SlowFocus: Enhancing Fine-grained Temporal Understanding in Video LLM
作者: Ming Nie, Dan Ding, Chunwei Wang, Yuanfan Guo, Jianhua Han, Hang Xu, Li Zhang
分类: cs.CV
发布日期: 2026-02-03
备注: NeurIPS 2024
💡 一句话要点
提出SlowFocus机制,增强视频LLM对细粒度时序信息的理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频LLM 时序理解 细粒度分析 自适应采样 多频注意力
📋 核心要点
- 现有Vid-LLM难以兼顾帧级别语义信息和视频级别时序信息,限制了其在细粒度视频理解上的应用。
- SlowFocus机制通过对查询相关的时间段进行密集采样,提取局部高频特征,并结合全局低频上下文,提升时序理解。
- 论文提出了针对SlowFocus机制的训练策略,并构建了FineAction-CGR基准,实验验证了该机制的有效性。
📝 摘要(中文)
大型语言模型(LLMs)在文本理解方面表现出卓越的能力,这为它们扩展到视频LLMs(Vid-LLMs)以分析视频数据铺平了道路。然而,当前的Vid-LLMs难以同时保持高质量的帧级别语义信息(即,每个帧有足够数量的tokens)和全面的视频级别时序信息(即,每个视频采样足够数量的帧)。这种限制阻碍了Vid-LLMs向细粒度视频理解的发展。为了解决这个问题,我们引入了SlowFocus机制,该机制在不影响帧级别视觉tokens质量的前提下,显著提高了等效采样频率。SlowFocus首先基于提出的问题识别与查询相关的时间段,然后对该时间段执行密集采样以提取局部高频特征。进一步利用多频混合注意力模块将这些局部高频细节与全局低频上下文聚合,以增强时间理解。此外,为了使Vid-LLMs适应这种创新机制,我们引入了一组训练策略,旨在加强时间定位和详细的时间推理能力。此外,我们建立了一个专门设计的基准FineAction-CGR,以评估Vid-LLMs处理细粒度时间理解任务的能力。全面的实验表明,我们的机制在现有的公共视频理解基准和我们提出的FineAction-CGR上都具有优越性。
🔬 方法详解
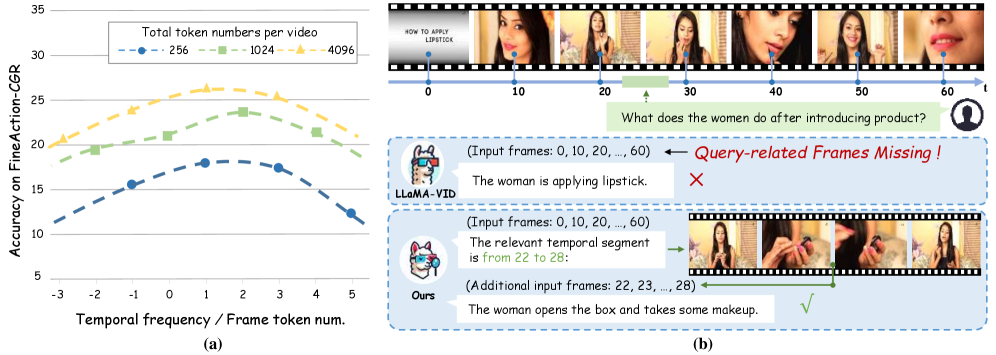
问题定义:现有的视频LLM在处理视频时,需要在帧级别的语义信息(每个帧的token数量)和视频级别的时序信息(采样的帧数量)之间进行权衡。如果采样帧数不足,则无法捕捉到视频中的细粒度时序变化,导致对视频内容的理解不足。现有方法难以在计算资源有限的情况下,同时保证帧级别语义信息的质量和视频级别的时序信息覆盖度。
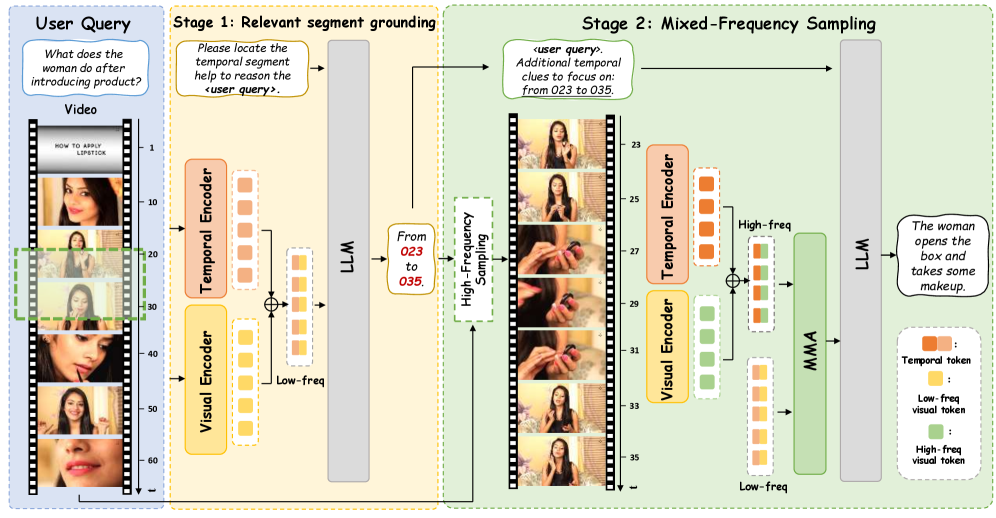
核心思路:SlowFocus的核心思想是根据用户提出的问题,聚焦于视频中与问题相关的特定时间段,并对该时间段进行高密度的采样。这样可以在不增加整体计算负担的前提下,提高对关键时间段的关注度,从而更好地理解视频中的细粒度时序信息。通过局部高频特征提取和全局低频上下文融合,实现更精确的时序理解。
技术框架:SlowFocus机制主要包含以下几个阶段:1) 查询相关时间段识别:根据用户提出的问题,确定视频中与问题最相关的起始和结束时间点。2) 密集采样:对识别出的时间段进行高密度采样,提取局部高频特征。3) 多频混合注意力:利用多频混合注意力模块,将局部高频特征与全局低频上下文信息进行融合,增强模型对时序信息的理解。4) 视频LLM:将融合后的特征输入到视频LLM中,进行最终的视频理解和推理。
关键创新:SlowFocus机制的关键创新在于其自适应的采样策略。与传统的均匀采样或随机采样不同,SlowFocus能够根据用户提出的问题,动态地调整采样密度,从而更加高效地利用计算资源,并提高对关键时间段的关注度。这种自适应采样策略使得模型能够在不增加整体计算负担的前提下,更好地理解视频中的细粒度时序信息。
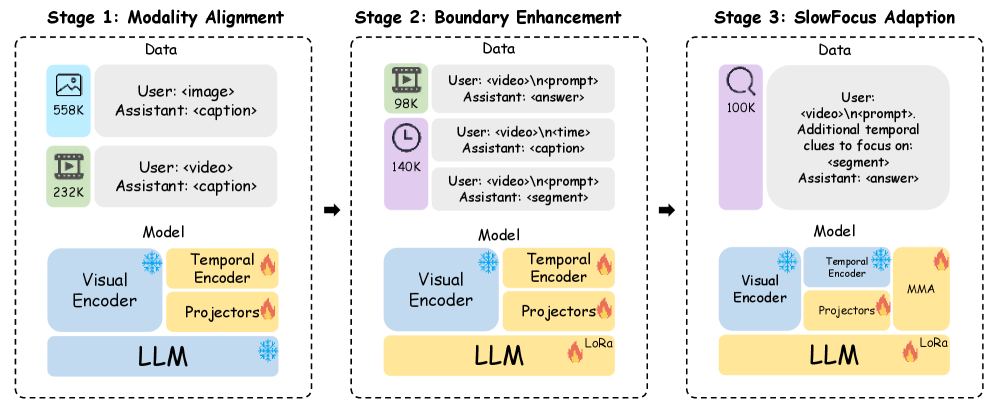
