FinMTM: A Multi-Turn Multimodal Benchmark for Financial Reasoning and Agent Evaluation
作者: Chenxi Zhang, Ziliang Gan, Liyun Zhu, Youwei Pang, Qing Zhang, Rongjunchen Zhang
分类: cs.CV, cs.CE
发布日期: 2026-02-03
💡 一句话要点
提出FinMTM:一个用于金融推理和Agent评估的多轮多模态基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 金融推理 多模态学习 视觉-语言模型 基准测试 Agent评估
📋 核心要点
- 现有金融基准测试集缺乏多样性,主要集中于单轮问答和有限的问题形式,难以全面评估模型在真实金融场景中的能力。
- FinMTM通过构建包含多种金融图表、多轮对话和Agent任务的多模态数据集,旨在更全面地评估视觉-语言模型在金融领域的推理能力。
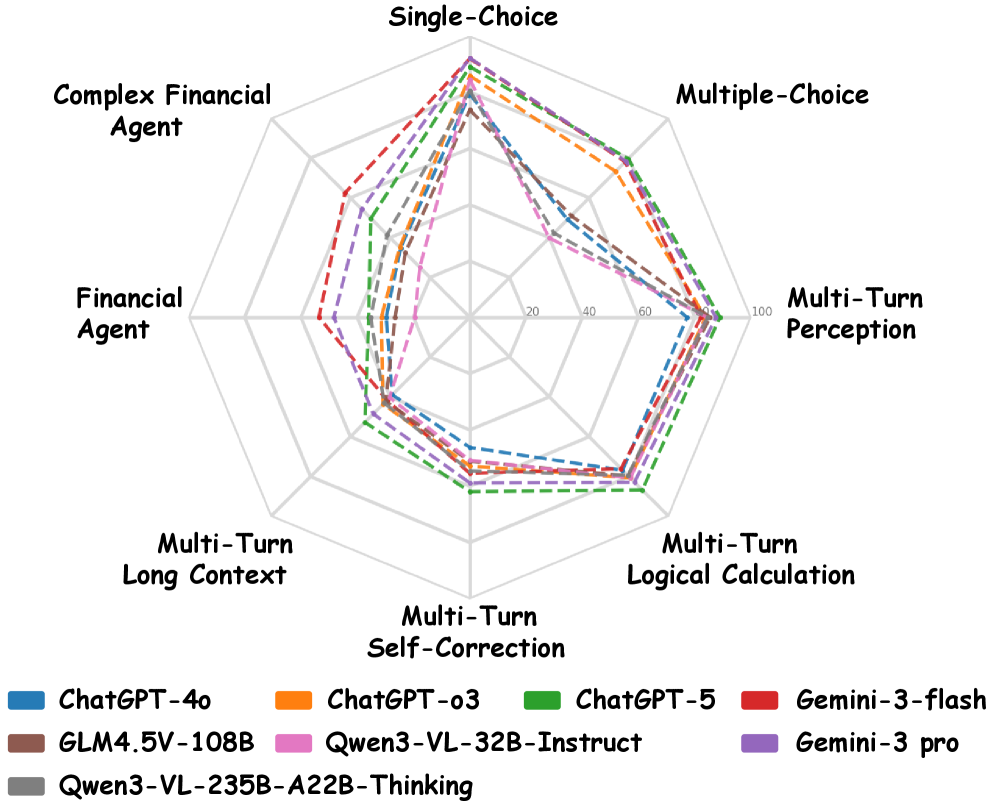
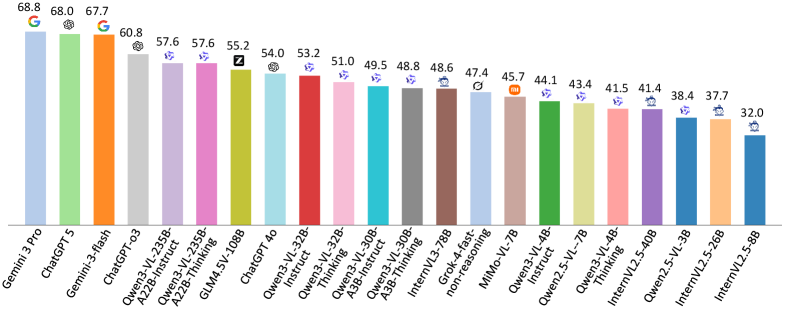
- 实验结果表明,现有视觉-语言模型在细粒度视觉感知、长上下文推理和复杂Agent工作流程方面存在局限性,为未来研究提供了方向。
📝 摘要(中文)
由于专业的图表格式和知识密集型的推理需求,金融领域对视觉-语言模型(VLMs)提出了巨大的挑战。然而,现有的金融基准在很大程度上是单轮的,并且依赖于狭窄的问题形式,限制了在实际应用场景中的全面评估。为了解决这个差距,我们提出了FinMTM,一个多轮多模态基准,它扩展了数据和任务维度的多样性。在数据方面,我们整理并标注了11,133个双语(中文和英文)金融QA对,这些QA对基于金融视觉信息,包括K线图、统计图和报告图。在任务方面,FinMTM涵盖了单项和多项选择题、多轮开放式对话和基于Agent的任务。我们进一步设计了特定于任务的评估协议,包括用于多项选择题的集合重叠评分规则,用于多轮对话的轮级别和会话级别分数的加权组合,以及将规划质量与Agent任务的最终结果相结合的综合指标。对22个VLMs的广泛实验评估揭示了它们在细粒度视觉感知、长上下文推理和复杂Agent工作流程方面的局限性。
🔬 方法详解
问题定义:现有金融领域的视觉-语言模型评估基准主要集中于单轮问答,缺乏对多轮交互和复杂推理能力的考察。此外,现有基准的数据集在视觉信息类型和问题形式上存在局限性,难以模拟真实的金融应用场景。因此,需要一个更全面、更具挑战性的基准来评估模型在金融领域的表现。
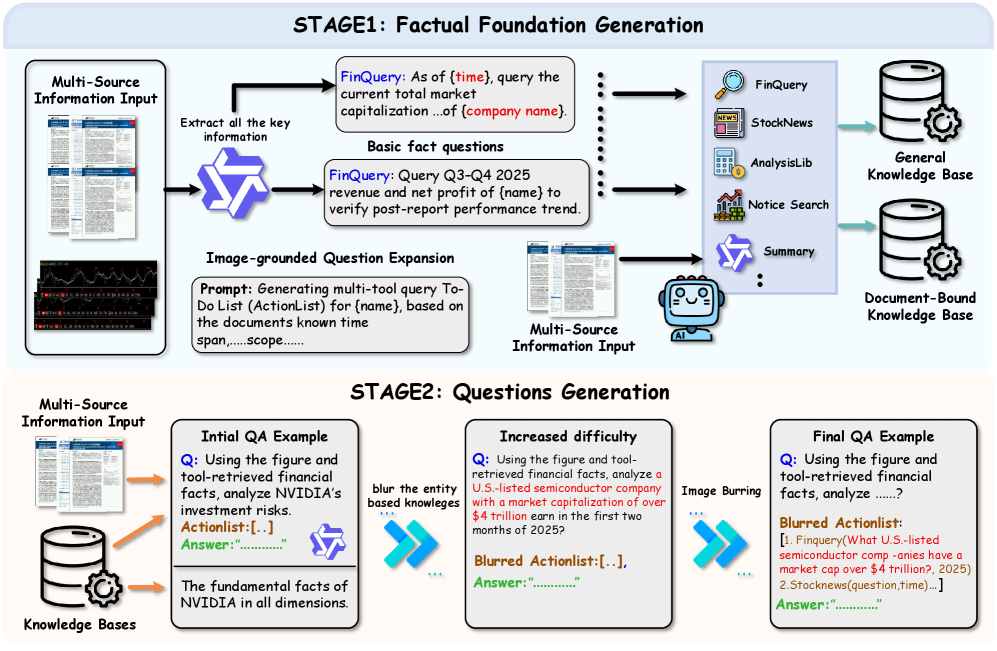
核心思路:FinMTM的核心思路是通过构建一个多轮、多模态的金融数据集,并设计相应的评估协议,来更全面地评估视觉-语言模型在金融领域的推理和决策能力。该数据集包含多种金融图表(如K线图、统计图和报告图),并涵盖了单项选择、多项选择、多轮对话和Agent任务等多种任务类型。
技术框架:FinMTM的整体框架包括数据收集与标注、任务设计和评估协议三个主要部分。首先,从金融报告、新闻等来源收集金融图表和相关文本信息,并进行人工标注,构建双语(中英文)QA对。然后,设计多种任务类型,包括单项选择、多项选择、多轮对话和Agent任务,以评估模型在不同方面的能力。最后,针对每种任务类型,设计相应的评估协议,例如,对于多项选择题,采用集合重叠评分规则;对于多轮对话,采用轮级别和会话级别分数的加权组合。
关键创新:FinMTM的关键创新在于其多轮、多模态的数据集和全面的任务设计。与现有基准相比,FinMTM的数据集包含更多种类的金融图表,并涵盖了更广泛的任务类型,能够更全面地评估视觉-语言模型在金融领域的推理和决策能力。此外,FinMTM还设计了针对不同任务类型的评估协议,使得评估结果更加准确和可靠。
