Hand3R: Online 4D Hand-Scene Reconstruction in the Wild
作者: Wendi Hu, Haonan Zhou, Wenhao Hu, Gaoang Wang
分类: cs.CV, cs.AI
发布日期: 2026-02-03
💡 一句话要点
Hand3R:提出首个单目视频在线4D手部-场景联合重建框架
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 手部重建 场景重建 4D重建 单目视频 具身智能
📋 核心要点
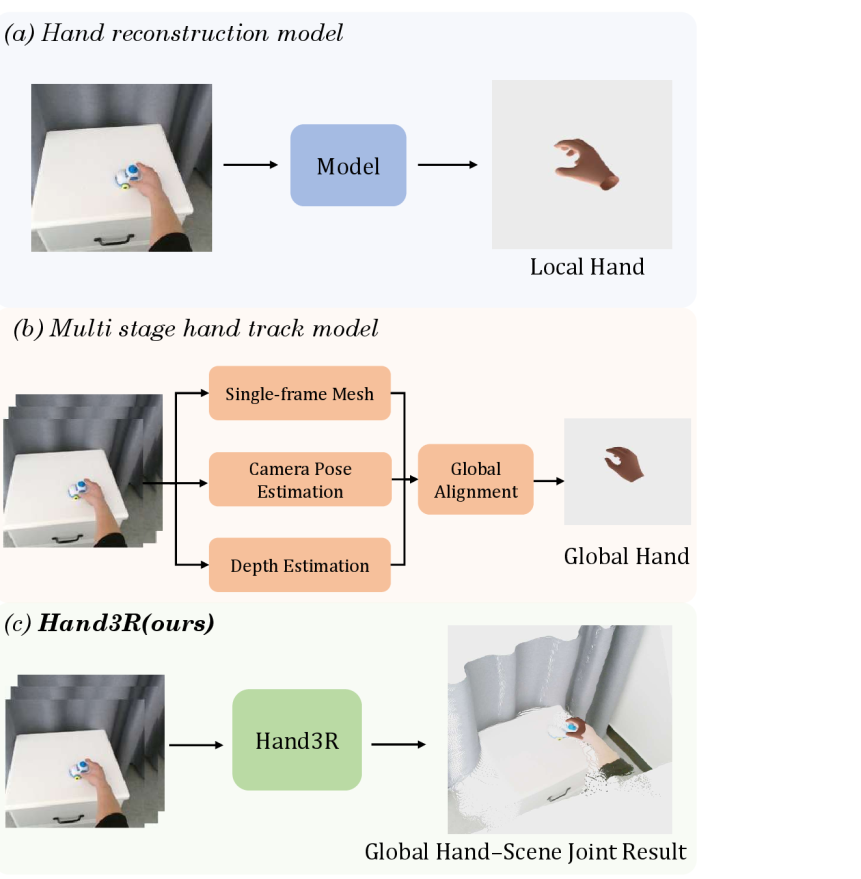
- 现有方法在孤立局部坐标中重建手部,忽略了手部与周围3D环境的交互关系,限制了具身智能的应用。
- Hand3R通过视觉提示机制,融合预训练手部专家和4D场景基础模型,实现手部和场景的联合重建。
- Hand3R无需离线优化,单次前向传递即可重建手部网格和场景几何,并在手部重建和全局定位上表现出色。
📝 摘要(中文)
本文提出Hand3R,首个从单目视频中进行联合4D手部-场景重建的在线框架。对于具身智能而言,联合重建动态手部和稠密场景上下文对于理解物理交互至关重要。现有方法大多在局部坐标系中恢复孤立的手部,忽略了周围的3D环境。Hand3R通过场景感知的视觉提示机制,将预训练的手部专家与4D场景基础模型协同工作。通过将高保真手部先验注入到持久的场景记忆中,该方法能够在一次前向传递中同时重建精确的手部网格和度量尺度的稠密场景几何。实验表明,Hand3R避免了对离线优化的依赖,并在局部手部重建和全局定位方面都提供了有竞争力的性能。
🔬 方法详解
问题定义:现有方法主要关注孤立手部的重建,忽略了手部与周围环境的交互,无法提供全局场景信息。此外,现有方法通常依赖离线优化,计算成本高,难以满足在线应用的需求。因此,需要一种能够在线、准确地重建手部和周围场景的联合框架。
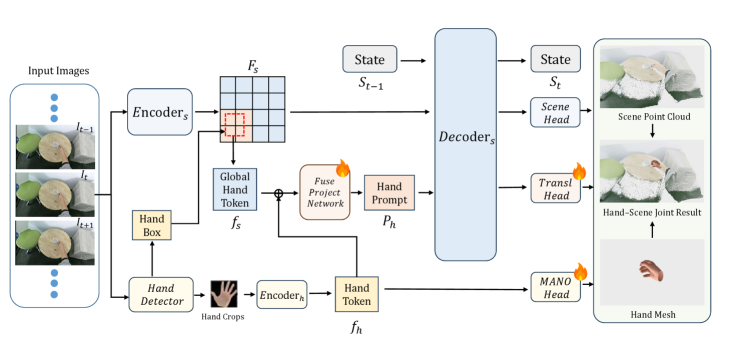
核心思路:Hand3R的核心思路是将预训练的手部专家与4D场景基础模型相结合,利用手部先验知识来引导场景重建,同时利用场景信息来约束手部姿态估计。通过场景感知的视觉提示机制,将手部信息注入到场景记忆中,实现手部和场景的协同重建。
技术框架:Hand3R的整体框架包含以下几个主要模块:1) 预训练的手部专家,用于提取手部的特征和姿态信息;2) 4D场景基础模型,用于构建和更新场景的几何信息;3) 场景感知的视觉提示模块,用于将手部信息注入到场景记忆中;4) 重建模块,用于生成手部网格和场景几何。整个流程以单目视频作为输入,通过一次前向传递,同时输出手部和场景的重建结果。
关键创新:Hand3R的关键创新在于提出了场景感知的视觉提示机制,该机制能够有效地将手部先验知识融入到场景重建过程中,从而提高重建的准确性和鲁棒性。此外,Hand3R实现了在线的手部-场景联合重建,避免了对离线优化的依赖,提高了计算效率。
