LangMap: A Hierarchical Benchmark for Open-Vocabulary Goal Navigation
作者: Bo Miao, Weijia Liu, Jun Luo, Lachlan Shinnick, Jian Liu, Thomas Hamilton-Smith, Yuhe Yang, Zijie Wu, Vanja Videnovic, Feras Dayoub, Anton van den Hengel
分类: cs.CV, cs.RO
发布日期: 2026-02-02
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出LangMap:一个用于开放词汇目标导航的分层基准测试。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 具身导航 开放词汇 分层语义 基准测试 自然语言理解
📋 核心要点
- 现有具身导航方法在开放词汇和多粒度语义理解方面存在不足,难以实现人类与AI之间的有效沟通。
- LangMap通过构建一个大规模、分层标注的基准测试,提供更丰富的上下文信息,从而提升智能体对自然语言指令的理解能力。
- 实验表明,更丰富的上下文和记忆有助于提高导航成功率,但长尾目标和多目标完成仍然是挑战。
📝 摘要(中文)
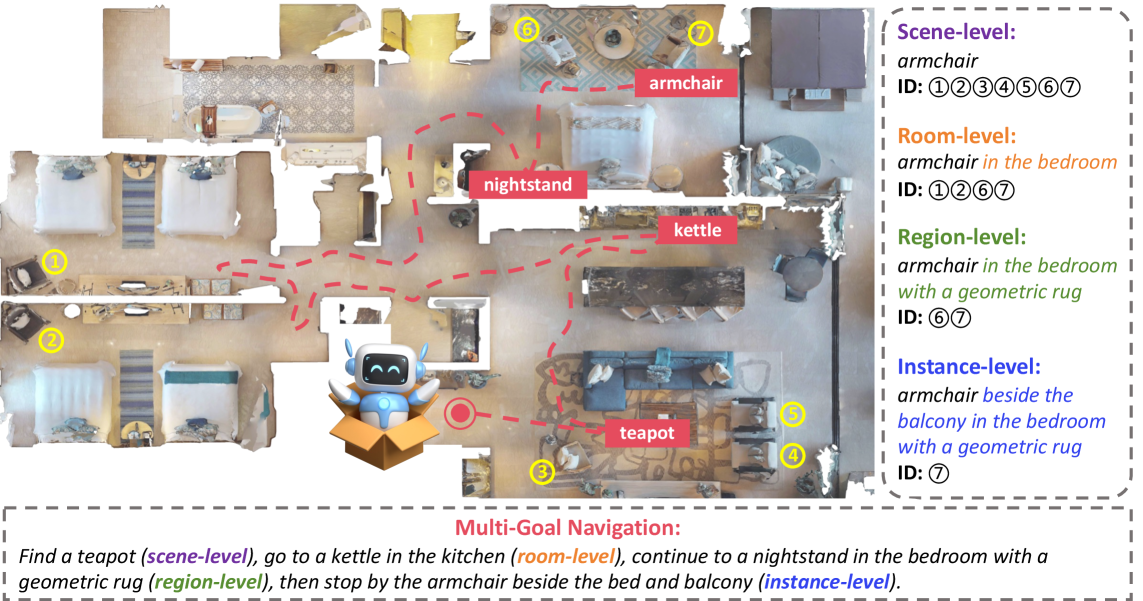
本文提出了HieraNav,一个多粒度、开放词汇的目标导航任务,其中智能体需要理解自然语言指令,并在四个语义级别(场景、房间、区域和实例)上到达目标。为此,作者构建了Language as a Map (LangMap),这是一个大规模基准测试,它基于真实世界的3D室内扫描,并具有全面的人工验证标注和任务,涵盖了上述四个语义级别。LangMap提供了区域标签、可区分的区域描述、涵盖414个对象类别的可区分实例描述,以及超过18K个导航任务。每个目标都包含简洁和详细的描述,从而可以评估不同指令风格下的性能。LangMap在标注质量方面表现出色,使用四倍少的词汇量,其区分准确率比GOAT-Bench高出23.8%。对LangMap上的零样本和监督模型的全面评估表明,更丰富的上下文和记忆可以提高成功率,而长尾、小型、上下文相关和遥远的目标,以及多目标完成仍然具有挑战性。HieraNav和LangMap为推进语言驱动的具身导航建立了一个严格的测试平台。
🔬 方法详解
问题定义:现有开放词汇目标导航任务缺乏多粒度语义理解能力,难以应对真实场景中复杂多样的语言指令。现有方法通常依赖于有限的词汇表或简单的目标描述,无法有效利用场景中的上下文信息,导致导航性能受限。
核心思路:LangMap的核心思路是将语言理解与环境地图相结合,通过分层标注提供多粒度的语义信息,从而帮助智能体更好地理解自然语言指令,并规划导航路径。这种方法旨在弥合语言和视觉之间的鸿沟,使智能体能够像人类一样,根据语言描述在复杂环境中找到目标。
技术框架:LangMap包含以下主要组成部分:1) 基于真实世界3D室内扫描构建的大规模数据集;2) 四个语义级别(场景、房间、区域和实例)的分层标注;3) 可区分的区域和实例描述;4) 包含简洁和详细描述的导航任务。智能体接收自然语言指令,利用LangMap提供的语义信息,规划导航路径,最终到达目标位置。
关键创新:LangMap的关键创新在于其分层标注和可区分描述。分层标注允许智能体在不同语义级别上理解目标,从而更好地应对复杂指令。可区分描述则提供了更丰富的上下文信息,帮助智能体区分相似的目标。此外,LangMap还提供了大规模的导航任务,为训练和评估智能体的导航能力提供了充足的数据。
关键设计:LangMap使用了人工验证的标注,确保标注质量。为了生成可区分的区域和实例描述,作者采用了众包方法,并对描述进行了筛选和验证。导航任务的设计考虑了不同指令风格,包括简洁和详细的描述。此外,LangMap还提供了评估指标,用于衡量智能体在不同语义级别上的导航性能。