关键设计:在数据标注方面,采用了双语标注,以支持中文和英文两种语言的评估。在多轮对话任务中,设计了 turn-level 和 session-level 的奖励机制,鼓励模型进行更深入的对话和推理。在Agent任务中,设计了一个复合指标,将规划质量与最终结果相结合,以评估Agent的整体表现。
🖼️ 关键图片
📊 实验亮点
对22个视觉-语言模型在FinMTM上进行了广泛的实验评估,结果表明这些模型在细粒度视觉感知、长上下文推理和复杂Agent工作流程方面存在显著的局限性。例如,在多轮对话任务中,模型的表现远低于人类水平,表明模型难以进行深入的金融推理。这些实验结果为未来研究提供了重要的参考。
🎯 应用场景
FinMTM的研究成果可应用于开发更智能的金融助手,帮助用户理解金融数据、进行投资决策和风险管理。该基准测试集能够推动视觉-语言模型在金融领域的应用,例如自动解读财务报表、预测股票走势、提供个性化投资建议等,具有重要的实际价值和广阔的应用前景。
📄 摘要(原文)
The financial domain poses substantial challenges for vision-language models (VLMs) due to specialized chart formats and knowledge-intensive reasoning requirements. However, existing financial benchmarks are largely single-turn and rely on a narrow set of question formats, limiting comprehensive evaluation in realistic application scenarios. To address this gap, we propose FinMTM, a multi-turn multimodal benchmark that expands diversity along both data and task dimensions. On the data side, we curate and annotate 11{,}133 bilingual (Chinese and English) financial QA pairs grounded in financial visuals, including candlestick charts, statistical plots, and report figures. On the task side, FinMTM covers single- and multiple-choice questions, multi-turn open-ended dialogues, and agent-based tasks. We further design task-specific evaluation protocols, including a set-overlap scoring rule for multiple-choice questions, a weighted combination of turn-level and session-level scores for multi-turn dialogues, and a composite metric that integrates planning quality with final outcomes for agent tasks. Extensive experimental evaluation of 22 VLMs reveal their limitations in fine-grained visual perception, long-context reasoning, and complex agent workflows.