Decoupling Skeleton and Flesh: Efficient Multimodal Table Reasoning with Disentangled Alignment and Structure-aware Guidance
作者: Yingjie Zhu, Xuefeng Bai, Kehai Chen, Yang Xiang, Youcheng Pan, Xiaoqiang Zhou, Min Zhang
分类: cs.CV, cs.CL
发布日期: 2026-02-03
💡 一句话要点
提出DiSCo和Table-GLS框架,高效解决LVLM在表格推理中的结构内容解耦与结构引导问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格推理 视觉语言模型 多模态学习 结构内容解耦 结构引导 文档理解 信息抽取
📋 核心要点
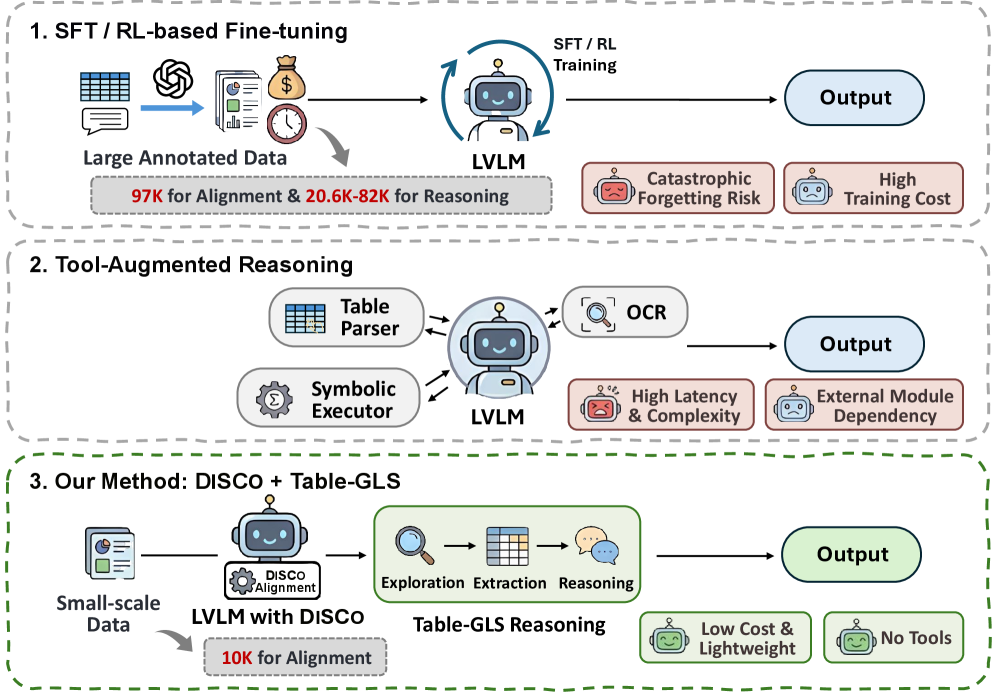
- 现有LVLM在表格推理中面临结构复杂和信息耦合的挑战,依赖监督训练或外部工具,效率和泛化性受限。
- 提出DiSCo框架解耦结构与内容,Table-GLS框架进行全局到局部的结构引导推理,提升模型对表格的理解。
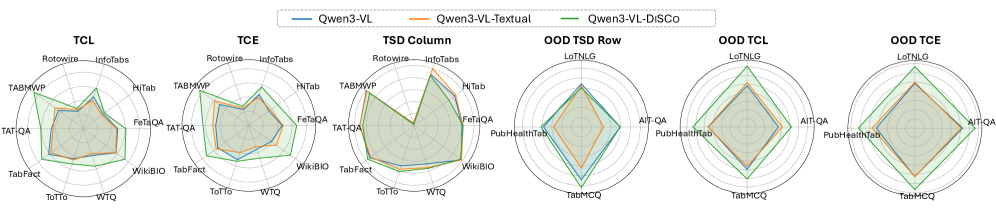
- 实验证明,该框架能有效增强LVLM的表格理解和推理能力,尤其在未见过的表格结构上表现出良好的泛化性。
📝 摘要(中文)
由于复杂的布局和紧密耦合的结构-内容信息,对表格图像进行推理对于大型视觉语言模型(LVLM)来说仍然具有挑战性。现有的解决方案通常依赖于昂贵的监督训练、强化学习或外部工具,限制了效率和可扩展性。本文旨在解决一个关键问题:如何在最少标注且无需外部工具的情况下,使LVLM适应表格推理?为此,我们首先引入了DiSCo,一个解耦的结构-内容对齐框架,它在多模态对齐期间显式地将结构抽象与语义基础分离,从而有效地使LVLM适应表格结构。在此基础上,我们进一步提出了Table-GLS,一个全局到局部的结构引导推理框架,它通过结构化探索和证据基础推理来执行表格推理。在各种基准上的大量实验表明,我们的框架有效地增强了LVLM的表格理解和推理能力,尤其是在推广到未见过的表格结构方面。
🔬 方法详解
问题定义:现有的大型视觉语言模型(LVLM)在处理表格图像推理任务时,面临着表格布局复杂、结构信息与内容信息紧密耦合的问题。传统的解决方案往往需要大量的标注数据进行监督训练,或者依赖于外部工具(如OCR引擎),这导致了训练成本高昂、泛化能力不足以及推理效率低下等问题。因此,如何在最少标注且无需外部工具的情况下,提升LVLM在表格推理任务上的性能,是一个亟待解决的问题。
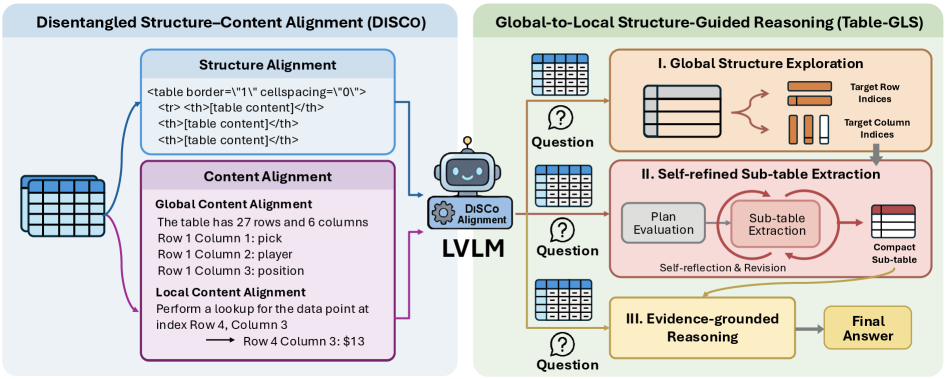
核心思路:本文的核心思路是将表格的结构信息与内容信息进行解耦,并利用解耦后的结构信息来引导LVLM进行推理。具体来说,首先通过DiSCo框架将表格的结构抽象出来,并与内容信息进行分离,从而使LVLM能够更好地理解表格的结构。然后,利用Table-GLS框架,通过全局到局部的结构引导,使LVLM能够更加有效地利用表格的结构信息进行推理。
技术框架:该方法主要包含两个核心框架:DiSCo(Disentangled Structure-Content alignment framework)和 Table-GLS(Global-to-Local Structure-guided reasoning framework)。DiSCo框架负责解耦表格的结构和内容信息,通过显式地分离结构抽象和语义基础,使LVLM能够更好地理解表格结构。Table-GLS框架则利用解耦后的结构信息,通过全局到局部的结构引导,进行表格推理。该框架首先进行全局结构探索,然后基于探索结果进行证据基础推理。