🖼️ 关键图片


📊 实验亮点
LangMap在区分准确率方面优于GOAT-Bench 23.8%,同时使用的词汇量减少了四倍。实验结果表明,更丰富的上下文和记忆有助于提高导航成功率。然而,长尾、小型、上下文相关和遥远的目标,以及多目标完成仍然是具有挑战性的问题,为未来的研究提供了方向。
🎯 应用场景
LangMap的研究成果可应用于机器人导航、智能家居、虚拟助手等领域。例如,它可以帮助服务型机器人在复杂环境中根据自然语言指令找到特定物品,或帮助虚拟助手理解用户的意图并执行相应的操作。该研究还有助于提升人机交互的自然性和效率,促进人工智能在实际生活中的应用。
📄 摘要(原文)
The relationships between objects and language are fundamental to meaningful communication between humans and AI, and to practically useful embodied intelligence. We introduce HieraNav, a multi-granularity, open-vocabulary goal navigation task where agents interpret natural language instructions to reach targets at four semantic levels: scene, room, region, and instance. To this end, we present Language as a Map (LangMap), a large-scale benchmark built on real-world 3D indoor scans with comprehensive human-verified annotations and tasks spanning these levels. LangMap provides region labels, discriminative region descriptions, discriminative instance descriptions covering 414 object categories, and over 18K navigation tasks. Each target features both concise and detailed descriptions, enabling evaluation across different instruction styles. LangMap achieves superior annotation quality, outperforming GOAT-Bench by 23.8% in discriminative accuracy using four times fewer words. Comprehensive evaluations of zero-shot and supervised models on LangMap reveal that richer context and memory improve success, while long-tailed, small, context-dependent, and distant goals, as well as multi-goal completion, remain challenging. HieraNav and LangMap establish a rigorous testbed for advancing language-driven embodied navigation. Project: https://bo-miao.github.io/LangMap