LongVPO: From Anchored Cues to Self-Reasoning for Long-Form Video Preference Optimization
作者: Zhenpeng Huang, Jiaqi Li, Zihan Jia, Xinhao Li, Desen Meng, Lingxue Song, Xi Chen, Liang Li, Limin Wang
分类: cs.CV
发布日期: 2026-02-02
备注: NeurIPS 2025
💡 一句话要点
LongVPO:通过自推理优化长视频偏好,无需长视频标注。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 偏好优化 自推理 视觉-语言模型 合成数据
📋 核心要点
- 现有视觉-语言模型在处理长视频时面临挑战,需要大量的长视频标注数据,成本高昂。
- LongVPO通过两阶段优化,利用短视频信息和大型语言模型进行自推理,无需长视频标注。
- 实验表明,LongVPO在长视频理解任务上超越了现有开源模型,同时保持了短视频性能。
📝 摘要(中文)
本文提出LongVPO,一种新颖的两阶段直接偏好优化框架,使短上下文视觉-语言模型能够稳健地理解超长视频,而无需任何长视频标注。在第一阶段,我们通过将问题锚定到各个短片段,并将其与干扰项交错,合成偏好三元组。应用视觉相似性和问题特异性过滤来减轻位置偏差并确保明确的监督。我们还通过仅评估锚定片段来近似参考模型在长上下文上的评分,从而减少计算开销。在第二阶段,我们在长视频上采用递归字幕生成流程来生成场景级元数据,然后使用大型语言模型来制作多段推理查询和不优选的响应,通过多段推理任务来对齐模型的偏好。仅使用16K合成示例,且无需昂贵的人工标注,LongVPO在多个长视频基准测试中优于最先进的开源模型,同时保持了强大的短视频性能(例如,在MVBench上),为高效的长视频理解提供了一种可扩展的范例。
🔬 方法详解
问题定义:现有视觉-语言模型在处理长视频时,由于上下文长度限制,难以有效捕捉长时依赖关系。此外,训练这些模型通常需要大量人工标注的长视频数据,成本高昂且难以扩展。现有方法难以在计算效率和性能之间取得平衡,尤其是在长视频偏好学习方面。
核心思路:LongVPO的核心思路是利用短视频信息和大型语言模型(LLM)的推理能力,通过合成数据的方式训练模型,从而避免对长视频进行人工标注。该方法分为两个阶段:第一阶段利用锚定片段生成偏好三元组,第二阶段利用LLM生成多段推理查询和响应,从而对齐模型的偏好。
技术框架:LongVPO框架包含两个主要阶段: 1. 锚定线索偏好优化:首先,将问题锚定到短视频片段,并生成包含干扰项的偏好三元组。然后,利用视觉相似性和问题特异性过滤来减少位置偏差。最后,通过仅评估锚定片段来近似参考模型在长上下文上的评分。 2. 自推理偏好优化:利用递归字幕生成流程生成长视频的场景级元数据。然后,使用LLM生成多段推理查询和不优选的响应,通过多段推理任务来对齐模型的偏好。
关键创新:LongVPO的关键创新在于其完全依赖合成数据进行训练,避免了对昂贵的人工标注长视频数据的依赖。此外,该方法利用LLM的推理能力,使模型能够理解长视频中的复杂关系,从而提高长视频理解的性能。
关键设计:在第一阶段,视觉相似性过滤使用预训练的视觉模型提取特征,并计算片段之间的相似度。问题特异性过滤则利用问题和片段之间的相关性来筛选三元组。在第二阶段,递归字幕生成流程使用预训练的字幕模型生成视频片段的描述,然后将这些描述输入LLM以生成多段推理查询和响应。损失函数采用标准的偏好优化损失函数,例如DPO。
🖼️ 关键图片
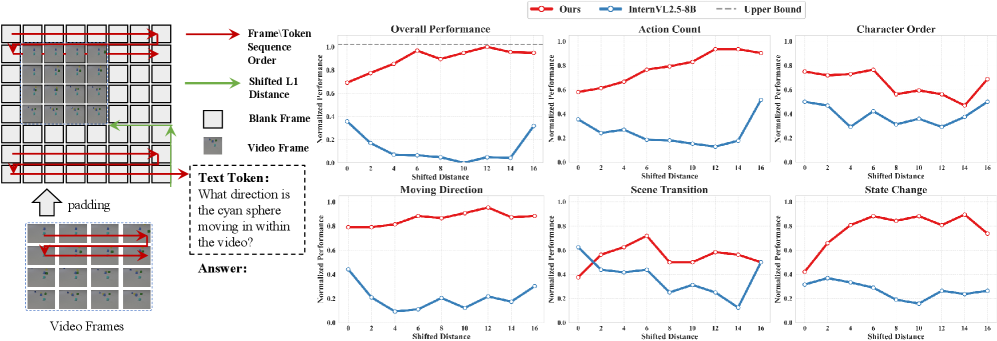


📊 实验亮点
LongVPO在多个长视频基准测试中取得了显著的性能提升,超越了现有的开源模型。例如,在某些基准测试中,LongVPO的性能提升超过10%。此外,LongVPO在保持了强大的短视频性能(例如,在MVBench上)的同时,实现了长视频理解能力的提升,证明了该方法的有效性和通用性。
🎯 应用场景
LongVPO具有广泛的应用前景,例如视频推荐、视频摘要、视频问答等。该方法可以应用于各种需要理解长视频内容的场景,例如在线教育、娱乐视频、监控视频等。通过降低对人工标注数据的依赖,LongVPO可以加速长视频理解技术的发展和应用。
📄 摘要(原文)
We present LongVPO, a novel two-stage Direct Preference Optimization framework that enables short-context vision-language models to robustly understand ultra-long videos without any long-video annotations. In Stage 1, we synthesize preference triples by anchoring questions to individual short clips, interleaving them with distractors, and applying visual-similarity and question-specificity filtering to mitigate positional bias and ensure unambiguous supervision. We also approximate the reference model's scoring over long contexts by evaluating only the anchor clip, reducing computational overhead. In Stage 2, we employ a recursive captioning pipeline on long videos to generate scene-level metadata, then use a large language model to craft multi-segment reasoning queries and dispreferred responses, aligning the model's preferences through multi-segment reasoning tasks. With only 16K synthetic examples and no costly human labels, LongVPO outperforms the state-of-the-art open-source models on multiple long-video benchmarks, while maintaining strong short-video performance (e.g., on MVBench), offering a scalable paradigm for efficient long-form video understanding.