Socratic-Geo: Synthetic Data Generation and Geometric Reasoning via Multi-Agent Interaction
作者: Zhengbo Jiao, Shaobo Wang, Zifan Zhang, Wei Wang, Bing Zhao, Hu Wei, Linfeng Zhang
分类: cs.CV, cs.AI
发布日期: 2026-02-03
备注: 18pages
💡 一句话要点
Socratic-Geo:通过多智能体交互生成合成数据并实现几何推理
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 几何推理 合成数据生成 多智能体交互 视觉语言理解
📋 核心要点
- 现有MLLM在几何推理方面表现不足,主要瓶颈在于高质量图像-文本对数据的极度匮乏,人工标注成本高昂且自动化方法效果不佳。
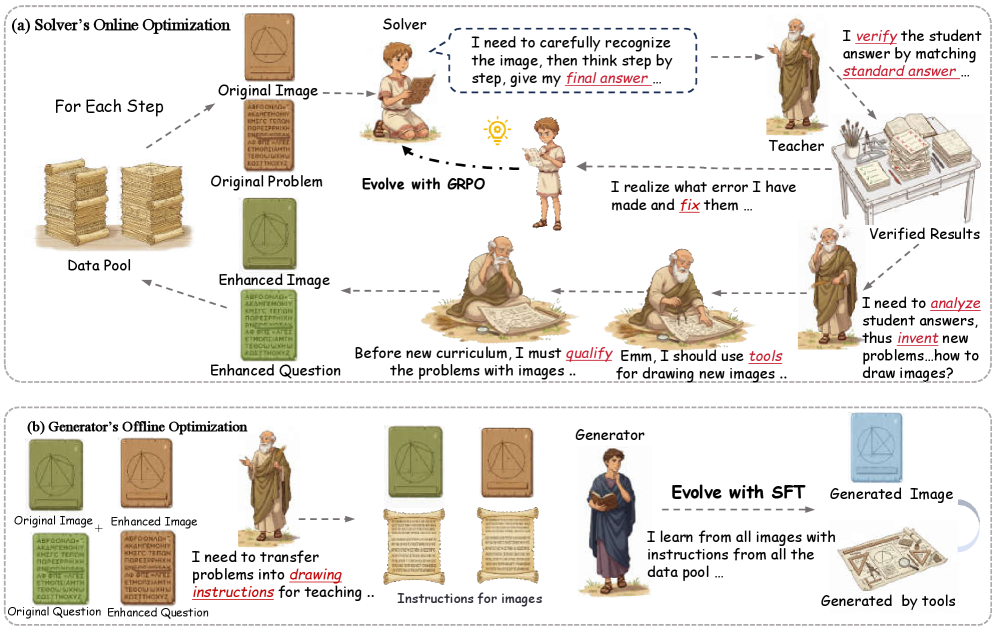
- Socratic-Geo通过多智能体交互,动态耦合数据合成与模型学习,教师智能体生成高质量图像-文本对,求解器智能体优化推理,生成器学习图像生成能力。
- 实验结果表明,Socratic-Geo在数据量仅为基线四分之一的情况下,在多个基准测试中超越了现有方法,并在图像生成方面取得了新的SOTA。
📝 摘要(中文)
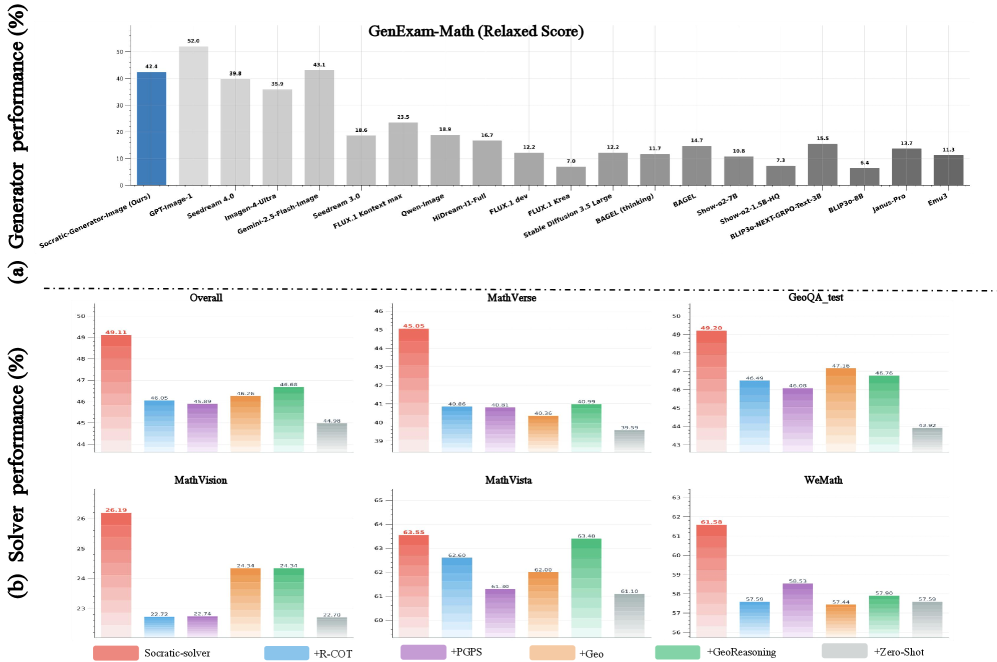
多模态大型语言模型(MLLMs)在视觉-语言理解方面取得了显著进展。然而,即使是最先进的模型在几何推理方面也表现不佳,这揭示了一个关键瓶颈:高质量图像-文本对的极度稀缺。人工标注成本过高,而自动化方法无法确保保真度和训练有效性。现有方法要么被动地适应可用图像,要么采用低效的随机探索和过滤,将生成与学习需求脱钩。我们提出了Socratic-Geo,一个完全自主的框架,通过多智能体交互动态地将数据合成与模型学习相结合。教师智能体生成参数化的Python脚本,并进行反思性反馈(Reflect用于可解性,RePI用于视觉有效性),确保图像-文本对的纯度。求解器智能体通过偏好学习优化推理,失败路径指导教师智能体的有针对性的增强。独立地,生成器在累积的“图像-代码-指令”三元组上学习图像生成能力,将程序化绘图智能提炼为视觉生成。从仅108个种子问题开始,Socratic-Solver使用基线数据量的四分之一在六个基准测试中实现了49.11的性能,超过了强大的基线2.43个点。Socratic-Generator在GenExam上实现了42.4%的性能,为开源模型建立了新的最先进水平,超过了Seedream-4.0 (39.8%),并接近Gemini-2.5-Flash-Image (43.1%)。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型在几何推理方面表现不佳的问题,其根本原因是缺乏高质量的图像-文本对训练数据。现有数据生成方法要么依赖人工标注,成本高昂;要么采用自动化方法,但无法保证生成数据的质量和与模型学习需求的匹配。
核心思路:论文的核心思路是通过多智能体交互,动态地将数据合成与模型学习相结合。具体来说,设计了一个包含教师、求解器和生成器三个智能体的框架,教师负责生成高质量的图像-文本对,求解器负责优化推理能力,生成器负责学习图像生成能力。通过智能体之间的协同工作,实现数据生成和模型学习的相互促进。
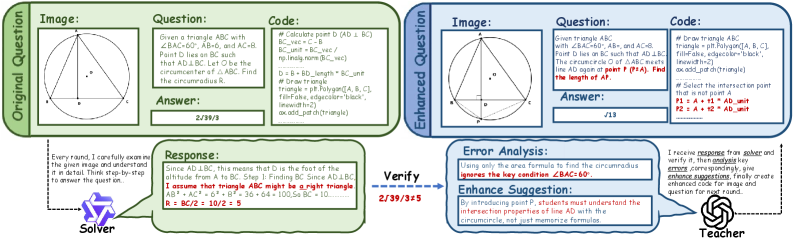
技术框架:Socratic-Geo框架包含三个主要模块:教师智能体、求解器智能体和生成器智能体。教师智能体负责生成参数化的Python脚本,并使用反思性反馈机制(Reflect和RePI)来保证生成图像-文本对的可解性和视觉有效性。求解器智能体通过偏好学习来优化推理能力,并利用失败路径来指导教师智能体进行有针对性的数据增强。生成器智能体则在累积的“图像-代码-指令”三元组上学习图像生成能力。
关键创新:Socratic-Geo的关键创新在于其多智能体交互的框架设计,以及将数据生成与模型学习动态耦合的思路。与现有方法相比,Socratic-Geo能够自主地生成高质量的训练数据,并根据模型学习的反馈进行有针对性的数据增强,从而显著提升模型的几何推理能力。此外,该框架还能够将程序化绘图智能提炼为视觉生成能力,为图像生成任务提供了一种新的思路。
