Beyond Cropping and Rotation: Automated Evolution of Powerful Task-Specific Augmentations with Generative Models
作者: Judah Goldfeder, Shreyes Kaliyur, Vaibhav Sourirajan, Patrick Minwan Puma, Philippe Martin Wyder, Yuhang Hu, Jiong Lin, Hod Lipson
分类: cs.CV, cs.AI
发布日期: 2026-02-03
💡 一句话要点
EvoAug:利用生成模型自动进化任务特定的强大数据增强策略
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 数据增强 生成模型 进化算法 自动化机器学习 少样本学习
📋 核心要点
- 现有数据增强方法(如AutoAugment)难以有效利用生成模型合成的多样性和真实感数据,存在性能下降风险。
- EvoAug利用生成模型和进化算法,自动学习任务特定的增强策略,通过分层组合增强的随机增强树实现自适应转换。
- 实验表明,EvoAug在细粒度分类和少样本学习任务中表现出色,且能发现与领域知识对齐的增强策略。
📝 摘要(中文)
数据增强一直是减少视觉模型过拟合的关键技术。诸如AutoAugment之类的方法已经实现了任务特定增强设计的自动化。条件扩散模型和少样本NeRF等生成模型的最新进展,通过合成具有更高多样性和真实感的数据,为数据增强提供了一种新的范例。然而,与裁剪或旋转等传统增强方法不同,这些方法引入了实质性的变化,虽然增强了鲁棒性,但也可能因增强与任务不匹配而降低性能。本文提出EvoAug,一种自动增强学习流程,它利用这些生成模型以及高效的进化算法来学习最优的任务特定增强。我们的流程引入了一种新颖的图像增强方法,该方法学习分层组合增强的随机增强树,从而实现更结构化和自适应的转换。我们在细粒度分类和少样本学习任务中展示了强大的性能。值得注意的是,我们的流程发现了与领域知识相符的增强,即使在低数据设置下也是如此。这些结果突出了学习到的生成增强的潜力,为鲁棒模型训练开辟了新的可能性。
🔬 方法详解
问题定义:论文旨在解决如何有效地利用生成模型进行数据增强的问题。现有方法,如直接应用生成模型合成的数据,可能因为生成数据与任务不匹配而导致性能下降。传统的增强方法,如裁剪和旋转,缺乏利用生成模型所能提供的多样性和真实感的能力。因此,需要一种自动化的方法来学习任务特定的、能够充分利用生成模型优势的增强策略。
