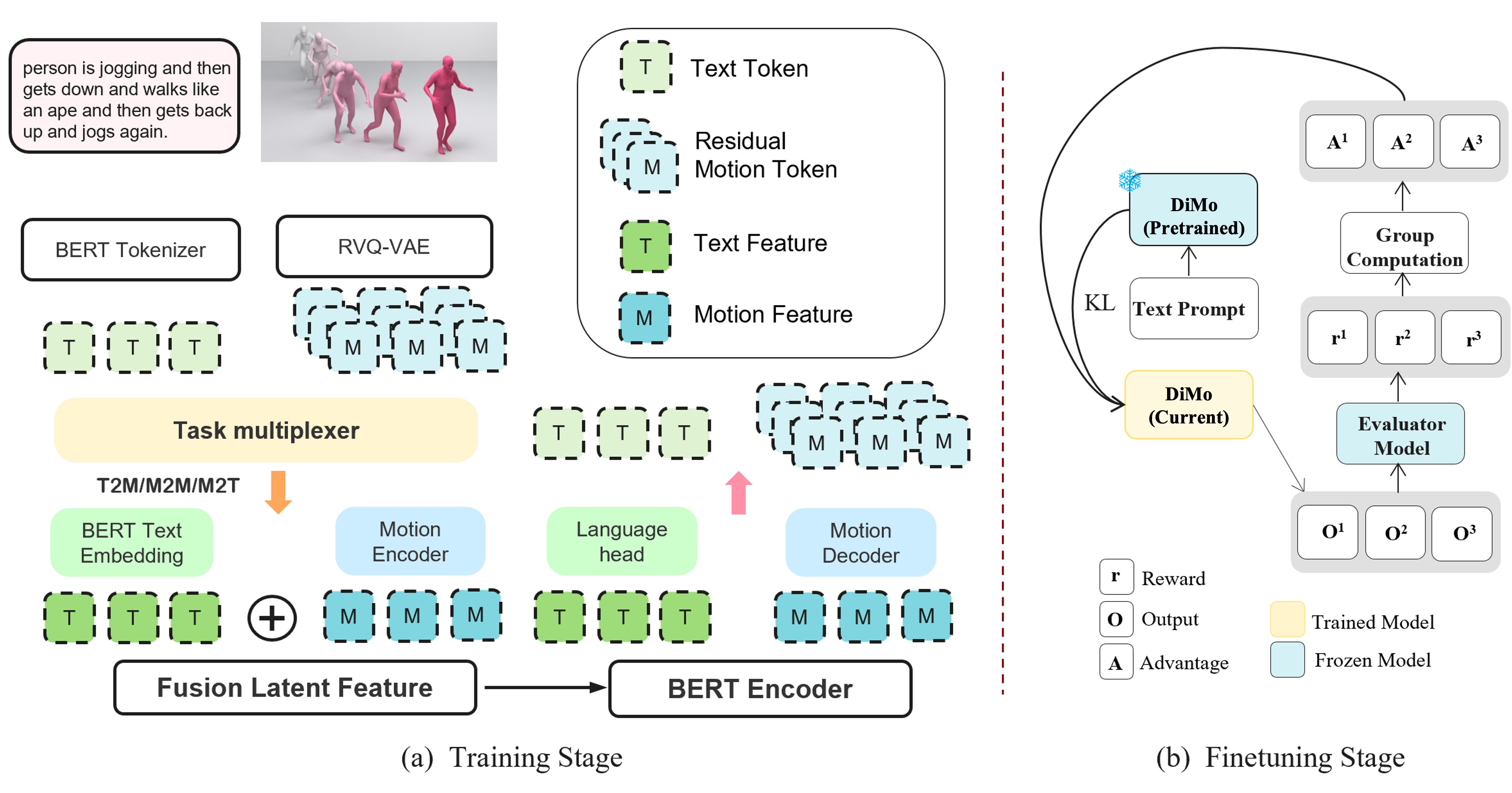
技术框架:DiMo的整体框架包括以下几个主要模块:1) 运动token化模块,使用残差向量量化(RVQ)将连续的运动数据转换为离散的token序列。2) 扩散模型,用于对掩码的运动token进行迭代优化。3) 文本编码器,用于将文本描述编码为向量表示。4) 交叉注意力机制,用于将文本和运动token进行对齐。整个流程可以概括为:输入文本和/或部分运动token,通过扩散模型迭代优化运动token,最终生成完整的运动序列或文本描述。
关键创新:DiMo的关键创新在于:1) 提出了一个统一的框架,可以同时处理文本到运动、运动到文本和运动到运动的生成任务。2) 采用了离散扩散模型,实现了高效的并行解码,并允许在质量和延迟之间进行灵活的权衡。3) 使用残差向量量化(RVQ)来提高运动token的保真度。4) 引入组相对策略优化(GRPO)来增强对齐和可控性。
关键设计:在运动token化方面,使用了多层残差向量量化(RVQ),以提高token的表达能力。在扩散模型方面,采用了标准的扩散过程,并使用Transformer作为扩散模型的骨干网络。在损失函数方面,使用了交叉熵损失来训练扩散模型,并使用组相对策略优化(GRPO)来增强文本和运动之间的对齐。具体的参数设置和网络结构细节可以在论文的实验部分找到。
🖼️ 关键图片

📊 实验亮点
DiMo在HumanML3D和KIT-ML数据集上取得了显著的成果。在文本到运动生成任务中,DiMo的运动质量与现有最佳方法相当,并且在运动到文本理解任务中,DiMo的表现优于现有方法。此外,DiMo还展示了在无文本运动补全、文本引导运动预测和运动字幕校正方面的能力,而无需修改架构。这些实验结果表明,DiMo是一个强大且通用的运动生成和理解模型。
🎯 应用场景
DiMo具有广泛的应用前景,包括:1) 动画和游戏制作:可以根据文本描述自动生成逼真的角色动画。2) 虚拟现实和增强现实:可以根据用户的动作生成相应的虚拟环境反馈。3) 机器人控制:可以根据文本指令控制机器人执行复杂的运动任务。4) 运动分析和康复:可以根据运动数据生成相应的文本描述,帮助医生进行诊断和治疗。未来,DiMo有望成为一个通用的运动生成和理解工具,推动相关领域的发展。
📄 摘要(原文)
Prior masked modeling motion generation methods predominantly study text-to-motion. We present DiMo, a discrete diffusion-style framework, which extends masked modeling to bidirectional text--motion understanding and generation. Unlike GPT-style autoregressive approaches that tokenize motion and decode sequentially, DiMo performs iterative masked token refinement, unifying Text-to-Motion (T2M), Motion-to-Text (M2T), and text-free Motion-to-Motion (M2M) within a single model. This decoding paradigm naturally enables a quality-latency trade-off at inference via the number of refinement steps.We further improve motion token fidelity with residual vector quantization (RVQ) and enhance alignment and controllability with Group Relative Policy Optimization (GRPO). Experiments on HumanML3D and KIT-ML show strong motion quality and competitive bidirectional understanding under a unified framework. In addition, we demonstrate model ability in text-free motion completion, text-guided motion prediction and motion caption correction without architectural change.Additional qualitative results are available on our project page: https://animotionlab.github.io/DiMo/.