关键创新:该论文的关键创新在于提出了DiSCo框架和Table-GLS框架,实现了表格结构与内容的解耦以及结构引导的推理。与现有方法相比,该方法无需大量的标注数据和外部工具,能够更加高效地提升LVLM在表格推理任务上的性能。此外,该方法还能够更好地泛化到未见过的表格结构,具有更强的鲁棒性。
关键设计:DiSCo框架的关键设计在于如何有效地分离结构抽象和语义基础。具体来说,该框架采用了某种特定的网络结构(具体结构未知)来提取表格的结构信息,并使用某种损失函数(具体损失函数未知)来约束结构信息与内容信息之间的关系,从而实现结构与内容的解耦。Table-GLS框架的关键设计在于如何进行全局到局部的结构引导。具体来说,该框架首先通过某种方式(具体方式未知)对表格的全局结构进行探索,然后基于探索结果,利用某种推理机制(具体机制未知)进行证据基础推理。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所提出的DiSCo和Table-GLS框架能够显著提升LVLM在表格理解和推理方面的性能。具体性能数据未知,但论文强调该框架在推广到未见过的表格结构方面表现出良好的泛化能力。与现有方法相比,该框架在效率和可扩展性方面具有明显优势。
🎯 应用场景
该研究成果可广泛应用于文档理解、信息抽取、智能问答等领域。例如,可以帮助用户快速从表格图像中提取关键信息,进行数据分析和决策支持。未来,该技术有望应用于自动化报表分析、金融数据处理、医疗记录分析等场景,提升工作效率和智能化水平。
📄 摘要(原文)
Reasoning over table images remains challenging for Large Vision-Language Models (LVLMs) due to complex layouts and tightly coupled structure-content information. Existing solutions often depend on expensive supervised training, reinforcement learning, or external tools, limiting efficiency and scalability. This work addresses a key question: how to adapt LVLMs to table reasoning with minimal annotation and no external tools? Specifically, we first introduce DiSCo, a Disentangled Structure-Content alignment framework that explicitly separates structural abstraction from semantic grounding during multimodal alignment, efficiently adapting LVLMs to tables structures. Building on DiSCo, we further present Table-GLS, a Global-to-Local Structure-guided reasoning framework that performs table reasoning via structured exploration and evidence-grounded inference. Extensive experiments across diverse benchmarks demonstrate that our framework efficiently enhances LVLM's table understanding and reasoning capabilities, particularly generalizing to unseen table structures.