Video-OPD: Efficient Post-Training of Multimodal Large Language Models for Temporal Video Grounding via On-Policy Distillation
作者: Jiaze Li, Hao Yin, Haoran Xu, Boshen Xu, Wenhui Tan, Zewen He, Jianzhong Ju, Zhenbo Luo, Jian Luan
分类: cs.CV
发布日期: 2026-02-03
💡 一句话要点
提出Video-OPD,通过在策略蒸馏高效后训练多模态大语言模型,用于时序视频定位。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时序视频定位 多模态大语言模型 在策略蒸馏 后训练 强化学习 课程学习 视频理解
📋 核心要点
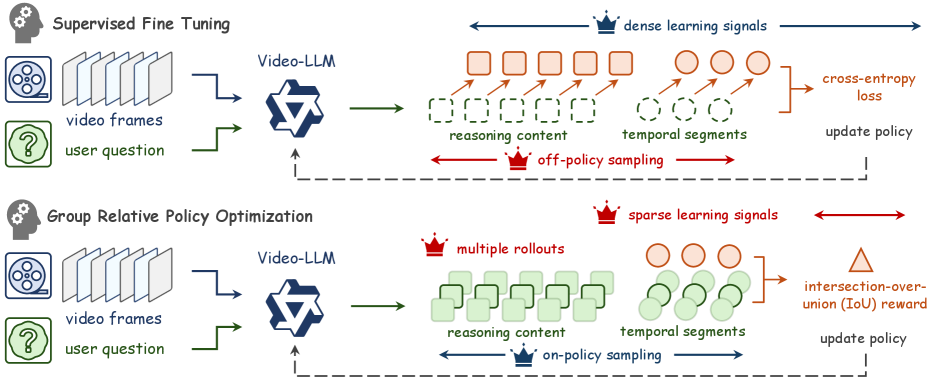
- 现有基于GRPO的视频定位方法受限于稀疏奖励信号和巨大的计算开销。
- Video-OPD通过在策略蒸馏,利用教师模型提供密集token级别监督,优化当前策略采样轨迹。
- 实验表明,Video-OPD在性能上优于GRPO,并显著降低了计算成本,提高了收敛速度。
📝 摘要(中文)
本文提出Video-OPD,一个高效的后训练框架,用于时序视频定位(TVG)。该框架受到在策略蒸馏最新进展的启发,直接优化从当前策略中采样的轨迹,从而保持训练和推理分布之间的一致性。同时,一个前沿教师模型通过反向KL散度目标提供密集的token级别监督。这种公式保留了对于缓解分布偏移至关重要的在策略属性,同时将稀疏的episode级别反馈转换为细粒度的、逐步的学习信号。基于Video-OPD,我们引入了教师验证的不一致性聚焦(TVDF),这是一个轻量级的训练课程,迭代地优先考虑那些教师可靠且对学生最具信息量的轨迹,从而提高训练效率。实验结果表明,Video-OPD始终优于GRPO,同时实现了更快的收敛速度和更低的计算成本,确立了在策略蒸馏作为TVG传统强化学习的有效替代方案。
🔬 方法详解
问题定义:时序视频定位(TVG)旨在从视频中找到与给定文本查询相关的特定时间片段。现有基于强化学习的后训练方法,如GRPO,虽然利用了on-policy优化,但面临着稀疏奖励信号和高计算成本的挑战,导致训练效率低下和性能瓶颈。
核心思路:Video-OPD的核心思路是利用在策略蒸馏,将强化学习中的稀疏奖励信号转化为密集的token级别监督信号。通过引入一个“教师”模型,为“学生”模型提供更细粒度的指导,从而加速学习过程并提高性能。同时,保持on-policy特性,避免训练和推理阶段的分布偏移。
技术框架:Video-OPD框架包含一个学生模型和一个教师模型。学生模型是待训练的多模态大语言模型,教师模型提供token级别的监督信号。训练过程主要包括:1) 从当前学生模型策略中采样轨迹;2) 教师模型对采样轨迹进行评估,生成token级别的目标;3) 学生模型通过最小化与教师模型输出的KL散度进行学习;4) 引入Teacher-Validated Disagreement Focusing (TVDF) 课程学习,迭代地选择教师模型可靠且学生模型预测差异大的轨迹进行训练。
关键创新:Video-OPD的关键创新在于将在策略蒸馏引入到时序视频定位的后训练中。与传统的强化学习方法相比,它利用教师模型提供的密集监督信号,克服了稀疏奖励带来的挑战,显著提高了训练效率和性能。此外,TVDF课程学习方法进一步提升了训练效率,通过聚焦于教师可靠且学生不确定的样本,加速了学习过程。
关键设计:Video-OPD使用反向KL散度作为损失函数,鼓励学生模型的输出接近教师模型的输出。TVDF课程学习方法通过计算教师模型的置信度和学生模型的预测差异,来选择训练样本。具体的参数设置和网络结构细节在论文中有详细描述,例如教师模型的选择、KL散度的权重、以及TVDF中置信度和差异的计算方式。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Video-OPD在时序视频定位任务上显著优于GRPO等基线方法,实现了更快的收敛速度和更低的计算成本。具体而言,Video-OPD在多个数据集上取得了SOTA的结果,并且训练时间缩短了约50%。TVDF课程学习方法进一步提升了训练效率,使得模型能够更快地达到最佳性能。
🎯 应用场景
Video-OPD在视频内容理解、智能视频搜索、视频编辑和智能监控等领域具有广泛的应用前景。它可以帮助用户更准确地定位视频中的关键时刻,提高视频分析和处理的效率。未来,该技术可以应用于更复杂的视频理解任务,例如视频摘要生成、视频问答等。
📄 摘要(原文)
Reinforcement learning has emerged as a principled post-training paradigm for Temporal Video Grounding (TVG) due to its on-policy optimization, yet existing GRPO-based methods remain fundamentally constrained by sparse reward signals and substantial computational overhead. We propose Video-OPD, an efficient post-training framework for TVG inspired by recent advances in on-policy distillation. Video-OPD optimizes trajectories sampled directly from the current policy, thereby preserving alignment between training and inference distributions, while a frontier teacher supplies dense, token-level supervision via a reverse KL divergence objective. This formulation preserves the on-policy property critical for mitigating distributional shift, while converting sparse, episode-level feedback into fine-grained, step-wise learning signals. Building on Video-OPD, we introduce Teacher-Validated Disagreement Focusing (TVDF), a lightweight training curriculum that iteratively prioritizes trajectories that are both teacher-reliable and maximally informative for the student, thereby improving training efficiency. Empirical results demonstrate that Video-OPD consistently outperforms GRPO while achieving substantially faster convergence and lower computational cost, establishing on-policy distillation as an effective alternative to conventional reinforcement learning for TVG.