JSynFlow: Japanese Synthesised Flowchart Visual Question Answering Dataset built with Large Language Models
作者: Hiroshi Sasaki
分类: cs.CV, cs.AI
发布日期: 2026-02-04
备注: 7 pages
期刊: Proceedings of the Annual Conference of JSAI, JSAI2025:2Win587-2Win587, 2025
DOI: 10.11517/pjsai.JSAI2025.0_2Win587
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
JSynFlow:利用大型语言模型构建的日语流程图视觉问答数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉问答 流程图理解 大型语言模型 数据集生成 领域特定语言
📋 核心要点
- 现有视觉语言模型在理解复杂文档(如流程图)方面存在挑战,缺乏大规模流程图数据集是主要瓶颈。
- JSynFlow通过大型语言模型自动生成流程图图像和对应的问答对,从而高效构建大规模数据集。
- 实验表明,使用JSynFlow数据集微调视觉语言模型,能够显著提升其在流程图问答任务上的性能。
📝 摘要(中文)
视觉和语言模型(VLM)有望通过问答(QA)界面分析包含流程图等复杂文档。识别和解释这些流程图的能力需求很高,因为它们提供了仅文本解释无法提供的宝贵见解。然而,开发具有精确流程图理解能力的VLM需要大规模的流程图图像和相应的文本数据集,而创建这些数据集非常耗时。为了解决这个挑战,我们引入了JSynFlow,这是一个使用大型语言模型(LLM)生成的日语流程图合成视觉问答数据集。我们的数据集包括各种业务职业的任务描述、从领域特定语言(DSL)代码渲染的相应流程图图像以及相关的QA对。本文详细介绍了数据集的合成过程,并证明使用JSynFlow进行微调可以显著提高VLM在基于流程图的QA任务中的性能。我们的数据集可在https://huggingface.co/datasets/jri-advtechlab/jsynflow公开获取。
🔬 方法详解
问题定义:论文旨在解决视觉语言模型在理解和回答关于流程图的问题时面临的挑战。现有方法依赖于人工标注的大规模流程图数据集,但人工标注耗时耗力,限制了模型的发展。因此,需要一种自动生成流程图数据集的方法,以降低数据获取成本,并促进视觉语言模型在流程图理解方面的研究。
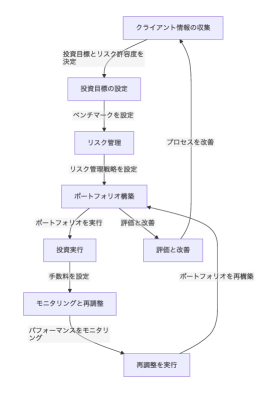
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大生成能力,自动生成流程图图像和对应的问答对。具体来说,首先使用LLM生成任务描述,然后将任务描述转换为领域特定语言(DSL)代码,再将DSL代码渲染成流程图图像,最后使用LLM生成与流程图相关的问答对。
技术框架:JSynFlow数据集的生成流程主要包括以下几个步骤:1) 使用LLM生成各种业务职业的任务描述;2) 将任务描述转换为DSL代码,这一步可以使用LLM或者其他代码生成工具;3) 将DSL代码渲染成流程图图像;4) 使用LLM生成与流程图相关的问答对。整个流程自动化,可以高效地生成大规模的流程图数据集。
关键创新:论文的关键创新在于提出了一种利用大型语言模型自动生成流程图视觉问答数据集的方法。该方法无需人工标注,可以高效地生成大规模数据集,解决了现有方法数据获取成本高的问题。此外,该方法生成的流程图数据集具有多样性和真实性,可以有效地提升视觉语言模型在流程图理解方面的性能。
关键设计:在生成问答对时,论文可能采用了特定的prompt工程技术,以确保生成的问题具有多样性和挑战性,并且答案与流程图内容相关。此外,在将任务描述转换为DSL代码时,可能需要设计合适的DSL语法和语义,以确保生成的流程图图像具有可读性和可理解性。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文通过实验证明,使用JSynFlow数据集微调视觉语言模型,可以显著提高其在流程图问答任务上的性能。具体的性能数据和提升幅度在摘要中未给出,需要查阅论文正文获取更详细的实验结果。但结论是,JSynFlow数据集对于提升VLM在流程图理解方面的能力是有效的。
🎯 应用场景
该研究成果可应用于自动化文档理解、智能办公助手、教育培训等领域。例如,可以帮助用户快速理解复杂的业务流程,提高工作效率;也可以用于开发智能教学系统,辅助学生学习流程图相关知识。未来,该技术有望扩展到其他类型的图表和文档理解任务。
📄 摘要(原文)
Vision and language models (VLMs) are expected to analyse complex documents, such as those containing flowcharts, through a question-answering (QA) interface. The ability to recognise and interpret these flowcharts is in high demand, as they provide valuable insights unavailable in text-only explanations. However, developing VLMs with precise flowchart understanding requires large-scale datasets of flowchart images and corresponding text, the creation of which is highly time-consuming. To address this challenge, we introduce JSynFlow, a synthesised visual QA dataset for Japanese flowcharts, generated using large language models (LLMs). Our dataset comprises task descriptions for various business occupations, the corresponding flowchart images rendered from domain-specific language (DSL) code, and related QA pairs. This paper details the dataset's synthesis procedure and demonstrates that fine-tuning with JSynFlow significantly improves VLM performance on flowchart-based QA tasks. Our dataset is publicly available at https://huggingface.co/datasets/jri-advtechlab/jsynflow.