Vision-DeepResearch Benchmark: Rethinking Visual and Textual Search for Multimodal Large Language Models
作者: Yu Zeng, Wenxuan Huang, Zhen Fang, Shuang Chen, Yufan Shen, Yishuo Cai, Xiaoman Wang, Zhenfei Yin, Lin Chen, Zehui Chen, Shiting Huang, Yiming Zhao, Yao Hu, Philip Torr, Wanli Ouyang, Shaosheng Cao
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2026-02-02
🔗 代码/项目: GITHUB
💡 一句话要点
提出VDR-Bench基准,评估多模态大语言模型在视觉文本搜索中的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉问答 视觉搜索 文本搜索 基准测试
📋 核心要点
- 现有VQA基准在评估MLLM的视觉搜索能力时存在不足,容易通过文本线索或先验知识获得答案。
- 论文提出VDR-Bench基准,通过精心设计的问题和专家审核,更真实地评估MLLM的视觉文本搜索能力。
- 论文提出多轮裁剪搜索工作流程,提升MLLM在真实视觉检索场景下的性能,并提供设计指导。
📝 摘要(中文)
多模态大语言模型(MLLM)在VQA方面取得了进展,并支持使用搜索引擎进行复杂视觉文本事实查找的Vision-DeepResearch系统。然而,评估这些视觉和文本搜索能力仍然很困难,现有的基准存在两个主要限制。首先,现有基准不是以视觉搜索为中心:本应需要视觉搜索的答案通常通过文本问题中的交叉文本线索泄露,或者可以从当前MLLM中的先验世界知识中推断出来。其次,评估场景过于理想化:在图像搜索方面,所需信息通常可以通过与完整图像的近乎精确匹配获得,而文本搜索方面过于直接且不够具有挑战性。为了解决这些问题,我们构建了包含2000个VQA实例的Vision-DeepResearch基准(VDR-Bench)。所有问题都通过仔细的多阶段管理流程和严格的专家审查创建,旨在评估Vision-DeepResearch系统在真实世界条件下的行为。此外,为了解决当前MLLM视觉检索能力不足的问题,我们提出了一种简单的多轮裁剪搜索工作流程。该策略被证明可以有效提高模型在真实视觉检索场景中的性能。总的来说,我们的结果为未来多模态深度研究系统的设计提供了实践指导。代码将在https://github.com/Osilly/Vision-DeepResearch中发布。
🔬 方法详解
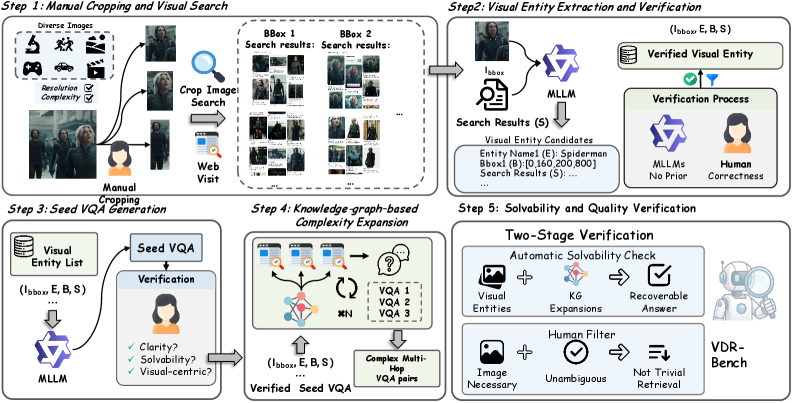
问题定义:现有视觉问答(VQA)基准在评估多模态大语言模型(MLLM)的视觉和文本搜索能力时存在局限性。具体来说,现有基准的问题设计容易泄露答案,要么通过问题中的文本线索,要么通过模型已有的世界知识,导致无法真实评估模型的视觉搜索能力。此外,图像搜索过于简单,文本搜索挑战性不足。
核心思路:为了解决上述问题,论文的核心思路是构建一个更具挑战性和真实性的VQA基准,即VDR-Bench。该基准通过精心设计的问题生成流程和严格的专家审核,确保问题需要通过视觉和文本搜索才能回答,并且避免了信息泄露。同时,论文还提出了一种多轮裁剪搜索策略,以提升模型在真实视觉检索场景下的性能。
技术框架:VDR-Bench基准的构建流程包括多个阶段,包括问题生成、答案标注和专家审核。问题生成阶段旨在创建需要视觉和文本搜索才能回答的问题,避免依赖文本线索或先验知识。答案标注阶段为每个问题提供正确的答案。专家审核阶段由领域专家对问题和答案进行审核,确保其质量和准确性。此外,论文提出的多轮裁剪搜索工作流程包括:首先,使用原始图像进行搜索;然后,根据搜索结果,裁剪图像中的相关区域;最后,使用裁剪后的图像进行进一步的搜索。
关键创新:该论文的关键创新点在于:1) 构建了一个更具挑战性和真实性的VQA基准VDR-Bench,能够更准确地评估MLLM的视觉和文本搜索能力。2) 提出了一种多轮裁剪搜索策略,能够有效提升模型在真实视觉检索场景下的性能。与现有方法相比,VDR-Bench更注重评估模型的真实视觉搜索能力,避免了信息泄露,而多轮裁剪搜索策略则能够更好地利用图像中的局部信息,提升搜索精度。
