LIVE: Long-horizon Interactive Video World Modeling
作者: Junchao Huang, Ziyang Ye, Xinting Hu, Tianyu He, Guiyu Zhang, Shaoshuai Shi, Jiang Bian, Li Jiang
分类: cs.CV
发布日期: 2026-02-03
备注: 18 pages, 22 figures
💡 一句话要点
LIVE:通过循环一致性约束实现长时交互视频世界建模
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视频世界模型 长时预测 循环一致性 扩散模型 自回归模型
📋 核心要点
- 现有自回归视频世界模型在长时预测中面临误差累积问题,导致生成质量下降。
- LIVE通过循环一致性约束,显式限制长时误差传播,无需依赖教师模型蒸馏。
- 实验证明LIVE在长时视频生成任务上优于现有方法,生成视频质量更高、更稳定。
📝 摘要(中文)
自回归视频世界模型旨在预测在动作条件下的未来视觉观测。虽然在短时间内有效,但这些模型通常难以进行长时生成,因为小的预测误差会随时间累积。现有方法通过引入预训练的教师模型和序列级分布匹配来缓解这个问题,但这会产生额外的计算成本,并且无法阻止超出训练范围的误差传播。本文提出了LIVE,一种长时交互视频世界模型,它通过一种新颖的循环一致性目标来强制执行有界的误差累积,从而消除了对基于教师的蒸馏的需求。具体来说,LIVE首先从真实帧执行前向展开,然后应用反向生成过程来重建初始状态。随后在重建的终端状态上计算扩散损失,从而对长时误差传播提供显式约束。此外,我们提供了一个统一的视角来涵盖不同的方法,并引入渐进式训练课程来稳定训练。实验表明,LIVE在长时基准测试中实现了最先进的性能,生成了远远超出训练范围的稳定、高质量的视频。
🔬 方法详解
问题定义:论文旨在解决长时交互视频世界建模中,自回归模型预测误差随时间累积的问题。现有方法如教师模型蒸馏和序列级分布匹配,计算成本高,且无法有效防止超出训练范围的误差传播。
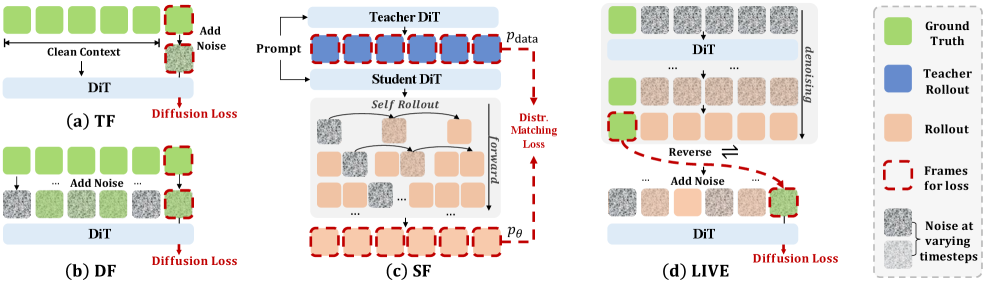
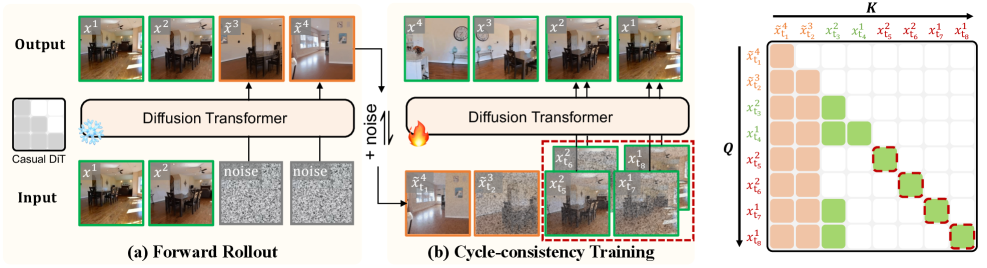
核心思路:论文的核心思路是引入循环一致性约束,即从真实帧进行前向预测,再从预测结果反向重建初始状态。通过约束重建后的状态与初始状态的一致性,从而限制长时误差的累积。这种方法无需依赖额外的教师模型,降低了计算复杂度。
技术框架:LIVE模型包含前向生成和反向重建两个主要阶段。前向生成阶段,模型根据当前帧和动作预测未来帧;反向重建阶段,模型从预测的未来帧和反向动作重建初始帧。在重建的终端状态上计算扩散损失,用于约束重建状态与初始状态的差异。此外,论文还提出了一个统一的视角来涵盖不同的方法,并引入渐进式训练课程来稳定训练。
关键创新:最重要的技术创新点是循环一致性约束,它提供了一种显式的方法来限制长时误差传播,而无需依赖教师模型。这种方法能够生成更稳定、更高质量的长时视频,并且可以推广到不同的视频世界模型架构中。
关键设计:论文使用扩散模型作为生成模型,并设计了相应的扩散损失来约束重建状态。此外,论文还采用了渐进式训练课程,逐步增加训练序列的长度,以提高模型的稳定性和泛化能力。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LIVE在多个长时视频生成基准测试中取得了state-of-the-art的性能。相较于现有方法,LIVE能够生成更稳定、更高质量的视频,并且能够有效防止误差累积。在超出训练范围的序列长度上,LIVE仍然能够保持良好的生成效果。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、游戏AI等领域。通过预测环境的长期变化,机器人可以更好地规划路径和执行任务。在自动驾驶中,可以预测其他车辆和行人的行为,提高安全性。在游戏AI中,可以生成更逼真的游戏场景和角色行为。
📄 摘要(原文)
Autoregressive video world models predict future visual observations conditioned on actions. While effective over short horizons, these models often struggle with long-horizon generation, as small prediction errors accumulate over time. Prior methods alleviate this by introducing pre-trained teacher models and sequence-level distribution matching, which incur additional computational cost and fail to prevent error propagation beyond the training horizon. In this work, we propose LIVE, a Long-horizon Interactive Video world modEl that enforces bounded error accumulation via a novel cycle-consistency objective, thereby eliminating the need for teacher-based distillation. Specifically, LIVE first performs a forward rollout from ground-truth frames and then applies a reverse generation process to reconstruct the initial state. The diffusion loss is subsequently computed on the reconstructed terminal state, providing an explicit constraint on long-horizon error propagation. Moreover, we provide an unified view that encompasses different approaches and introduce progressive training curriculum to stabilize training. Experiments demonstrate that LIVE achieves state-of-the-art performance on long-horizon benchmarks, generating stable, high-quality videos far beyond training rollout lengths.