VOILA: Value-of-Information Guided Fidelity Selection for Cost-Aware Multimodal Question Answering
作者: Rahul Atul Bhope, K. R. Jayaram, Vinod Muthusamy, Ritesh Kumar, Vatche Isahagian, Nalini Venkatasubramanian
分类: cs.CV, cs.AI, cs.LG
发布日期: 2026-02-03
💡 一句话要点
提出VOILA框架,通过信息价值指导的多模态问答保真度选择,优化资源受限场景。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态问答 视觉问答 保真度选择 信息价值 资源优化
📋 核心要点
- 现有VQA系统通常采用固定保真度的视觉输入,忽略了高保真图像带来的巨大计算成本。
- VOILA框架通过预测不同保真度下的答案正确率,并结合检索成本,选择最优的保真度进行推理。
- 实验表明,VOILA能在保持较高准确率的同时,显著降低计算成本,适用于资源受限的场景。
📝 摘要(中文)
大多数多模态视觉-语言系统在高保真视觉输入上运行,忽略了其显著的检索和处理成本。本文提出了VOILA,一个信息价值驱动的自适应保真度选择框架,用于视觉问答(VQA),旨在优化模型执行前的信息检索策略。给定一个查询,VOILA采用两阶段流程:首先,一个梯度提升回归器仅使用问题特征估计每个保真度下的正确性概率;然后,一个等渗校准器细化这些概率,以实现可靠的决策。系统选择最小成本的保真度,以最大化基于预测准确性和检索成本的预期效用。在三个部署场景中使用五个数据集(VQA-v2、GQA、TextVQA、LoCoMo、FloodNet)和六个具有7B-235B参数的视觉-语言模型(VLM)评估了VOILA。结果表明,VOILA在保持90-95%全分辨率准确率的同时,始终如一地实现了50-60%的成本降低,证明了预检索保真度选择对于优化资源约束下的多模态推理至关重要。
🔬 方法详解
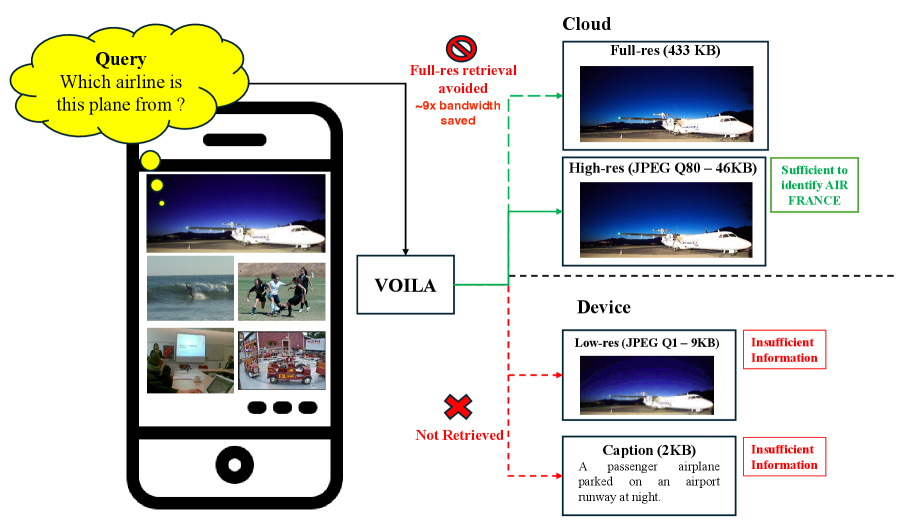
问题定义:现有的多模态视觉问答系统通常采用固定分辨率的图像,忽略了不同问题对图像细节的需求差异。高分辨率图像虽然可能提升准确率,但会带来更高的计算成本和延迟,尤其是在资源受限的场景下,这种固定策略效率低下。因此,如何根据问题自适应地选择合适的图像分辨率,以在准确率和计算成本之间取得平衡,是本文要解决的核心问题。
核心思路:VOILA的核心思路是基于“信息价值”来指导图像保真度的选择。具体来说,就是预测不同保真度下回答问题的准确率,并结合检索和处理图像的成本,选择能够最大化“信息价值”(即准确率提升减去成本)的保真度。这种方法允许系统在计算资源有限的情况下,优先处理那些能够带来显著准确率提升的图像。
技术框架:VOILA框架包含两个主要阶段:1) 准确率预测阶段:使用梯度提升回归器,仅基于问题特征,预测在不同图像保真度下回答问题的准确率。然后,使用等渗校准器对预测的概率进行校准,以提高预测的可靠性。2) 保真度选择阶段:基于预测的准确率和不同保真度的成本,计算每个保真度的预期效用。选择预期效用最高的保真度,用于后续的视觉-语言模型推理。
关键创新:VOILA的关键创新在于其预检索的保真度选择机制。与传统的固定保真度方法不同,VOILA能够根据问题的内容和资源约束,动态地选择最合适的图像保真度。这种自适应选择机制能够显著降低计算成本,同时保持较高的准确率。此外,VOILA框架的通用性使其能够与各种视觉-语言模型和数据集兼容。