关键设计:教师智能体使用Reflect机制来判断生成的Python脚本是否可解,使用RePI机制来判断生成的图像是否具有视觉有效性。求解器智能体使用偏好学习来优化推理能力,并根据失败路径来指导教师智能体进行数据增强。生成器智能体使用Transformer架构来学习图像生成能力,并使用对抗训练来提高生成图像的质量。
🖼️ 关键图片
📊 实验亮点
Socratic-Geo在六个基准测试中,使用仅为基线四分之一的数据量,取得了49.11的性能,超越了现有基线2.43个点。在GenExam基准测试中,Socratic-Generator取得了42.4%的性能,超越了Seedream-4.0 (39.8%),并接近Gemini-2.5-Flash-Image (43.1%),为开源模型建立了新的SOTA。
🎯 应用场景
Socratic-Geo的研究成果可应用于提升多模态大型语言模型在几何、物理等需要复杂推理能力的场景下的性能。该方法生成的合成数据可以有效降低对人工标注数据的依赖,加速相关领域模型的开发和部署。此外,其多智能体交互和数据生成与模型学习动态耦合的思路,也为其他领域的模型训练提供了新的借鉴。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have significantly advanced vision-language understanding. However, even state-of-the-art models struggle with geometric reasoning, revealing a critical bottleneck: the extreme scarcity of high-quality image-text pairs. Human annotation is prohibitively expensive, while automated methods fail to ensure fidelity and training effectiveness. Existing approaches either passively adapt to available images or employ inefficient random exploration with filtering, decoupling generation from learning needs. We propose Socratic-Geo, a fully autonomous framework that dynamically couples data synthesis with model learning through multi-agent interaction. The Teacher agent generates parameterized Python scripts with reflective feedback (Reflect for solvability, RePI for visual validity), ensuring image-text pair purity. The Solver agent optimizes reasoning through preference learning, with failure paths guiding Teacher's targeted augmentation. Independently, the Generator learns image generation capabilities on accumulated "image-code-instruction" triplets, distilling programmatic drawing intelligence into visual generation. Starting from only 108 seed problems, Socratic-Solver achieves 49.11 on six benchmarks using one-quarter of baseline data, surpassing strong baselines by 2.43 points. Socratic-Generator achieves 42.4% on GenExam, establishing new state-of-the-art for open-source models, surpassing Seedream-4.0 (39.8%) and approaching Gemini-2.5-Flash-Image (43.1%).