Quasi-multimodal-based pathophysiological feature learning for retinal disease diagnosis
作者: Lu Zhang, Huizhen Yu, Zuowei Wang, Fu Gui, Yatu Guo, Wei Zhang, Mengyu Jia
分类: cs.CV, physics.med-ph
发布日期: 2026-02-03
期刊: Zhang, L., Yu, H., Wang, Z., Gui, F., Guo, Y., Zhang, W., Jia, M., 2026. Quasi-multimodal-based pathophysiological feature learning for retinal disease diagnosis. Medical Image Analysis 109, 103886
DOI: 10.1016/j.media.2025.103886
💡 一句话要点
提出基于准多模态的病理生理特征学习框架,用于视网膜疾病诊断。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视网膜疾病诊断 多模态融合 病理生理特征学习 数据合成 自适应校准
📋 核心要点
- 眼科多模态诊断面临数据异构性、潜在侵入性、配准复杂性等挑战,现有方法难以有效融合。
- 提出一种统一框架,通过多模态数据合成与融合,学习交叉病理生理特征,实现视网膜疾病诊断。
- 实验结果表明,该方法在多标签分类和糖尿病视网膜病变分级任务中均优于现有技术。
📝 摘要(中文)
本研究提出了一种统一的框架,用于整合多模态数据合成与融合,以实现视网膜疾病的分类和分级。该框架利用合成的多模态数据,包括眼底荧光血管造影(FFA)、多光谱成像(MSI)以及突出潜在病变和视盘/杯区域的显著性图。通过独立训练并行模型,学习特定模态的表示,从而捕获交叉病理生理特征。这些特征在模态内部和模态之间进行自适应校准,以便根据下游任务执行信息修剪和灵活集成。通过图像和特征空间的可视化,对所提出的学习系统进行了全面解释。在两个公共数据集上的大量实验表明,该方法在多标签分类(F1-score: 0.683, AUC: 0.953)和糖尿病视网膜病变分级(Accuracy: 0.842, Kappa: 0.861)任务中优于现有技术。
🔬 方法详解
问题定义:视网膜疾病的诊断依赖于多模态数据,但现有方法难以有效处理多模态数据带来的异构性、潜在侵入性以及配准复杂性等问题。如何有效地融合多模态信息,提升视网膜疾病诊断的准确性和效率是本文要解决的核心问题。
核心思路:本文的核心思路是通过合成多模态数据,并利用并行模型学习模态特定的病理生理特征表示。通过自适应校准机制,在模态内部和模态之间进行信息修剪和灵活集成,从而实现更准确的疾病诊断。这种设计旨在克服数据异构性带来的挑战,并充分利用不同模态之间的互补信息。