关键设计:准确率预测阶段使用梯度提升回归器(Gradient Boosted Regressor)来预测不同保真度下的准确率。等渗回归(Isotonic Regression)用于校准预测概率,确保预测的可靠性。在保真度选择阶段,系统通过最大化预期效用(Expected Utility)来选择最佳保真度,预期效用定义为准确率提升减去成本。成本可以根据实际部署环境进行调整,例如,可以考虑图像检索时间、计算资源消耗等因素。
🖼️ 关键图片
📊 实验亮点
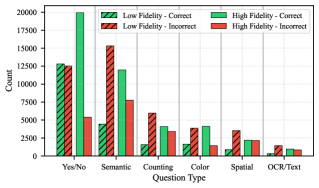
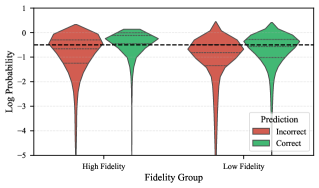
实验结果表明,VOILA在VQA-v2、GQA、TextVQA、LoCoMo和FloodNet等五个数据集上,以及7B到235B参数的六个视觉-语言模型上,均取得了显著的成本降低。具体来说,VOILA能够在保持90-95%全分辨率准确率的同时,实现50-60%的成本降低,证明了其在资源受限场景下的有效性。
🎯 应用场景
VOILA框架适用于各种资源受限的多模态视觉问答场景,例如移动设备上的图像搜索、边缘计算环境下的智能监控、以及需要快速响应的实时问答系统。通过自适应地选择图像保真度,VOILA能够显著降低计算成本和延迟,提高系统的效率和用户体验,并为未来的低功耗AI应用提供了新的思路。
📄 摘要(原文)
Despite significant costs from retrieving and processing high-fidelity visual inputs, most multimodal vision-language systems operate at fixed fidelity levels. We introduce VOILA, a framework for Value-Of-Information-driven adaptive fidelity selection in Visual Question Answering (VQA) that optimizes what information to retrieve before model execution. Given a query, VOILA uses a two-stage pipeline: a gradient-boosted regressor estimates correctness likelihood at each fidelity from question features alone, then an isotonic calibrator refines these probabilities for reliable decision-making. The system selects the minimum-cost fidelity maximizing expected utility given predicted accuracy and retrieval costs. We evaluate VOILA across three deployment scenarios using five datasets (VQA-v2, GQA, TextVQA, LoCoMo, FloodNet) and six Vision-Language Models (VLMs) with 7B-235B parameters. VOILA consistently achieves 50-60% cost reductions while retaining 90-95% of full-resolution accuracy across diverse query types and model architectures, demonstrating that pre-retrieval fidelity selection is vital to optimize multimodal inference under resource constraints.