A Lightweight Library for Energy-Based Joint-Embedding Predictive Architectures
作者: Basile Terver, Randall Balestriero, Megi Dervishi, David Fan, Quentin Garrido, Tushar Nagarajan, Koustuv Sinha, Wancong Zhang, Mike Rabbat, Yann LeCun, Amir Bar
分类: cs.CV, cs.AI
发布日期: 2026-02-03
🔗 代码/项目: GITHUB
💡 一句话要点
提出EB-JEPA轻量级库,用于能量模型联合嵌入预测架构的学习与应用。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 联合嵌入 自监督学习 表征学习 世界模型 能量模型
📋 核心要点
- 现有生成模型在像素空间预测存在缺陷,难以捕捉语义信息,限制了其在下游任务中的应用。
- EB-JEPA库通过在表征空间进行预测,避免了生成建模的缺陷,并学习到更具语义信息的特征。
- 实验表明,EB-JEPA在图像、视频和动作条件世界模型中均表现良好,并具有良好的可扩展性。
📝 摘要(中文)
本文介绍了一个开源库EB-JEPA,用于使用联合嵌入预测架构(JEPAs)学习表征和世界模型。JEPAs在表征空间而非像素空间中进行预测,避免了生成建模的缺陷,同时捕获了适用于下游任务的语义上有意义的特征。该库提供模块化、自包含的实现,展示了为图像级自监督学习开发的表征学习技术如何迁移到视频(其中时间动态增加了复杂性),并最终迁移到动作条件世界模型(其中模型必须额外学习预测控制输入的效果)。每个示例都设计为在几个小时内在单个GPU上进行训练,从而使基于能量的自监督学习可用于研究和教育。在CIFAR-10上进行了JEA组件的消融实验,探测这些表征可达到91%的准确率,表明该模型学习了有用的特征。扩展到视频,包含了一个在Moving MNIST上的多步预测示例,展示了相同的原则如何扩展到时间建模。最后,展示了这些表征如何驱动动作条件世界模型,在Two Rooms导航任务上实现了97%的规划成功率。全面的消融实验揭示了每个正则化组件对于防止表征崩溃的关键重要性。代码可在https://github.com/facebookresearch/eb_jepa获得。
🔬 方法详解
问题定义:现有方法,特别是基于生成模型的自监督学习,通常直接在像素空间进行预测,计算量大,且容易受到图像细节的干扰,难以学习到具有鲁棒性和泛化能力的语义表征。这限制了它们在复杂任务(如视频理解和机器人控制)中的应用。
核心思路:EB-JEPA的核心思路是使用联合嵌入预测架构(JEPAs),在表征空间而非像素空间进行预测。通过学习不同视角或时间步长的输入之间的共享表征,模型可以更好地捕捉数据中的不变性和结构信息,从而学习到更具语义意义的特征。这种方法避免了生成模型的像素级重建,降低了计算复杂度,并提高了模型的鲁棒性。
技术框架:EB-JEPA库提供了一系列模块化的组件,用于构建JEPAs模型。整体流程通常包括以下几个步骤:1) 输入数据经过编码器(Encoder)提取特征;2) 编码后的特征被输入到预测器(Predictor)中,预测目标表征;3) 使用能量函数(Energy Function)衡量预测表征与目标表征之间的相似度;4) 通过优化能量函数,学习编码器和预测器的参数。该框架支持多种编码器、预测器和能量函数的选择,可以灵活地适应不同的任务和数据集。
关键创新:EB-JEPA的关键创新在于其通用性和模块化设计,使得研究人员可以轻松地构建和实验不同的JEPAs模型。它将图像自监督学习的技术扩展到视频和动作条件世界模型,展示了JEPAs在不同领域的潜力。此外,该库强调了正则化在防止表征崩溃中的重要性,并提供了一系列有效的正则化方法。
关键设计:EB-JEPA库的关键设计包括:1) 模块化的编码器、预测器和能量函数,方便用户自定义模型结构;2) 多种正则化方法,如对比学习损失、一致性损失等,用于防止表征崩溃;3) 针对不同任务的示例代码,包括CIFAR-10图像分类、Moving MNIST视频预测和Two Rooms导航任务;4) 详细的消融实验,分析了不同组件和正则化方法对模型性能的影响。
🖼️ 关键图片


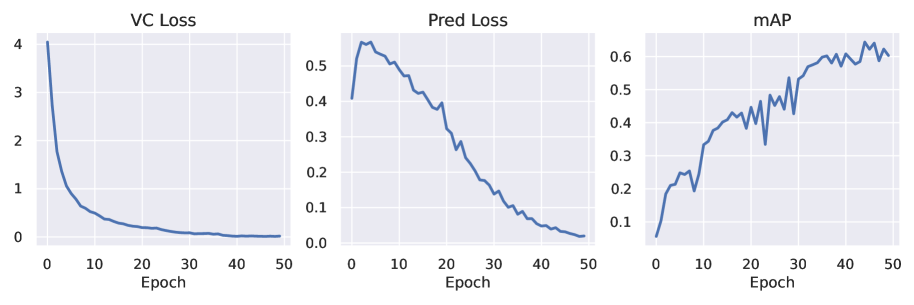
📊 实验亮点
EB-JEPA在CIFAR-10上进行表征探测,达到了91%的准确率,证明了其学习到的特征的有效性。在Moving MNIST视频预测任务中,展示了其在时间建模方面的能力。在Two Rooms导航任务中,使用EB-JEPA学习到的表征驱动动作条件世界模型,实现了97%的规划成功率。消融实验强调了正则化组件对于防止表征崩溃的重要性。
🎯 应用场景
EB-JEPA库可应用于多种领域,包括图像和视频理解、机器人控制、强化学习等。通过学习高质量的表征,可以提升下游任务的性能,例如目标检测、视频分类、运动规划等。该库的轻量级和易用性使其成为研究和教育的理想工具,有助于推动自监督学习和世界模型的发展。
📄 摘要(原文)
We present EB-JEPA, an open-source library for learning representations and world models using Joint-Embedding Predictive Architectures (JEPAs). JEPAs learn to predict in representation space rather than pixel space, avoiding the pitfalls of generative modeling while capturing semantically meaningful features suitable for downstream tasks. Our library provides modular, self-contained implementations that illustrate how representation learning techniques developed for image-level self-supervised learning can transfer to video, where temporal dynamics add complexity, and ultimately to action-conditioned world models, where the model must additionally learn to predict the effects of control inputs. Each example is designed for single-GPU training within a few hours, making energy-based self-supervised learning accessible for research and education. We provide ablations of JEA components on CIFAR-10. Probing these representations yields 91% accuracy, indicating that the model learns useful features. Extending to video, we include a multi-step prediction example on Moving MNIST that demonstrates how the same principles scale to temporal modeling. Finally, we show how these representations can drive action-conditioned world models, achieving a 97% planning success rate on the Two Rooms navigation task. Comprehensive ablations reveal the critical importance of each regularization component for preventing representation collapse. Code is available at https://github.com/facebookresearch/eb_jepa.