关键设计:在时间段识别阶段,可以使用文本相似度匹配等方法来确定与问题相关的时间段。在多频混合注意力模块中,可以采用不同的注意力机制来融合局部高频特征和全局低频上下文信息,例如,可以使用自注意力机制来捕捉局部高频特征之间的依赖关系,并使用交叉注意力机制来融合局部高频特征和全局低频上下文信息。此外,论文还提出了一系列训练策略,包括时间定位和详细时间推理,以提升Vid-LLM对时序信息的理解能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SlowFocus机制在多个视频理解基准测试中取得了显著的性能提升。特别是在FineAction-CGR基准测试中,SlowFocus机制表现出优越的细粒度时序理解能力。相比于现有方法,SlowFocus机制能够在不增加计算负担的前提下,显著提高视频LLM对视频内容的理解能力。
🎯 应用场景
SlowFocus机制可以应用于各种需要细粒度时序理解的视频分析任务,例如视频摘要、动作识别、视频问答、视频编辑等。该机制能够帮助视频LLM更好地理解视频内容,从而提高这些任务的性能。此外,该机制还可以应用于智能监控、自动驾驶等领域,提高系统的感知能力和决策能力。
📄 摘要(原文)
Large language models (LLMs) have demonstrated exceptional capabilities in text understanding, which has paved the way for their expansion into video LLMs (Vid-LLMs) to analyze video data. However, current Vid-LLMs struggle to simultaneously retain high-quality frame-level semantic information (i.e., a sufficient number of tokens per frame) and comprehensive video-level temporal information (i.e., an adequate number of sampled frames per video). This limitation hinders the advancement of Vid-LLMs towards fine-grained video understanding. To address this issue, we introduce the SlowFocus mechanism, which significantly enhances the equivalent sampling frequency without compromising the quality of frame-level visual tokens. SlowFocus begins by identifying the query-related temporal segment based on the posed question, then performs dense sampling on this segment to extract local high-frequency features. A multi-frequency mixing attention module is further leveraged to aggregate these local high-frequency details with global low-frequency contexts for enhanced temporal comprehension. Additionally, to tailor Vid-LLMs to this innovative mechanism, we introduce a set of training strategies aimed at bolstering both temporal grounding and detailed temporal reasoning capabilities. Furthermore, we establish FineAction-CGR, a benchmark specifically devised to assess the ability of Vid-LLMs to process fine-grained temporal understanding tasks. Comprehensive experiments demonstrate the superiority of our mechanism across both existing public video understanding benchmarks and our proposed FineAction-CGR.