Enhancing Indoor Occupancy Prediction via Sparse Query-Based Multi-Level Consistent Knowledge Distillation
作者: Xiang Li, Yupeng Zheng, Pengfei Li, Yilun Chen, Ya-Qin Zhang, Wenchao Ding
分类: cs.CV
发布日期: 2026-02-02
备注: Accepted by RA-L
🔗 代码/项目: GITHUB
💡 一句话要点
提出DiScene以解决室内占用预测的效率与准确性问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 室内占用预测 知识蒸馏 稀疏查询 机器人导航 深度学习
📋 核心要点
- 现有的占用预测方法在复杂室内场景中面临效率与准确性的权衡,密集方法在空体素上浪费计算资源。
- 本文提出DiScene框架,采用多级一致性知识蒸馏策略和教师引导初始化策略,提升占用预测的效率与鲁棒性。
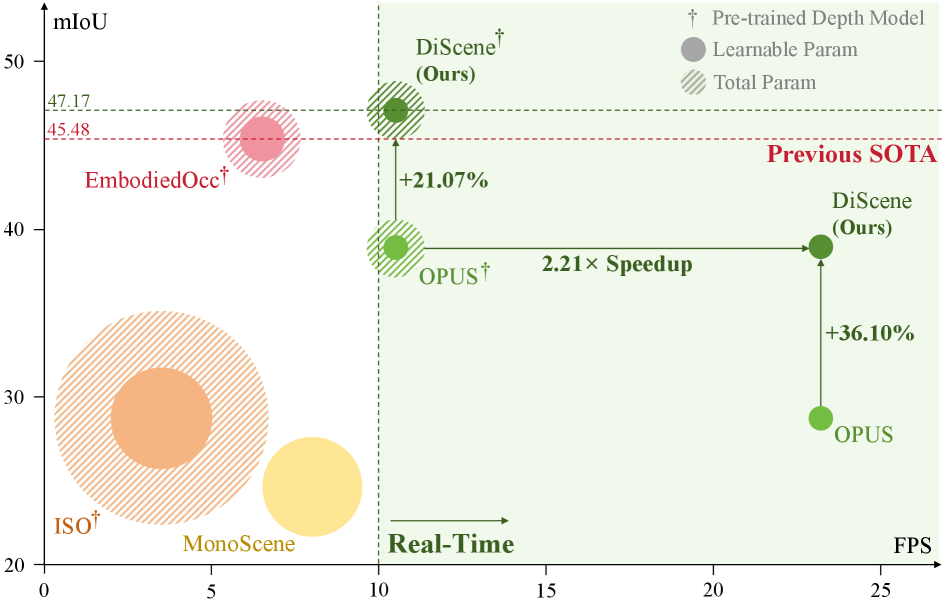
- 在Occ-Scannet基准测试中,DiScene以23.2 FPS的速度超越基线方法OPUS 36.1%,并在深度集成后实现更快的推理速度和更高的准确性。
📝 摘要(中文)
占用预测为机器人提供了重要的几何和语义理解,但面临效率与准确性的权衡。现有的密集方法在空体素上存在计算浪费,而稀疏查询方法在复杂室内场景中缺乏鲁棒性。本文提出了一种新颖的稀疏查询框架DiScene,通过多级蒸馏实现高效且鲁棒的占用预测。该方法的两个关键创新包括:1)多级一致性知识蒸馏策略,通过四个层次的协调对齐将大型教师模型的层次表示转移到轻量级学生模型;2)教师引导初始化策略,采用优化的参数预热加速模型收敛。DiScene在Occ-Scannet基准测试中以23.2 FPS的速度超越基线方法OPUS 36.1%,并在深度集成后实现新SOTA性能,超越EmbodiedOcc 3.7%。
🔬 方法详解
问题定义:本文旨在解决室内占用预测中的效率与准确性问题。现有的密集方法在处理空体素时存在计算浪费,而稀疏查询方法在复杂场景中表现不佳。
核心思路:提出DiScene框架,通过多级一致性知识蒸馏和教师引导初始化,旨在实现高效且鲁棒的占用预测。这样的设计使得模型能够在不同层次上进行知识转移,从而提升预测性能。
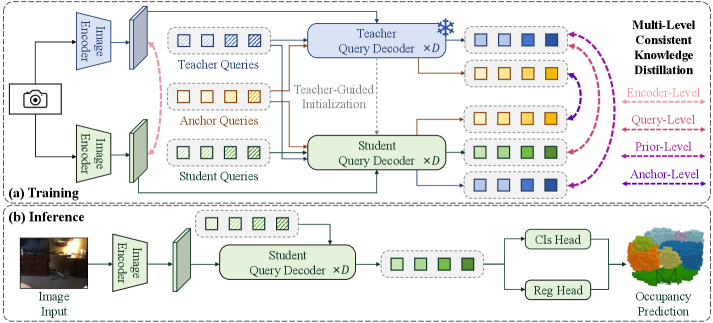
技术框架:DiScene的整体架构包括四个主要模块:编码器级特征对齐、查询级特征匹配、先验级空间引导和锚点级高置信度知识转移。通过这些模块的协同工作,模型能够有效整合来自教师模型的知识。
关键创新:最重要的技术创新在于多级一致性知识蒸馏策略,通过四个层次的对齐实现了知识的高效转移。这与现有方法的单一层次蒸馏方式有本质区别,显著提升了模型的鲁棒性。
关键设计:在参数设置上,采用优化的参数预热策略以加速模型收敛。此外,损失函数设计考虑了不同层次的特征对齐,确保了知识转移的有效性。
🖼️ 关键图片
📊 实验亮点
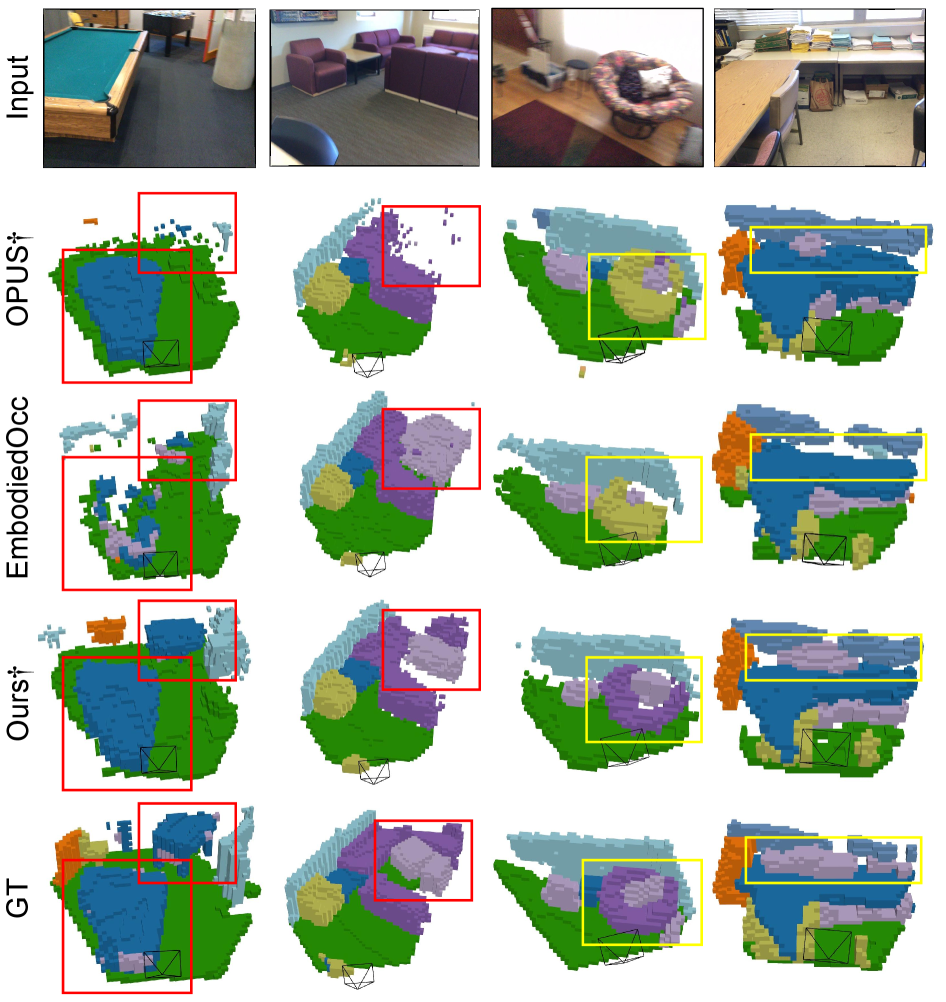
DiScene在Occ-Scannet基准测试中以23.2 FPS的速度超越基线方法OPUS 36.1%,并在深度集成后实现新SOTA性能,超越EmbodiedOcc 3.7%,推理速度提升1.62倍,展示了该方法在效率与准确性上的显著优势。
🎯 应用场景
