Superman: Unifying Skeleton and Vision for Human Motion Perception and Generation
作者: Xinshun Wang, Peiming Li, Ziyi Wang, Zhongbin Fang, Zhichao Deng, Songtao Wu, Jason Li, Mengyuan Liu
分类: cs.CV
发布日期: 2026-02-02
💡 一句话要点
Superman:统一骨骼与视觉信息,实现人体运动感知与生成
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱六:视频提取与匹配 (Video Extraction) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 人体运动分析 运动生成 跨模态学习 视觉感知 骨骼数据
📋 核心要点
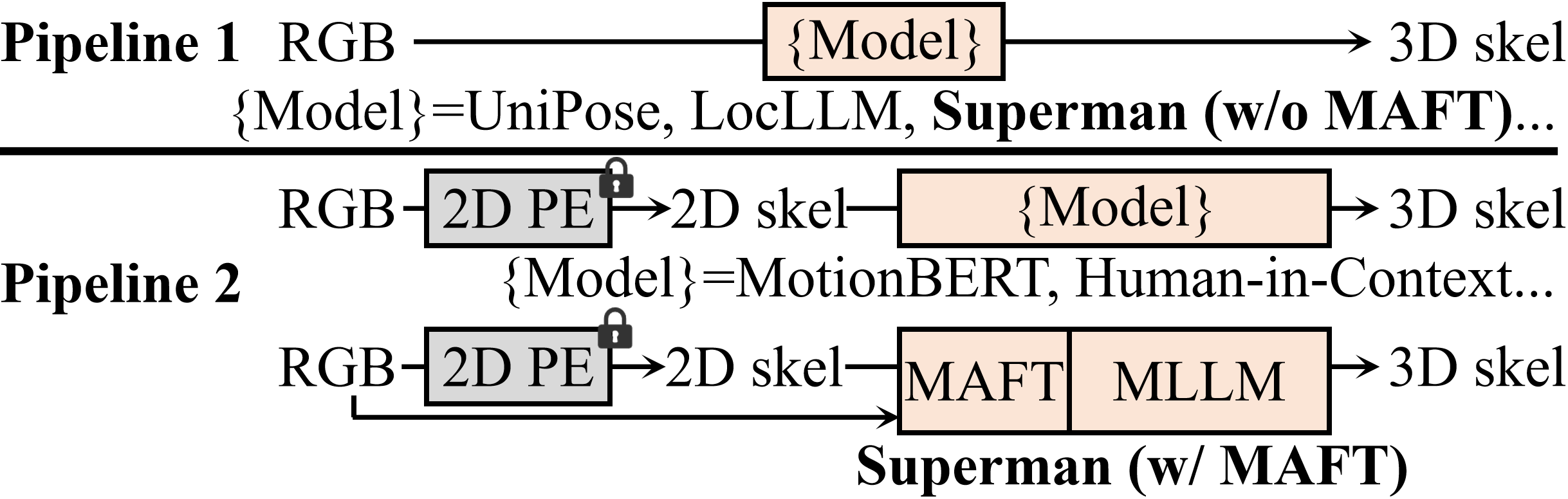
- 现有方法在人体运动分析中存在感知和生成模型分离、生成模型缺乏时序处理能力、运动词汇表与视觉信息脱节等问题。
- Superman框架通过视觉引导的运动Tokenizer,学习统一的跨模态运动词汇表,并利用统一的MLLM架构处理感知和生成任务。
- 实验结果表明,Superman在Human3.6M等数据集上,在3D姿态估计、运动预测和插值等任务中取得了SOTA或具有竞争力的性能。
📝 摘要(中文)
人体运动分析任务,如时序3D姿态估计、运动预测和运动插值,在计算机视觉中至关重要。然而,当前的范式存在严重的分裂。首先,该领域被分割为“感知”模型(从视频理解运动但仅输出文本)和“生成”模型(无法从原始视觉输入进行感知)。其次,生成式MLLM通常局限于使用密集参数化SMPL模型的单帧静态姿势,无法处理时序运动。第三,现有的运动词汇表仅从骨骼数据构建,切断了与视觉领域的联系。为了解决这些挑战,我们提出了Superman,一个统一的框架,将视觉感知与基于骨骼的时序运动生成桥接起来。我们的解决方案是双重的。首先,为了克服模态断连,我们提出了视觉引导的运动Tokenizer。利用3D骨骼和视觉数据之间的自然几何对齐,该模块率先实现了来自两种模态的鲁棒联合学习,创建了一个统一的跨模态运动词汇表。其次,基于这种运动语言,训练了一个单一的统一MLLM架构来处理所有任务。该模块灵活地处理各种时序输入,统一了来自视频的3D骨骼姿态估计(感知)与基于骨骼的运动预测和插值(生成)。在包括Human3.6M在内的标准基准上的大量实验表明,我们的统一方法在所有运动任务中都实现了最先进或具有竞争力的性能。这展示了使用骨骼进行生成式运动分析的更有效和可扩展的路径。
🔬 方法详解
问题定义:现有的人体运动分析方法存在多个痛点。一方面,感知模型和生成模型是分离的,感知模型只能从视频中提取信息,输出文本描述,而生成模型无法直接从视觉输入生成运动。另一方面,现有的生成模型通常只能处理单帧静态姿势,无法处理时序运动。此外,运动词汇表通常只基于骨骼数据构建,缺乏与视觉信息的联系。
