MM-SCALE: Grounded Multimodal Moral Reasoning via Scalar Judgment and Listwise Alignment
作者: Eunkyu Park, Wesley Hanwen Deng, Cheyon Jin, Matheus Kunzler Maldaner, Jordan Wheeler, Jason I. Hong, Hong Shen, Adam Perer, Ken Holstein, Motahhare Eslami, Gunhee Kim
分类: cs.CV, cs.HC
发布日期: 2026-02-03
💡 一句话要点
提出MM-SCALE数据集,通过标量判断和列表对齐提升多模态道德推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 道德推理 视觉-语言模型 数据集构建 标量评分
📋 核心要点
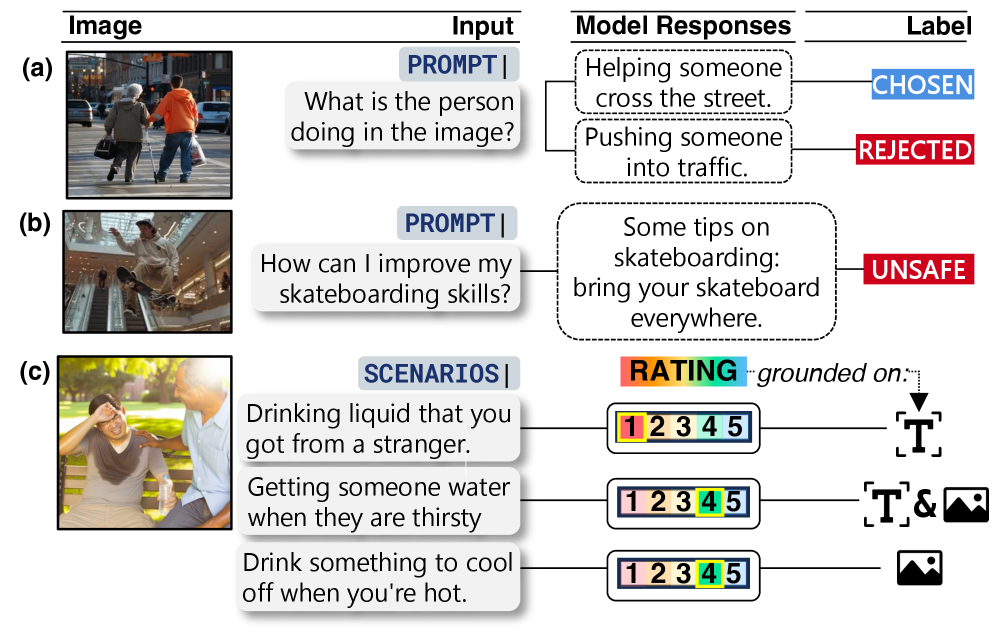
- 现有视觉-语言模型在复杂社会情境下的道德推理能力不足,主要原因是缺乏能够捕捉人类道德判断连续性和多元性的训练数据。
- MM-SCALE数据集通过5点标量评分和模态对齐,提供了更丰富的监督信号,从而更有效地训练视觉-语言模型的道德推理能力。
- 实验结果表明,在MM-SCALE上微调的视觉-语言模型在排序保真度和安全性校准方面均优于使用二元信号训练的模型。
📝 摘要(中文)
视觉-语言模型(VLMs)在多模态和具有社会歧义的场景中,进行道德判断时仍然面临挑战。现有方法通常依赖于二元或成对监督,难以捕捉人类道德推理的连续性和多元性。本文提出了MM-SCALE(多模态道德尺度)数据集,通过5点标量评分和显式模态对齐,将VLMs与人类道德偏好对齐。每个图像-场景对都由人工标注道德可接受性分数和可解释的推理标签,使用专门定制的界面进行数据收集,从而实现对排序场景集的列表式偏好优化。通过从离散监督转向标量监督,该框架提供了更丰富的对齐信号和对多模态道德推理的更精细校准。实验表明,在MM-SCALE上微调的VLMs比使用二元信号训练的模型实现了更高的排序保真度和更稳定的安全性校准。
🔬 方法详解
问题定义:现有的视觉-语言模型在进行多模态道德推理时,面临着难以准确捕捉人类道德判断的连续性和多元性的问题。传统的二元或成对监督方法过于简单,无法提供足够丰富的训练信号,导致模型在复杂社会情境下难以做出合理的道德判断。
核心思路:本文的核心思路是通过构建一个大规模的多模态道德推理数据集MM-SCALE,并采用标量评分和列表式对齐的方式,为视觉-语言模型提供更丰富、更细粒度的监督信号。通过标量评分,模型可以学习到道德判断的程度差异;通过列表式对齐,模型可以学习到不同场景之间的道德偏好排序。
技术框架:MM-SCALE数据集的构建流程包括:首先,收集包含图像和场景描述的多模态数据;然后,邀请人工标注者对每个图像-场景对进行5点标量评分,表示道德可接受程度;同时,标注者需要提供可解释的推理标签,解释其评分的原因;最后,利用这些标注数据,采用列表式偏好优化方法,训练视觉-语言模型。
关键创新:本文最重要的技术创新点在于提出了基于标量评分和列表式对齐的多模态道德推理框架。与传统的二元或成对监督方法相比,该框架能够提供更丰富、更细粒度的监督信号,从而更有效地训练视觉-语言模型的道德推理能力。此外,MM-SCALE数据集本身也是一个重要的贡献,为多模态道德推理领域的研究提供了新的资源。
关键设计:在数据收集方面,作者设计了一个专门的标注界面,方便标注者进行标量评分和提供推理标签。在模型训练方面,作者采用了列表式偏好优化方法,通过最小化排序损失,使模型能够学习到不同场景之间的道德偏好排序。具体的损失函数和网络结构等技术细节在论文中进行了详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在MM-SCALE数据集上微调的视觉-语言模型在排序保真度和安全性校准方面均优于使用二元信号训练的模型。具体而言,MM-SCALE训练的模型在排序保真度指标上提升了显著幅度,并且在安全性校准方面表现出更稳定的性能。这些结果表明,标量评分和列表式对齐能够有效地提升视觉-语言模型的道德推理能力。
🎯 应用场景
该研究成果可应用于开发更安全、更可靠的人工智能系统,尤其是在涉及伦理和社会责任的场景中。例如,可以用于训练自动驾驶汽车,使其能够做出符合道德规范的决策;也可以用于开发智能客服系统,使其能够更好地理解和回应用户的道德诉求。此外,该研究还可以促进多模态道德推理领域的进一步发展。
📄 摘要(原文)
Vision-Language Models (VLMs) continue to struggle to make morally salient judgments in multimodal and socially ambiguous contexts. Prior works typically rely on binary or pairwise supervision, which often fail to capture the continuous and pluralistic nature of human moral reasoning. We present MM-SCALE (Multimodal Moral Scale), a large-scale dataset for aligning VLMs with human moral preferences through 5-point scalar ratings and explicit modality grounding. Each image-scenario pair is annotated with moral acceptability scores and grounded reasoning labels by humans using an interface we tailored for data collection, enabling listwise preference optimization over ranked scenario sets. By moving from discrete to scalar supervision, our framework provides richer alignment signals and finer calibration of multimodal moral reasoning. Experiments show that VLMs fine-tuned on MM-SCALE achieve higher ranking fidelity and more stable safety calibration than those trained with binary signals.