该研究的潜在应用领域包括智能家居、机器人导航和安全监控等。通过提高室内占用预测的效率与准确性,DiScene能够在复杂环境中更好地支持机器人决策与行为规划,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Occupancy prediction provides critical geometric and semantic understanding for robotics but faces efficiency-accuracy trade-offs. Current dense methods suffer computational waste on empty voxels, while sparse query-based approaches lack robustness in diverse and complex indoor scenes. In this paper, we propose DiScene, a novel sparse query-based framework that leverages multi-level distillation to achieve efficient and robust occupancy prediction. In particular, our method incorporates two key innovations: (1) a Multi-level Consistent Knowledge Distillation strategy, which transfers hierarchical representations from large teacher models to lightweight students through coordinated alignment across four levels, including encoder-level feature alignment, query-level feature matching, prior-level spatial guidance, and anchor-level high-confidence knowledge transfer and (2) a Teacher-Guided Initialization policy, employing optimized parameter warm-up to accelerate model convergence. Validated on the Occ-Scannet benchmark, DiScene achieves 23.2 FPS without depth priors while outperforming our baseline method, OPUS, by 36.1% and even better than the depth-enhanced version, OPUS†. With depth integration, DiScene† attains new SOTA performance, surpassing EmbodiedOcc by 3.7% with 1.62$\times$ faster inference speed. Furthermore, experiments on the Occ3D-nuScenes benchmark and in-the-wild scenarios demonstrate the versatility of our approach in various environments. Code and models can be accessed at https://github.com/getterupper/DiScene.