核心思路:Superman的核心思路是构建一个统一的框架,将视觉感知与基于骨骼的时序运动生成桥接起来。通过学习一个跨模态的运动词汇表,并利用一个统一的MLLM架构,实现对感知和生成任务的统一处理。这种设计旨在克服现有方法的模态断连问题,并提高模型的泛化能力。
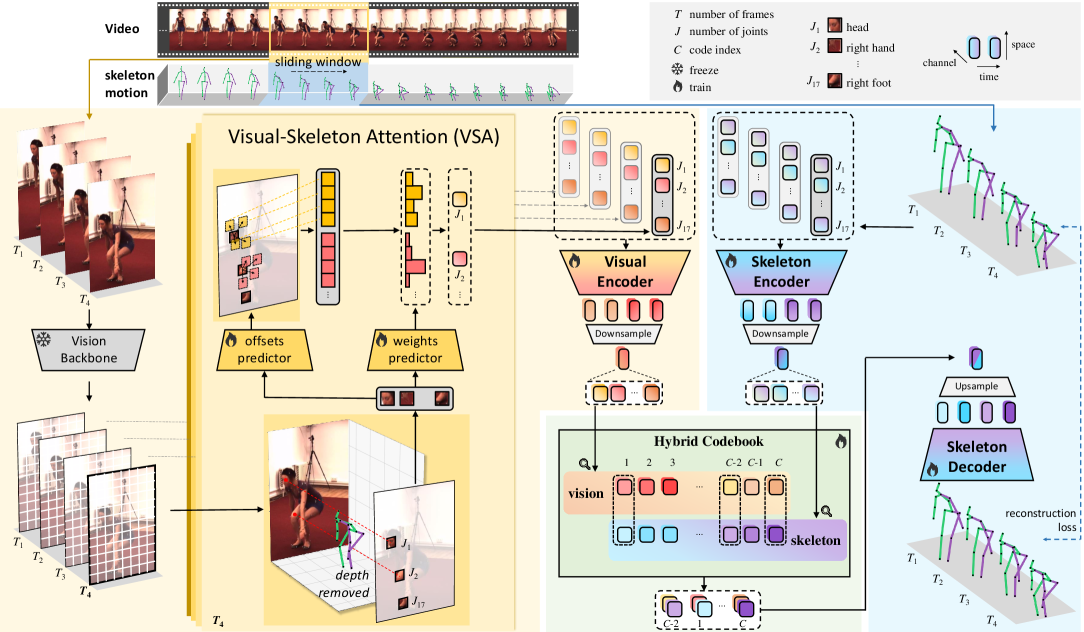
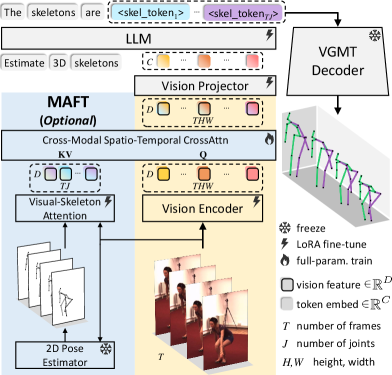
技术框架:Superman框架主要包含两个核心模块:视觉引导的运动Tokenizer和统一的MLLM架构。视觉引导的运动Tokenizer负责从视觉和骨骼数据中学习统一的运动词汇表。统一的MLLM架构则负责处理各种运动分析任务,包括3D姿态估计、运动预测和运动插值。整个流程是,首先通过Tokenizer将视觉和骨骼数据转换为运动token,然后将这些token输入到MLLM中进行处理,最后得到相应的输出。
关键创新:Superman最重要的技术创新点在于视觉引导的运动Tokenizer。该模块利用3D骨骼和视觉数据之间的自然几何对齐关系,实现了来自两种模态的鲁棒联合学习,从而创建了一个统一的跨模态运动词汇表。与现有方法相比,该Tokenizer能够更好地捕捉视觉信息和骨骼信息之间的关联,从而提高模型的性能。
关键设计:视觉引导的运动Tokenizer的具体实现细节未知,但可以推测其可能采用了某种形式的对比学习或自监督学习方法,以学习视觉和骨骼数据之间的对应关系。统一的MLLM架构的具体结构也未知,但可以推测其可能采用了Transformer或类似的模型结构,以处理时序数据。损失函数的设计可能包括姿态估计损失、运动预测损失和运动插值损失等。
🖼️ 关键图片
📊 实验亮点
Superman在Human3.6M等标准数据集上进行了大量实验,结果表明,该方法在3D姿态估计、运动预测和运动插值等任务中取得了SOTA或具有竞争力的性能。具体的数据提升幅度未知,但论文强调了该方法在所有运动任务中都表现出色,证明了其有效性和泛化能力。
🎯 应用场景
Superman框架具有广泛的应用前景,例如虚拟现实、游戏、动画制作、运动分析、康复训练等领域。该框架可以用于生成逼真的人体运动,提高用户体验,并为运动分析和康复训练提供更准确的评估和指导。未来,该研究可以进一步扩展到更复杂的场景,例如多人交互、复杂环境等。
📄 摘要(原文)
Human motion analysis tasks, such as temporal 3D pose estimation, motion prediction, and motion in-betweening, play an essential role in computer vision. However, current paradigms suffer from severe fragmentation. First, the field is split between
perception'' models that understand motion from video but only output text, andgeneration'' models that cannot perceive from raw visual input. Second, generative MLLMs are often limited to single-frame, static poses using dense, parametric SMPL models, failing to handle temporal motion. Third, existing motion vocabularies are built from skeleton data alone, severing the link to the visual domain. To address these challenges, we introduce Superman, a unified framework that bridges visual perception with temporal, skeleton-based motion generation. Our solution is twofold. First, to overcome the modality disconnect, we propose a Vision-Guided Motion Tokenizer. Leveraging the natural geometric alignment between 3D skeletons and visual data, this module pioneers robust joint learning from both modalities, creating a unified, cross-modal motion vocabulary. Second, grounded in this motion language, a single, unified MLLM architecture is trained to handle all tasks. This module flexibly processes diverse, temporal inputs, unifying 3D skeleton pose estimation from video (perception) with skeleton-based motion prediction and in-betweening (generation). Extensive experiments on standard benchmarks, including Human3.6M, demonstrate that our unified method achieves state-of-the-art or competitive performance across all motion tasks. This showcases a more efficient and scalable path for generative motion analysis using skeletons.