From Vicious to Virtuous Cycles: Synergistic Representation Learning for Unsupervised Video Object-Centric Learning
作者: Hyun Seok Seong, WonJun Moon, Jae-Pil Heo
分类: cs.CV, cs.LG
发布日期: 2026-02-03
备注: ICLR 2026; Code is available at https://github.com/hynnsk/SRL
🔗 代码/项目: GITHUB
💡 一句话要点
提出协同表示学习(SRL),解决无监督视频对象中心学习中编码器-解码器表征鸿沟问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 无监督学习 对象中心学习 视频理解 表征学习 协同学习
📋 核心要点
- 现有基于重构的无监督对象中心学习方法,面临编码器注意力图和解码器重构图之间表征不一致的挑战。
- 论文提出协同表示学习(SRL),通过编码器和解码器的相互优化,弥合表征鸿沟,形成良性循环。
- SRL在视频对象中心学习基准上取得了显著的性能提升,验证了其有效性。
📝 摘要(中文)
无监督对象中心学习模型,特别是基于槽(slot)的架构,在分解复杂场景方面展现出巨大潜力。然而,它们对基于重构的训练的依赖,在编码器清晰、高频的注意力图和解码器空间一致但模糊的重构图之间造成了根本冲突。我们发现这种差异产生了一个恶性循环:来自编码器的噪声特征图迫使解码器对可能性进行平均,并产生更模糊的输出,而从模糊重构图计算出的梯度缺乏监督编码器特征所需的高频细节。为了打破这个循环,我们引入了协同表示学习(SRL),它建立了一个良性循环,编码器和解码器相互改进。SRL利用编码器的清晰度来去模糊解码器输出中的语义边界,同时利用解码器的空间一致性来去噪编码器的特征。这种相互改进过程通过一个带有槽正则化目标的预热阶段来稳定,该阶段最初为每个槽分配不同的实体。通过弥合编码器和解码器之间的表征差距,SRL在视频对象中心学习基准上取得了最先进的结果。代码可在https://github.com/hynnsk/SRL 获取。
🔬 方法详解
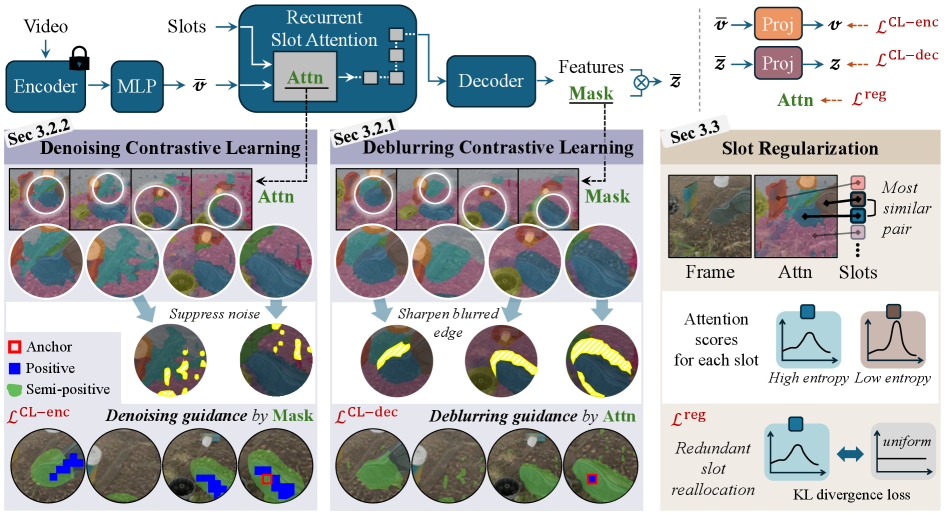
问题定义:论文旨在解决无监督视频对象中心学习中,基于槽的架构在训练时编码器和解码器之间存在的表征鸿沟问题。具体来说,编码器倾向于生成高频、清晰但可能包含噪声的注意力图,而解码器为了保证空间一致性,输出的重构图往往是模糊的。这种差异导致训练过程陷入恶性循环,编码器的噪声影响解码器的重构质量,反过来解码器模糊的梯度又难以有效监督编码器的特征学习。
核心思路:论文的核心思路是建立一个编码器和解码器相互促进的“良性循环”。通过利用编码器的清晰度来提升解码器输出的语义边界清晰度,同时利用解码器的空间一致性来降低编码器特征的噪声,从而实现二者的协同优化。这种相互依赖和提升的设计旨在弥合编码器和解码器之间的表征差距,使得模型能够更有效地学习到对象中心的表示。
技术框架:SRL的整体框架仍然基于常见的槽架构,包括一个编码器和一个解码器。关键在于训练过程的改进,主要包含两个阶段:预热阶段和协同学习阶段。预热阶段使用槽正则化目标,确保每个槽初步分配到不同的对象实体。协同学习阶段则通过特定的损失函数和优化策略,实现编码器和解码器的相互优化。
关键创新:SRL最关键的创新在于提出了协同表示学习的思想,打破了以往基于重构的训练方法中编码器和解码器之间的单向依赖关系,建立了双向的相互促进机制。这种机制能够有效地解决编码器和解码器表征不一致的问题,从而提升模型的整体性能。
关键设计:SRL的关键设计包括:1) 预热阶段的槽正则化损失,用于初始化槽的表示;2) 利用编码器注意力图对解码器输出进行去模糊处理的具体方法(具体实现未知,论文未详细描述);3) 利用解码器重构图的空间一致性对编码器特征进行去噪的具体方法(具体实现未知,论文未详细描述);4) 协同学习阶段的损失函数设计,需要平衡重构损失、槽正则化损失以及编码器和解码器相互优化相关的损失(具体形式未知)。
🖼️ 关键图片


📊 实验亮点
论文在视频对象中心学习基准上取得了state-of-the-art的结果,证明了SRL的有效性。具体的性能数据和对比基线需要在论文中查找,但摘要中明确指出SRL能够显著提升模型性能,弥合编码器和解码器之间的表征差距。
🎯 应用场景
该研究成果可应用于视频理解、目标跟踪、机器人导航等领域。通过无监督的方式学习视频中的对象中心表示,有助于提升模型对复杂场景的理解能力,并为后续的任务提供更有效的特征表示。未来,该方法有望在自动驾驶、智能监控等领域发挥重要作用。
📄 摘要(原文)
Unsupervised object-centric learning models, particularly slot-based architectures, have shown great promise in decomposing complex scenes. However, their reliance on reconstruction-based training creates a fundamental conflict between the sharp, high-frequency attention maps of the encoder and the spatially consistent but blurry reconstruction maps of the decoder. We identify that this discrepancy gives rise to a vicious cycle: the noisy feature map from the encoder forces the decoder to average over possibilities and produce even blurrier outputs, while the gradient computed from blurry reconstruction maps lacks high-frequency details necessary to supervise encoder features. To break this cycle, we introduce Synergistic Representation Learning (SRL) that establishes a virtuous cycle where the encoder and decoder mutually refine one another. SRL leverages the encoder's sharpness to deblur the semantic boundary within the decoder output, while exploiting the decoder's spatial consistency to denoise the encoder's features. This mutual refinement process is stabilized by a warm-up phase with a slot regularization objective that initially allocates distinct entities per slot. By bridging the representational gap between the encoder and decoder, SRL achieves state-of-the-art results on video object-centric learning benchmarks. Codes are available at https://github.com/hynnsk/SRL.