MAIN-VLA: Modeling Abstraction of Intention and eNvironment for Vision-Language-Action Models
作者: Zheyuan Zhou, Liang Du, Zixun Sun, Xiaoyu Zhou, Ruimin Ye, Qihao Chen, Yinda Chen, Lemiao Qiu
分类: cs.CV
发布日期: 2026-02-02
💡 一句话要点
MAIN-VLA:建模意图与环境抽象,提升VLA模型在复杂环境中的决策能力
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 意图抽象 环境语义抽象 深度语义对齐 开放世界游戏 强化学习
📋 核心要点
- 现有VLA模型在复杂动态环境中难以有效提取动作关键信息,导致决策效率低下。
- MAIN-VLA通过意图抽象和环境语义抽象,将决策建立在深度语义对齐上,而非简单的模式匹配。
- 实验表明,MAIN-VLA在开放世界游戏和大型PvP游戏中取得了state-of-the-art的性能,提升了决策质量和泛化能力。
📝 摘要(中文)
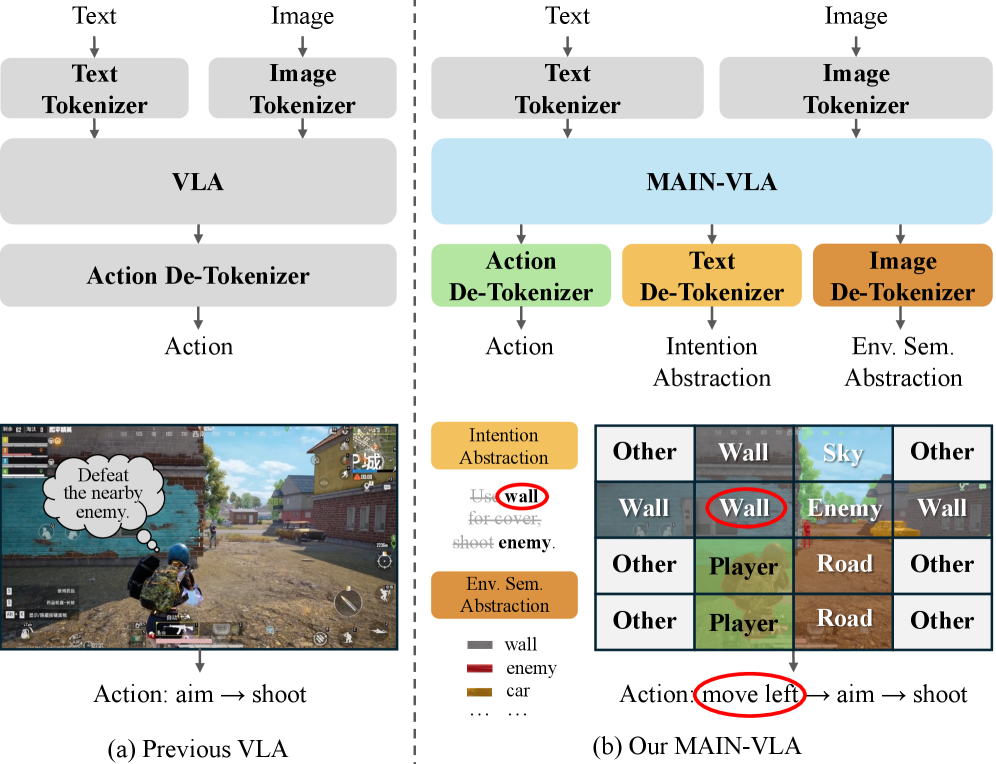
视觉-语言-动作(VLA)领域取得了显著进展,但在涉及实时、不可预测交互的高度复杂和动态环境中(如3D开放世界和大型PvP游戏),现有方法在从冗余传感器流中提取动作关键信号方面仍然效率低下。为了解决这个问题,我们提出了MAIN-VLA框架,它显式地建模意图和环境的抽象,从而将决策建立在深度语义对齐而非表面模式匹配的基础上。具体来说,我们的意图抽象(IA)将冗长的语言指令及其相关推理提取为紧凑、显式的语义原语,而环境语义抽象(ESA)将大量的视觉流投影为结构化的拓扑可供性表示。此外,对齐这两种抽象模态会产生一种新兴的注意力集中效应,从而实现一种无需参数的token剪枝策略,该策略可以在不降低性能的情况下过滤掉感知冗余。在开放世界Minecraft和大型PvP环境(和平精英和Valorant)中的大量实验表明,MAIN-VLA建立了一个新的state-of-the-art,实现了卓越的决策质量、更强的泛化能力和前沿的推理效率。
🔬 方法详解
问题定义:现有VLA模型在处理复杂、动态环境(如开放世界游戏和大型多人在线对战游戏)时,面临着从大量冗余的传感器数据中提取关键动作信号的挑战。这些模型往往依赖于表面的模式匹配,而非深层的语义理解,导致决策效率低下,泛化能力不足。
核心思路:MAIN-VLA的核心思路是通过显式地建模意图和环境的抽象表示,将决策过程建立在深度语义对齐的基础上。通过将复杂的语言指令和视觉信息分别抽象成紧凑的语义原语和结构化的可供性表示,模型可以更有效地关注关键信息,从而提高决策质量和效率。
技术框架:MAIN-VLA框架包含两个主要模块:意图抽象(IA)和环境语义抽象(ESA)。IA模块负责将冗长的语言指令及其相关推理提取为紧凑、显式的语义原语。ESA模块负责将大量的视觉流投影为结构化的拓扑可供性表示。这两个模块的输出被对齐,从而引导模型关注关键信息。此外,框架还包含一个基于注意力集中效应的token剪枝策略,用于过滤掉感知冗余。
关键创新:MAIN-VLA的关键创新在于显式地建模了意图和环境的抽象表示,并将决策过程建立在深度语义对齐的基础上。这种方法与现有方法依赖于表面模式匹配的策略有着本质的区别。通过抽象和对齐,模型可以更有效地关注关键信息,从而提高决策质量和效率。此外,参数无关的token剪枝策略也是一个创新点,它可以在不降低性能的情况下过滤掉感知冗余。
关键设计:意图抽象模块的具体实现细节(例如,使用的语言模型、语义原语的定义等)未知。环境语义抽象模块的具体实现细节(例如,使用的视觉特征提取器、拓扑结构的构建方法等)未知。损失函数的设计以及如何实现意图和环境抽象的对齐也未知。token剪枝策略的具体实现细节也未知。
