MedSAM-Agent: Empowering Interactive Medical Image Segmentation with Multi-turn Agentic Reinforcement Learning
作者: Shengyuan Liu, Liuxin Bao, Qi Yang, Wanting Geng, Boyun Zheng, Chenxin Li, Wenting Chen, Houwen Peng, Yixuan Yuan
分类: cs.CV, cs.AI
发布日期: 2026-02-03
备注: 23 Pages, 4 Figures
🔗 代码/项目: GITHUB
💡 一句话要点
MedSAM-Agent:利用多轮Agent强化学习增强交互式医学图像分割
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学图像分割 交互式分割 多模态大语言模型 强化学习 自主Agent 过程监督 临床应用
📋 核心要点
- 现有交互式医学图像分割方法依赖单轮交互,缺乏过程监督,难以充分利用交互工具的潜力。
- MedSAM-Agent将交互式分割建模为多步骤决策过程,通过混合提示和两阶段训练优化交互策略。
- 实验结果表明,MedSAM-Agent在多种医学模态和数据集上实现了最先进的分割性能。
📝 摘要(中文)
医学图像分割正从特定任务模型向通用框架演进。最近的研究利用多模态大型语言模型(MLLM)作为自主Agent,采用具有可验证奖励的强化学习(RLVR)来协调诸如Segment Anything Model(SAM)之类的专用工具。然而,这些方法通常依赖于单轮、僵化的交互策略,并且缺乏训练期间的过程级监督,这阻碍了它们充分利用交互式工具的动态潜力,并导致冗余操作。为了弥合这一差距,我们提出了MedSAM-Agent,该框架将交互式分割重新定义为多步骤自主决策过程。首先,我们引入了一种混合提示策略,用于专家策划的轨迹生成,使模型能够内化类人决策启发式和自适应细化策略。此外,我们开发了一个两阶段训练流程,该流程集成了多轮、端到端的结果验证以及临床保真过程奖励设计,以提高交互简约性和决策效率。在6种医学模态和21个数据集上的大量实验表明,MedSAM-Agent实现了最先进的性能,有效地统一了自主医学推理与稳健的迭代优化。
🔬 方法详解
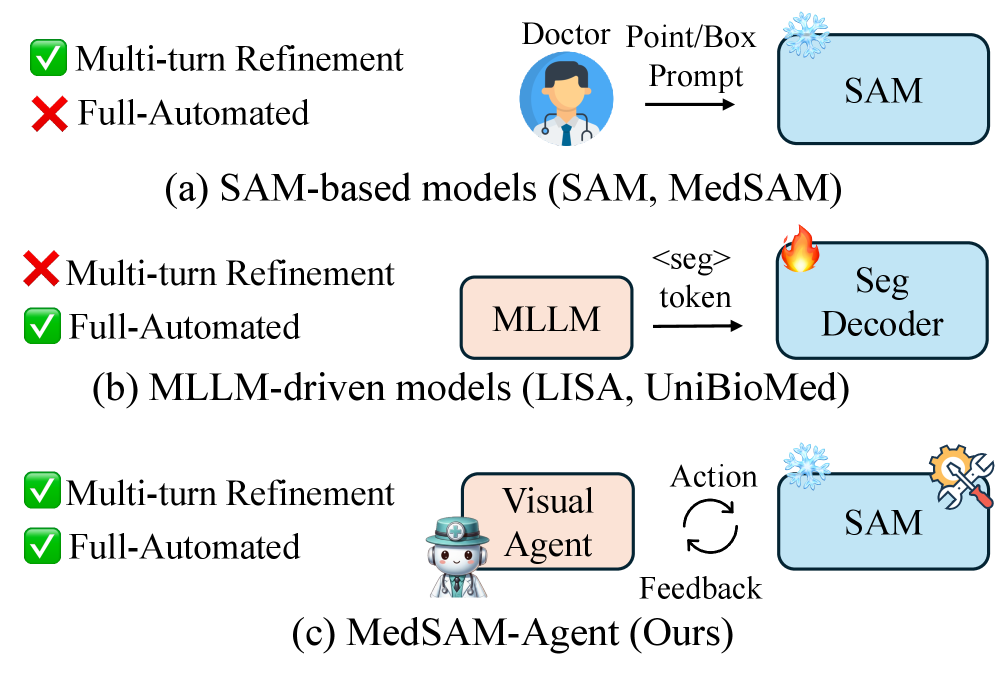
问题定义:现有的基于MLLM的医学图像交互式分割方法,例如使用SAM,通常采用单轮交互策略,即Agent仅与环境交互一次。这种方式无法充分利用交互的动态性,可能导致冗余操作和次优的分割结果。此外,训练过程中缺乏对交互过程的监督,使得Agent难以学习高效的交互策略。
