Unifying Watermarking via Dimension-Aware Mapping
作者: Jiale Meng, Runyi Hu, Jie Zhang, Zheming Lu, Ivor Tsang, Tianwei Zhang
分类: cs.CV
发布日期: 2026-02-03
备注: 29 pages, 25 figures
💡 一句话要点
提出维度感知映射(DiM)框架,统一现有深度水印方法并实现多维度水印功能。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 深度水印 维度感知映射 视频水印 时空篡改定位 版权保护
📋 核心要点
- 现有深度水印方法功能行为差异大,缺乏统一的理论框架。
- DiM框架将水印问题建模为维度感知的映射,通过配置嵌入和提取维度实现不同的水印功能。
- 实验表明,DiM框架仅通过改变维度配置即可实现时空篡改定位、局部嵌入控制等多种水印能力。
📝 摘要(中文)
深度水印方法通常共享相似的编码器-解码器架构,但在功能行为上差异很大。我们提出了DiM,一个新的多维水印框架,它将水印问题形式化为维度感知的映射问题,从而在功能层面上统一了现有的水印方法。在DiM下,水印信息被建模为不同维度的有效载荷,包括一维二进制消息、二维空间掩码和三维时空结构。我们发现嵌入和提取的维度配置在很大程度上决定了最终的水印行为。同维度映射保留了有效载荷结构并支持细粒度控制,而跨维度映射则实现了空间或时空定位。我们在视频领域实例化了DiM,其中时空表示能够实现更广泛的维度映射。实验表明,仅改变嵌入和提取维度,而无需架构更改,就能带来不同的水印功能,包括时空篡改定位、局部嵌入控制以及在帧中断下恢复时间顺序。
🔬 方法详解
问题定义:现有深度水印方法虽然架构相似,但功能行为差异显著,缺乏一个统一的框架来理解和设计不同的水印功能。现有的方法通常针对特定任务设计,缺乏通用性和灵活性,难以适应不同的应用场景。
核心思路:论文的核心思路是将水印问题视为一个维度感知的映射问题。通过控制水印信息(payload)的维度以及嵌入和提取过程的维度,可以实现不同的水印功能。例如,同维度映射可以保持payload的结构,实现精细控制;跨维度映射则可以实现空间或时空定位。这种方法将不同的水印方法统一到一个框架下,并提供了设计新水印功能的指导。
技术框架:DiM框架的核心在于维度感知的映射。整体流程包括:1) 将水印信息编码为不同维度的payload(例如,1D二进制消息,2D空间掩码,3D时空结构);2) 将payload嵌入到宿主数据中(例如,视频帧);3) 从嵌入水印的宿主数据中提取payload;4) 解码payload以恢复水印信息。关键在于嵌入和提取过程中的维度配置,不同的维度组合可以实现不同的水印行为。
关键创新:DiM框架的关键创新在于将水印问题形式化为维度感知的映射问题,从而提供了一个统一的视角来理解和设计不同的水印功能。与现有方法相比,DiM框架更加通用和灵活,可以适应不同的应用场景。通过控制维度配置,可以实现多种水印功能,而无需修改网络架构。
关键设计:论文在视频领域实例化了DiM框架,利用时空表示实现了更广泛的维度映射。具体的网络结构和损失函数没有在摘要中详细说明,但关键在于如何设计嵌入和提取模块,以实现不同维度之间的映射。例如,可以使用卷积神经网络来学习从低维水印信息到高维图像特征的映射,或者使用循环神经网络来处理时序信息。
🖼️ 关键图片


📊 实验亮点
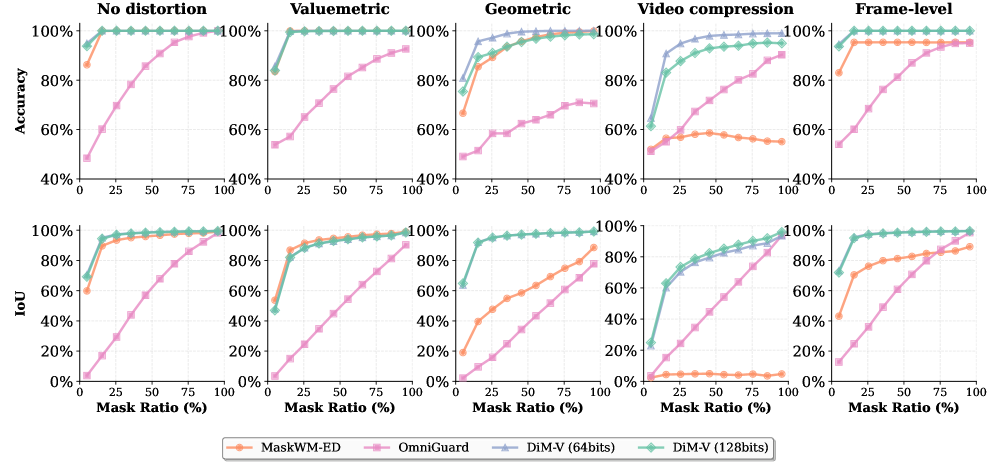
实验结果表明,DiM框架仅通过改变嵌入和提取维度,无需修改网络架构,即可实现多种水印功能,包括时空篡改定位、局部嵌入控制以及在帧中断下恢复时间顺序。这些结果验证了DiM框架的有效性和灵活性,并展示了其在不同应用场景中的潜力。
🎯 应用场景
该研究成果可广泛应用于数字版权保护、内容认证、篡改检测、信息隐藏等领域。例如,在视频监控中,可以利用时空水印进行篡改定位;在社交媒体中,可以嵌入版权信息以防止盗用;在军事通信中,可以隐藏敏感信息。该研究为水印技术的发展提供了新的思路,具有重要的实际价值和未来影响。
📄 摘要(原文)
Deep watermarking methods often share similar encoder-decoder architectures, yet differ substantially in their functional behaviors. We propose DiM, a new multi-dimensional watermarking framework that formulates watermarking as a dimension-aware mapping problem, thereby unifying existing watermarking methods at the functional level. Under DiM, watermark information is modeled as payloads of different dimensionalities, including one-dimensional binary messages, two-dimensional spatial masks, and three-dimensional spatiotemporal structures. We find that the dimensional configuration of embedding and extraction largely determines the resulting watermarking behavior. Same-dimensional mappings preserve payload structure and support fine-grained control, while cross-dimensional mappings enable spatial or spatiotemporal localization. We instantiate DiM in the video domain, where spatiotemporal representations enable a broader set of dimension mappings. Experiments demonstrate that varying only the embedding and extraction dimensions, without architectural changes, leads to different watermarking capabilities, including spatiotemporal tamper localization, local embedding control, and recovery of temporal order under frame disruptions.