核心思路:论文的核心思路是利用进化算法自动搜索最优的增强策略。通过将生成模型与进化算法相结合,EvoAug能够学习到与特定任务相匹配的增强策略,从而在提高模型鲁棒性的同时,避免性能下降。这种方法允许模型在训练过程中探索不同的增强组合,并选择最有效的策略。
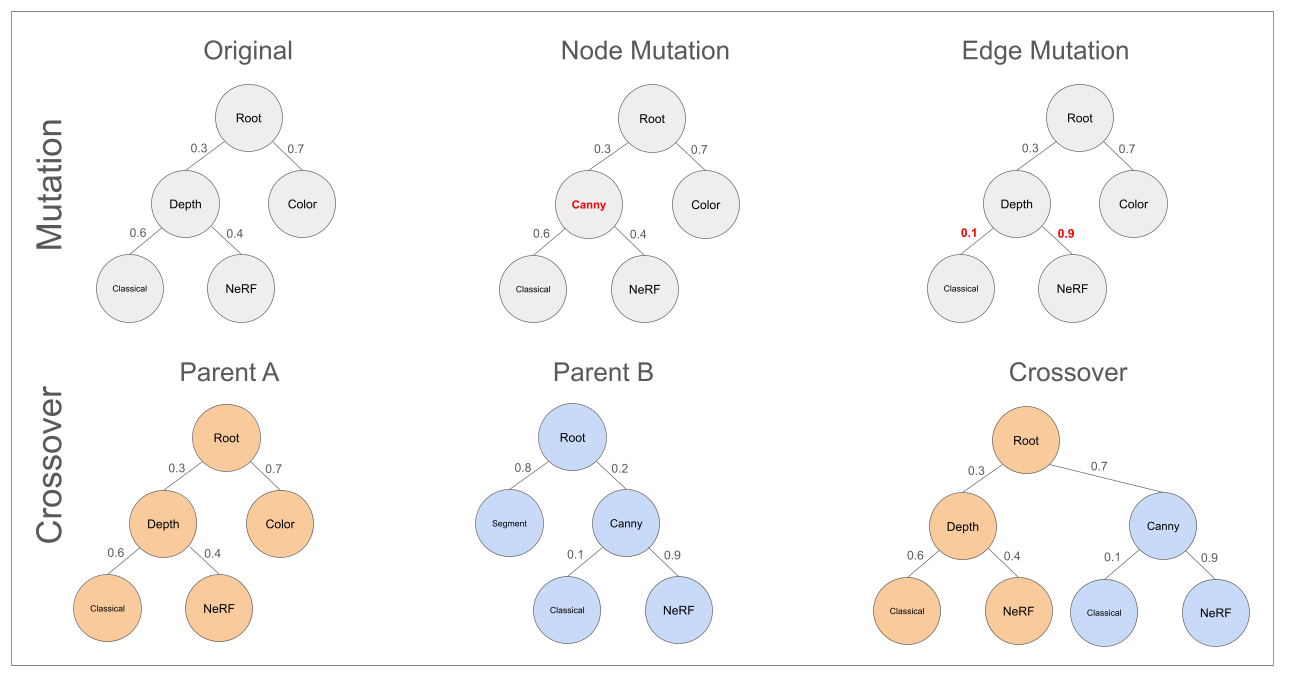
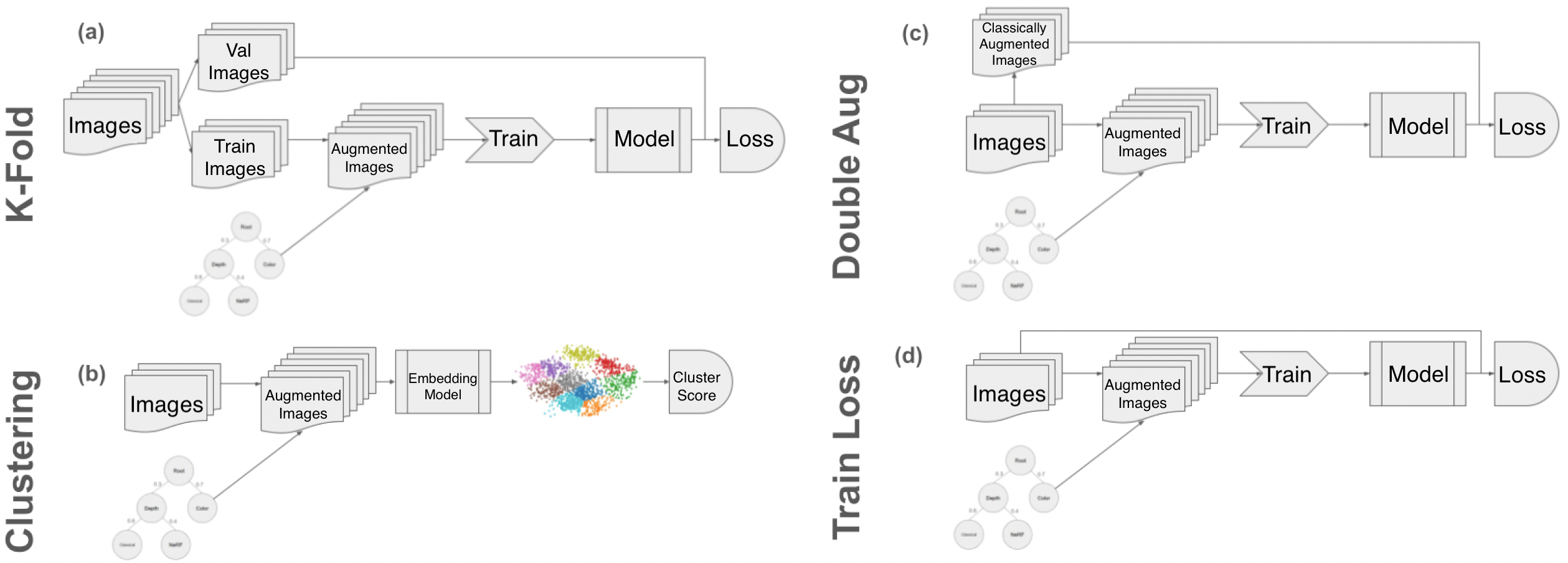
技术框架:EvoAug的整体框架包含以下几个主要模块:1) 生成模型:用于生成多样化的增强数据。可以使用条件扩散模型、GAN或NeRF等。2) 增强树:定义了增强操作的组合方式,形成一个分层的结构。每个节点代表一个增强操作,叶节点表示原始图像或生成图像。3) 进化算法:用于搜索最优的增强树结构和参数。通过选择、交叉和变异等操作,不断优化增强树的性能。4) 评估函数:用于评估增强树的性能。通常使用验证集上的模型性能作为评估指标。
关键创新:EvoAug的关键创新在于:1) 自动化增强学习:无需人工设计增强策略,而是通过进化算法自动搜索。2) 分层增强树:允许更灵活和结构化的增强组合,能够更好地适应不同的任务。3) 生成模型集成:充分利用生成模型生成的多样化数据,提高模型的鲁棒性。
关键设计:EvoAug的关键设计包括:1) 增强树的表示:如何有效地表示增强树的结构和参数。可以使用树状结构或图结构。2) 进化算法的参数:选择合适的选择、交叉和变异算子,以及种群大小和迭代次数等参数。3) 评估函数的选择:使用合适的评估指标来衡量增强树的性能。可以使用验证集上的准确率、F1-score等指标。4) 生成模型的选择和训练:选择合适的生成模型,并进行有效的训练,以生成高质量的增强数据。
🖼️ 关键图片

📊 实验亮点
EvoAug在细粒度分类和少样本学习任务中取得了显著的性能提升。例如,在CUB-200-2011数据集上,EvoAug相比于基线方法提高了多个百分点。此外,EvoAug能够发现与领域知识相符的增强策略,例如在鸟类分类任务中,EvoAug倾向于使用与鸟类姿态和光照条件相关的增强。
🎯 应用场景
EvoAug可应用于各种计算机视觉任务,尤其是在数据量有限或需要高鲁棒性的场景下,如医学图像分析、自动驾驶、遥感图像处理等。通过自动学习任务特定的增强策略,可以显著提高模型的泛化能力和鲁棒性,降低人工干预成本,加速模型开发流程。未来,EvoAug有望扩展到其他领域,如自然语言处理和语音识别。
📄 摘要(原文)
Data augmentation has long been a cornerstone for reducing overfitting in vision models, with methods like AutoAugment automating the design of task-specific augmentations. Recent advances in generative models, such as conditional diffusion and few-shot NeRFs, offer a new paradigm for data augmentation by synthesizing data with significantly greater diversity and realism. However, unlike traditional augmentations like cropping or rotation, these methods introduce substantial changes that enhance robustness but also risk degrading performance if the augmentations are poorly matched to the task. In this work, we present EvoAug, an automated augmentation learning pipeline, which leverages these generative models alongside an efficient evolutionary algorithm to learn optimal task-specific augmentations. Our pipeline introduces a novel approach to image augmentation that learns stochastic augmentation trees that hierarchically compose augmentations, enabling more structured and adaptive transformations. We demonstrate strong performance across fine-grained classification and few-shot learning tasks. Notably, our pipeline discovers augmentations that align with domain knowledge, even in low-data settings. These results highlight the potential of learned generative augmentations, unlocking new possibilities for robust model training.