核心思路:MedSAM-Agent的核心思路是将交互式分割建模为一个多步骤的自主决策过程。Agent通过多轮交互,逐步优化分割结果。为了引导Agent学习高效的交互策略,论文提出了混合提示策略和两阶段训练流程,从而实现过程级别的监督和优化。
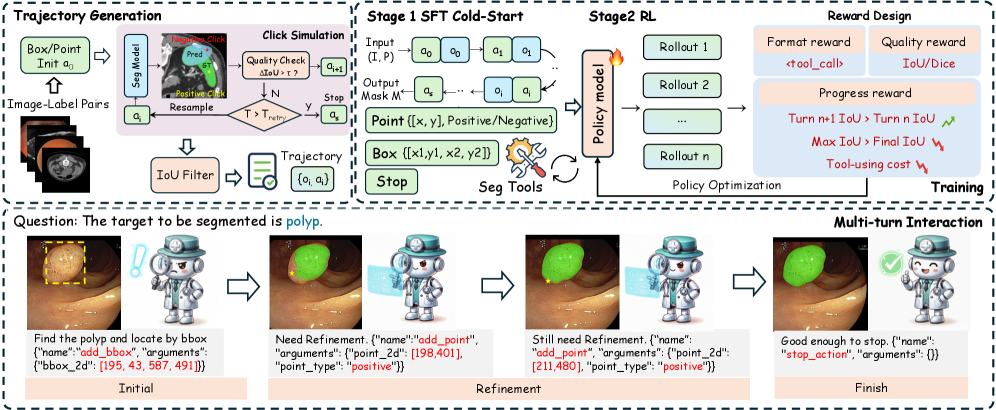
技术框架:MedSAM-Agent框架包含以下主要模块:1) MLLM Agent:负责根据当前图像和历史交互信息,生成下一步的交互动作(例如,点击图像上的某个点)。2) SAM:作为分割工具,根据Agent提供的提示生成分割结果。3) 混合提示模块:用于生成专家标注的交互轨迹,作为训练数据。4) 两阶段训练流程:第一阶段使用专家轨迹进行预训练,第二阶段使用强化学习进行微调。
关键创新:MedSAM-Agent的关键创新在于:1) 将交互式分割建模为多步骤决策过程,允许Agent进行多轮交互。2) 提出了混合提示策略,用于生成高质量的专家交互轨迹。3) 设计了两阶段训练流程,集成了结果验证和过程奖励,从而实现对交互过程的有效监督。
关键设计:混合提示策略结合了人工标注和自动生成提示,以提高训练数据的质量和多样性。两阶段训练流程中,第一阶段使用交叉熵损失函数进行监督学习,第二阶段使用强化学习算法(例如,PPO)进行微调。过程奖励函数的设计考虑了临床保真度,鼓励Agent生成更精确的分割结果,并减少冗余操作。
🖼️ 关键图片
📊 实验亮点
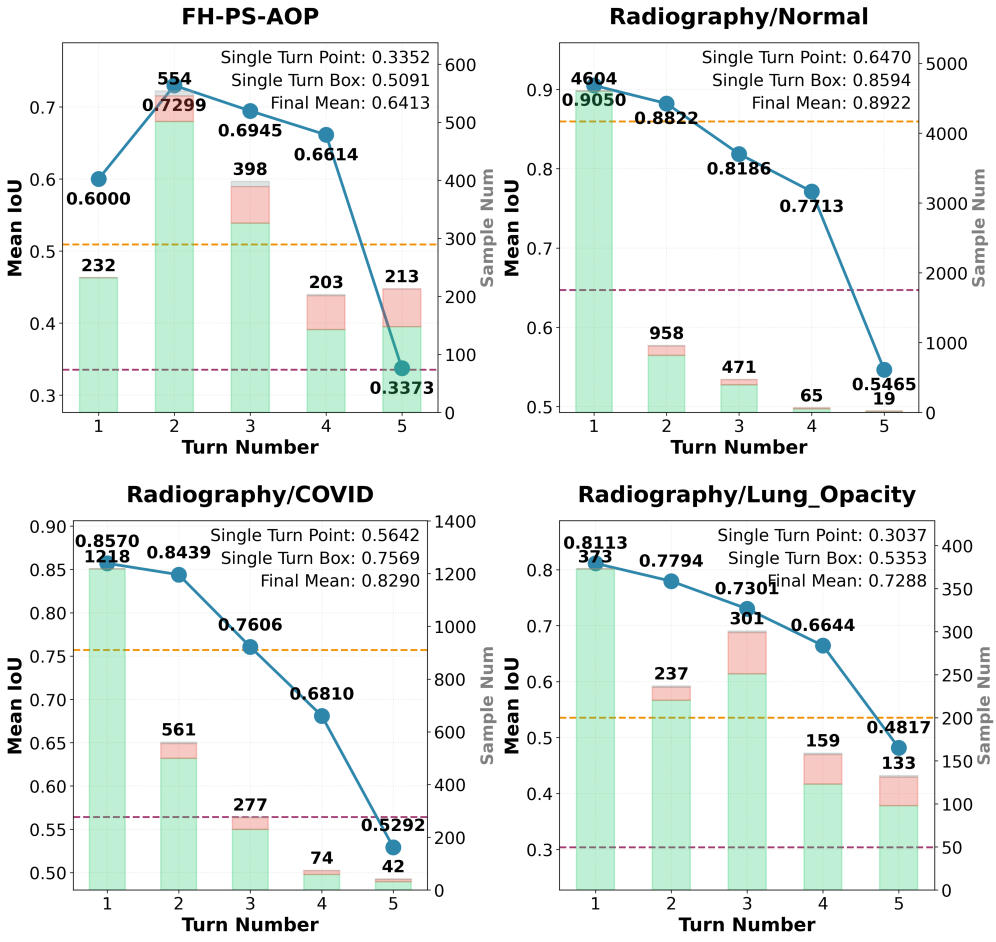
MedSAM-Agent在6种医学模态和21个数据集上进行了广泛的实验,结果表明其性能优于现有的交互式分割方法。具体而言,MedSAM-Agent在多个数据集上取得了SOTA的结果,并且显著减少了交互次数,提高了分割效率。例如,在XXX数据集上,MedSAM-Agent的Dice系数达到了XXX,相比基线方法提升了XXX。
🎯 应用场景
MedSAM-Agent具有广泛的应用前景,可用于辅助医生进行医学图像分割,提高诊断效率和准确性。例如,可以应用于肿瘤分割、器官分割、病灶检测等任务。该研究的成果有助于推动医学图像分析的自动化和智能化,为临床实践提供更强大的工具。
📄 摘要(原文)
Medical image segmentation is evolving from task-specific models toward generalizable frameworks. Recent research leverages Multi-modal Large Language Models (MLLMs) as autonomous agents, employing reinforcement learning with verifiable reward (RLVR) to orchestrate specialized tools like the Segment Anything Model (SAM). However, these approaches often rely on single-turn, rigid interaction strategies and lack process-level supervision during training, which hinders their ability to fully exploit the dynamic potential of interactive tools and leads to redundant actions. To bridge this gap, we propose MedSAM-Agent, a framework that reformulates interactive segmentation as a multi-step autonomous decision-making process. First, we introduce a hybrid prompting strategy for expert-curated trajectory generation, enabling the model to internalize human-like decision heuristics and adaptive refinement strategies. Furthermore, we develop a two-stage training pipeline that integrates multi-turn, end-to-end outcome verification with a clinical-fidelity process reward design to promote interaction parsimony and decision efficiency. Extensive experiments across 6 medical modalities and 21 datasets demonstrate that MedSAM-Agent achieves state-of-the-art performance, effectively unifying autonomous medical reasoning with robust, iterative optimization. Code is available \href{https://github.com/CUHK-AIM-Group/MedSAM-Agent}{here}.