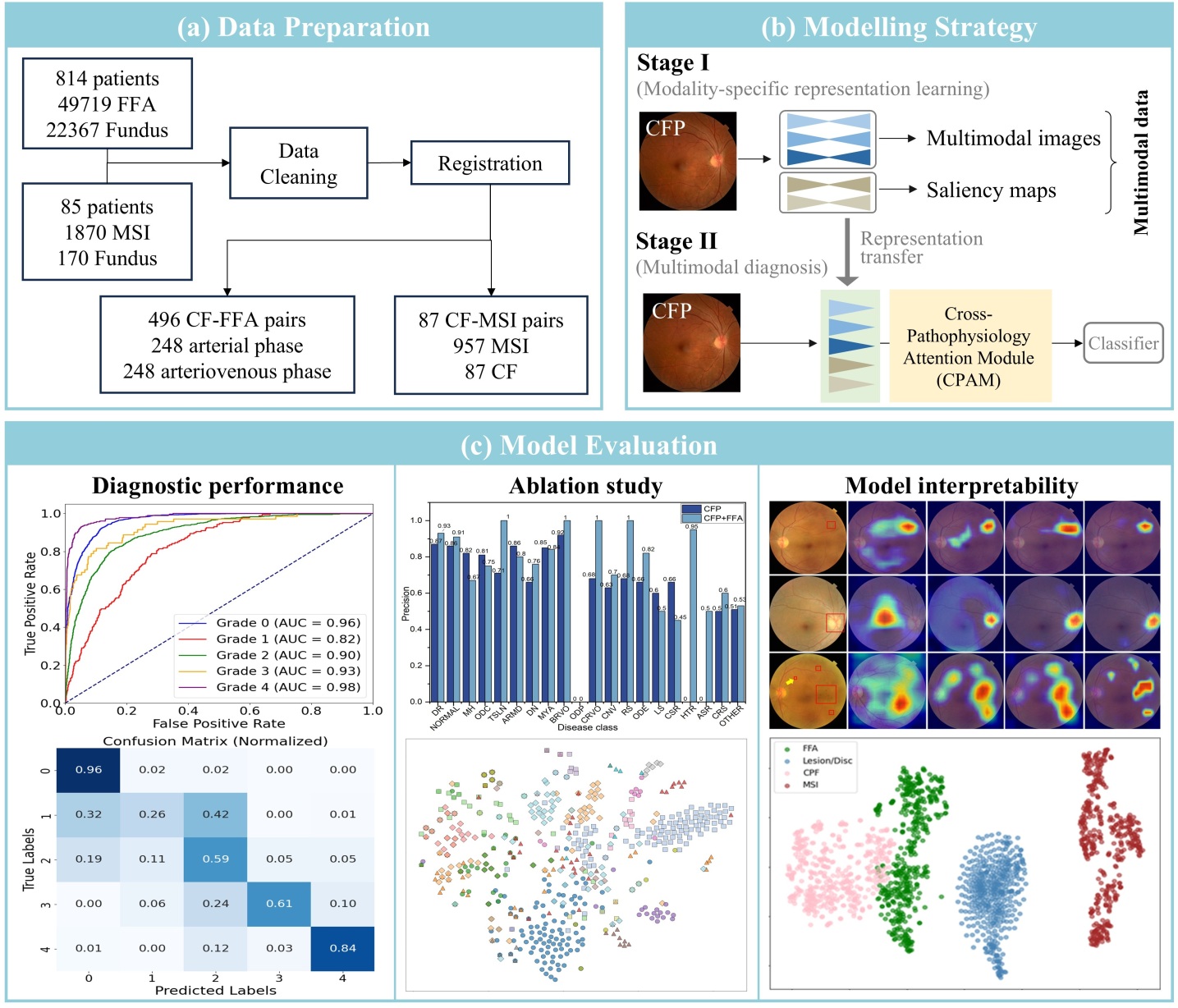
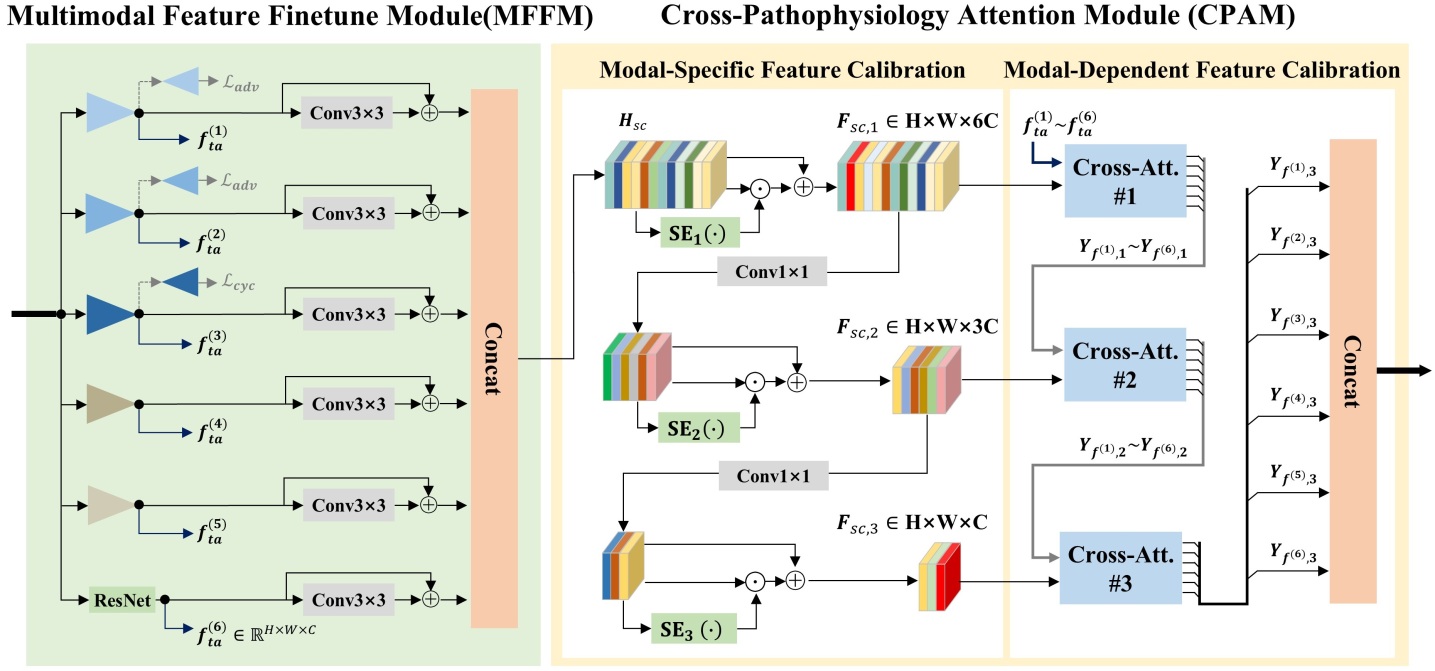
技术框架:该框架主要包含以下几个阶段:1) 多模态数据合成:利用FFA、MSI等数据,并结合显著性图,生成包含潜在病变和视盘/杯区域信息的合成多模态数据。2) 模态特定特征学习:通过并行训练的模型,学习不同模态的特征表示,捕获交叉病理生理特征。3) 特征自适应校准:在模态内部和模态之间进行特征校准,根据下游任务进行信息修剪和灵活集成。4) 疾病分类/分级:利用学习到的特征进行视网膜疾病的分类或分级。
关键创新:该方法的主要创新点在于:1) 提出了基于准多模态数据合成的方法,有效缓解了数据异构性问题。2) 引入了自适应校准机制,能够根据下游任务动态地调整不同模态信息的权重,实现更灵活的信息融合。3) 通过可视化技术,对学习系统进行了全面解释,增强了模型的可解释性。
关键设计:论文中涉及的关键设计包括:1) 显著性图的生成方法,用于突出图像中的关键区域。2) 并行模型的网络结构选择,需要根据不同模态数据的特点进行调整。3) 自适应校准机制的具体实现方式,例如使用注意力机制或门控机制来动态调整特征权重。4) 损失函数的选择,需要综合考虑分类/分级任务的需求,例如可以使用交叉熵损失或Kappa损失。
🖼️ 关键图片

📊 实验亮点
该方法在两个公共数据集上进行了广泛的实验,结果表明其在多标签分类任务中取得了0.683的F1-score和0.953的AUC,在糖尿病视网膜病变分级任务中取得了0.842的准确率和0.861的Kappa系数。相较于现有技术,该方法在各项指标上均有显著提升,验证了其有效性。
🎯 应用场景
该研究成果可应用于视网膜疾病的早期筛查、诊断和分级,辅助医生进行更准确的判断。该框架具有良好的可扩展性,可以推广到其他医学影像模态,为多种疾病的诊断提供支持。未来,该技术有望集成到智能医疗系统中,提高医疗效率,降低医疗成本。
📄 摘要(原文)
Retinal diseases spanning a broad spectrum can be effectively identified and diagnosed using complementary signals from multimodal data. However, multimodal diagnosis in ophthalmic practice is typically challenged in terms of data heterogeneity, potential invasiveness, registration complexity, and so on. As such, a unified framework that integrates multimodal data synthesis and fusion is proposed for retinal disease classification and grading. Specifically, the synthesized multimodal data incorporates fundus fluorescein angiography (FFA), multispectral imaging (MSI), and saliency maps that emphasize latent lesions as well as optic disc/cup regions. Parallel models are independently trained to learn modality-specific representations that capture cross-pathophysiological signatures. These features are then adaptively calibrated within and across modalities to perform information pruning and flexible integration according to downstream tasks. The proposed learning system is thoroughly interpreted through visualizations in both image and feature spaces. Extensive experiments on two public datasets demonstrated the superiority of our approach over state-of-the-art ones in the tasks of multi-label classification (F1-score: 0.683, AUC: 0.953) and diabetic retinopathy grading (Accuracy:0.842, Kappa: 0.861). This work not only enhances the accuracy and efficiency of retinal disease screening but also offers a scalable framework for data augmentation across various medical imaging modalities.