关键设计:VDR-Bench基准包含2000个VQA实例。问题生成流程包括多个阶段,例如,首先确定一个视觉对象,然后围绕该对象设计问题,确保问题需要通过视觉和文本搜索才能回答。多轮裁剪搜索策略的关键在于确定裁剪区域的大小和位置,论文中可能采用了启发式方法或学习方法来确定这些参数(具体细节未知)。损失函数和网络结构方面,论文可能使用了标准的VQA损失函数和现有的MLLM架构(具体细节未知)。
🖼️ 关键图片


📊 实验亮点
论文构建了包含2000个VQA实例的VDR-Bench基准,并提出了一种多轮裁剪搜索工作流程。实验结果表明,该工作流程能够有效提高模型在真实视觉检索场景中的性能。具体性能数据和对比基线未知,但该研究为未来多模态深度研究系统的设计提供了实践指导。
🎯 应用场景
该研究成果可应用于智能搜索、智能问答、机器人导航等领域。例如,在智能搜索中,可以利用MLLM和VDR-Bench来提升搜索结果的准确性和相关性。在机器人导航中,可以利用MLLM和多轮裁剪搜索策略来帮助机器人更好地理解周围环境,并做出正确的决策。该研究的未来影响在于推动多模态大语言模型在实际应用中的发展。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have advanced VQA and now support Vision-DeepResearch systems that use search engines for complex visual-textual fact-finding. However, evaluating these visual and textual search abilities is still difficult, and existing benchmarks have two major limitations. First, existing benchmarks are not visual search-centric: answers that should require visual search are often leaked through cross-textual cues in the text questions or can be inferred from the prior world knowledge in current MLLMs. Second, overly idealized evaluation scenario: On the image-search side, the required information can often be obtained via near-exact matching against the full image, while the text-search side is overly direct and insufficiently challenging. To address these issues, we construct the Vision-DeepResearch benchmark (VDR-Bench) comprising 2,000 VQA instances. All questions are created via a careful, multi-stage curation pipeline and rigorous expert review, designed to assess the behavior of Vision-DeepResearch systems under realistic real-world conditions. Moreover, to address the insufficient visual retrieval capabilities of current MLLMs, we propose a simple multi-round cropped-search workflow. This strategy is shown to effectively improve model performance in realistic visual retrieval scenarios. Overall, our results provide practical guidance for the design of future multimodal deep-research systems. The code will be released in https://github.com/Osilly/Vision-DeepResearch.