关键设计:Hand3R使用了预训练的 MANO 模型作为手部专家,并采用了一种基于 Transformer 的视觉提示网络来实现场景感知。损失函数包括手部姿态损失、场景重建损失和手部-场景一致性损失。具体参数设置和网络结构细节在论文中有详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
Hand3R在单目视频手部-场景联合重建任务上取得了有竞争力的性能。该方法无需离线优化,能够在线重建手部网格和场景几何。具体性能数据和对比基线在论文中有详细描述(未知),但摘要表明其在局部手部重建和全局定位方面都表现出色。
🎯 应用场景
Hand3R在具身智能、人机交互、虚拟现实和增强现实等领域具有广泛的应用前景。例如,可以用于机器人操作任务,使机器人能够更好地理解和操作周围环境;可以用于虚拟现实游戏,提供更逼真的手部交互体验;还可以用于增强现实应用,将虚拟手部与真实场景进行融合。
📄 摘要(原文)
For Embodied AI, jointly reconstructing dynamic hands and the dense scene context is crucial for understanding physical interaction. However, most existing methods recover isolated hands in local coordinates, overlooking the surrounding 3D environment. To address this, we present Hand3R, the first online framework for joint 4D hand-scene reconstruction from monocular video. Hand3R synergizes a pre-trained hand expert with a 4D scene foundation model via a scene-aware visual prompting mechanism. By injecting high-fidelity hand priors into a persistent scene memory, our approach enables simultaneous reconstruction of accurate hand meshes and dense metric-scale scene geometry in a single forward pass. Experiments demonstrate that Hand3R bypasses the reliance on offline optimization and delivers competitive performance in both local hand reconstruction and global positioning.