🖼️ 关键图片


📊 实验亮点
MAIN-VLA在开放世界Minecraft和大型PvP环境(和平精英和Valorant)中进行了广泛的实验,结果表明,MAIN-VLA在决策质量、泛化能力和推理效率方面均优于现有方法,取得了state-of-the-art的性能。具体的性能提升数据未知,但论文强调了其在复杂环境中的优越性。
🎯 应用场景
MAIN-VLA具有广泛的应用前景,可应用于机器人导航、自动驾驶、游戏AI等领域。该研究能够提升智能体在复杂、动态环境中进行决策的能力,使其能够更好地理解环境和人类指令,从而实现更智能、更高效的交互。未来,该技术有望应用于更广泛的实际场景,例如智能家居、工业自动化等。
📄 摘要(原文)
Despite significant progress in Visual-Language-Action (VLA), in highly complex and dynamic environments that involve real-time unpredictable interactions (such as 3D open worlds and large-scale PvP games), existing approaches remain inefficient at extracting action-critical signals from redundant sensor streams. To tackle this, we introduce MAIN-VLA, a framework that explicitly Models the Abstraction of Intention and eNvironment to ground decision-making in deep semantic alignment rather than superficial pattern matching. Specifically, our Intention Abstraction (IA) extracts verbose linguistic instructions and their associated reasoning into compact, explicit semantic primitives, while the Environment Semantics Abstraction (ESA) projects overwhelming visual streams into a structured, topological affordance representation. Furthermore, aligning these two abstract modalities induces an emergent attention-concentration effect, enabling a parameter-free token-pruning strategy that filters out perceptual redundancy without degrading performance. Extensive experiments in open-world Minecraft and large-scale PvP environments (Game for Peace and Valorant) demonstrate that MAIN-VLA sets a new state-of-the-art, which achieves superior decision quality, stronger generalization, and cutting-edge inference efficiency.